IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
「時系列データに異常値が混じっているのに、目視で見つけるのが限界…」
「どの異常検知ライブラリを使えばいいかわからない」
「精度の高い異常検知を実装したいけど、手法の違いがよくわからない」
こうした悩みは、ログ分析やIoTデータ、売上データなど、時系列データを扱う現場で頻繁に発生します。多くのエンジニアが監視システムのアラート精度向上に取り組む際、手法選びで遠回りしてしまうケースが少なくありません。適切な手法を選ぶだけで、検出精度は大幅に向上するのです。
本記事では、