お疲れ様です!IT業界で働くアライグマです!
「月末にAWSの請求書を見たら、予想の10倍の金額になっていて顔面蒼白になった」
「とりあえずPythonでループ処理を書いたら、Lambdaのタイムアウトと課金で死にかけた」
クラウドネイティブな開発が当たり前になった今、こんな怖い経験をしているエンジニアは少なくありません。
特にデータ処理系では、コードの書き方一つで、クラウド破産するか、激安で運用できるかが決まります。
「動けばいい」というコードは、クラウド時代では「負債」どころか「損失」そのものです。
本記事では、Pythonを使ったデータ処理において、AWS(Athena・Lambda)のコストを劇的に削減するための具体的なテクニックを、コードレベルで解説します。
コストが膨らむ「やってはいけない」アンチパターン
まずは、コスト爆増を招く典型的なアンチパターンを知っておきましょう。
Athenaでのフルスキャン地獄
Athenaは「スキャンしたデータ量」に対して課金されます($5.00/TB)。
以下のようなクエリコードは危険です。
# 危険:パーティション指定なしで全件取得してからPythonでフィルタ
query = "SELECT * FROM large_access_logs"
df = pd.read_sql(query, connection)
target_df = df[df['date'] == '2026-01-15'] # ここで絞り込んでも手遅れPython側でフィルタリングする前に、Athena側で全データを読み込んでしまっているため、莫大な課金が発生します。
Lambdaでのメモリ無駄遣いとループ処理
Lambdaは「メモリ量 × 実行時間」で課金されます。
巨大なリストを全てメモリに展開してからループ処理を行うと、メモリ料金が跳ね上がり、さらに処理時間も伸びて二重のコスト増になります。
また、開発効率化については、マルチLLM並列実行環境の構築も参考になります。
 IT女子 アラ美
IT女子 アラ美Athenaのスキャン量をPythonで制御する
Athenaのコスト削減の基本は「パーティション」の活用ですが、Pythonスクリプトから実行する場合、動的にパーティションを絞り込む工夫が必要です。
悪い例:f-stringで日付範囲を適当に指定
# 範囲指定してもフルスキャンになる可能性がある(パーティション設定依存)
query = f"SELECT * FROM logs WHERE date >= '{start_date}'"良い例:boto3でパーティション存在確認をしてからクエリ
S3上のパスを事前に計算し、対象パーティションだけを明示的に指定します。
import boto3
def build_partition_query(bucket, prefix, date_list):
s3 = boto3.client('s3')
target_dates = []
# S3に実際にデータがある日付だけをリスト化
for date in date_list:
year, month, day = date.split('-')
response = s3.list_objects_v2(
Bucket=bucket,
Prefix=f"{prefix}/year={year}/month={month}/day={day}/",
MaxKeys=1
)
if 'Contents' in response:
target_dates.append(date)
# データがある日付だけをIN句で指定
date_str = "', '".join(target_dates)
return f"SELECT * FROM logs WHERE date_col IN ('{date_str}')"この「事前チェック(Pre-check)」を入れることで、空振りクエリや無駄なスキャンを完全に防げます。
データ処理の最適化については、PostGISのインデックスとANALYZEガイドもデータベース視点で参考になります。
IT女子 アラ美Lambdaの計算リソースを節約するPythonテクニック
Lambdaでは「メモリ使用量」がコストに直結します。大量データを処理する際は、メモリに載せきらない工夫が必要です。
Generator(ジェネレータ)の活用
リスト(List)の代わりにジェネレータ(Generator)を使うことで、メモリ使用量を一定に保てます。
# 悪い例:全データをメモリに格納
def fetch_all_data():
return [process(item) for item in large_dataset] # メモリ爆発
# 良い例:yieldを使って1件ずつ渡す
def yield_data():
for item in large_dataset:
yield process(item) # メモリ使用量は1件分のみ
for result in yield_data():
save_to_db(result)Pandasのchunksize活用
Pandasで大きなCSVを扱う場合も、chunksizeを指定して少しずつ処理します。
import pandas as pd
# 1GBのCSVでも、1万行ずつ処理すれば小メモリLambdaで動く
for chunk in pd.read_csv('s3://my-bucket/large.csv', chunksize=10000):
process_chunk(chunk)自動化フローとセキュリティについては、GitHub ActionsのCI/CDセキュリティガイドも参考になります。
IT女子 アラ美ケーススタディ:月額5,000ドルを200ドルに削減した事例
実際に、あるデータ分析基盤でコスト削減を行った事例を紹介します。
状況(Before)
アクセスログ分析用のバッチ処理が、AWSコストの大部分を占めていました。
- 対象システム:日次ログ分析バッチ(AWS Lambda + Athena)
- コスト:月額約5,000ドル(約75万円)… Athenaのスキャン料が9割
- 課題:過去データの再集計時に、変更がないデータまで毎回フルスキャンしていた
行動(Action)
以下の3つの施策をPythonスクリプトに実装しました。
- S3 ETagチェックによるスキップ:
入力ファイルのETag(ハッシュ値)をDynamoDBに保存し、変更がない場合は処理自体をスキップ。 - パーティション・プルーニングの徹底:
Athenaクエリ発行前に「処理が必要な日付」を計算し、WHERE句で厳密に指定。 - 中間データのParquet化:
CSVではなく列指向のParquet形式で保存し、必要な列だけを読み込むように変更。
結果(After)
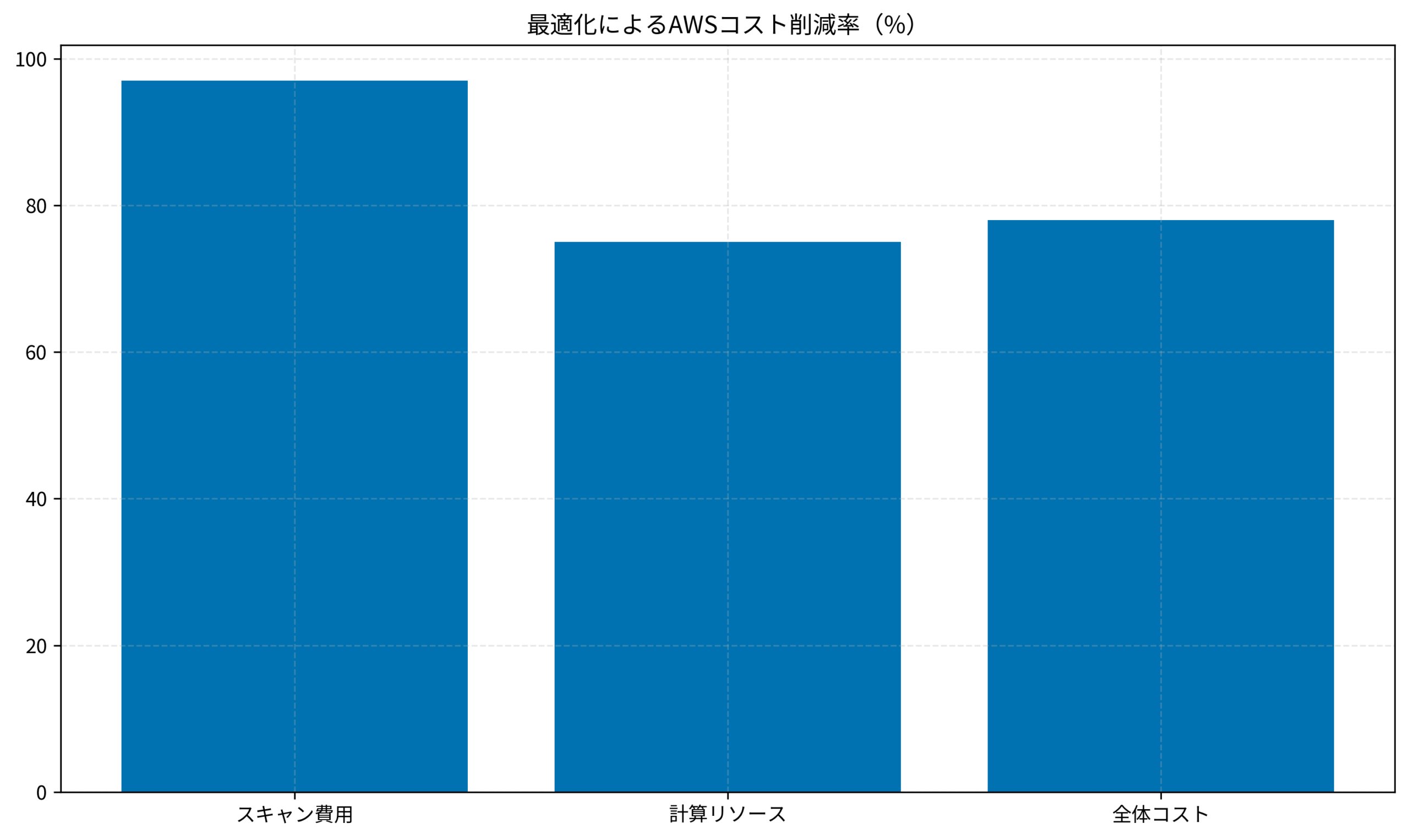
- コスト:月額200ドル(約3万円)に激減(削減率96%)
- 実行時間:1時間かかっていた処理が5分で完了
- 副次効果:エラー時の再実行が高速になり、運用負荷も軽減
エンジニアとしての市場価値向上については、エンジニアのキャリア志向別エージェント選びも参考になります。
IT女子 アラ美キャリアアップのための次のステップ
コスト意識の高いエンジニアは市場価値が高く、ハイクラス転職でも有利です。
自分のスキルに見合った待遇を得るために、以下のサービスを活用して市場価値を確かめてみてください。
キャリア戦略については、上流工程へのシフト戦略も参考になります。
さらなる年収アップやキャリアアップを目指すなら、ハイクラス向けの求人に特化した以下のサービスがおすすめです。
| 比較項目 | TechGo | レバテックダイレクト | ビズリーチ |
|---|---|---|---|
| 年収レンジ | 800万〜1,500万円ハイクラス特化 | 600万〜1,000万円IT専門スカウト | 700万〜2,000万円全業界・管理職含む |
| 技術スタック | モダン環境中心 | Web系に強い | 企業によりバラバラ |
| リモート率 | フルリモート前提多数 | 条件検索可能 | 原則出社も多い |
| おすすめ度 | 技術で稼ぐならここ | A受身で探すなら | Bマネジメント層向け |
| 公式サイト | 無料登録する | - | - |
IT女子 アラ美まとめ
PythonでのAWSデータ処理におけるコスト削減ポイントを整理します。
- Athenaはスキャン量が命:Python側で事前チェックし、必要なパーティションだけを叩く
- Lambdaはメモリ効率:リストよりジェネレータ、一括よりチャンク処理で小メモリ運用
- 処理のスキップ判定:S3 ETagなどを活用し、変更がないデータは触らない
クラウドの従量課金は、コードの品質がダイレクトに請求額に反映されるシビアな世界です。
しかし、適切な最適化を行えば、オンプレミスでは考えられない低コストで大規模データを処理できます。
ぜひ今回のテクニックを取り入れて、”お財布に優しい” Pythonコードを書いてみてください。
IT女子 アラ美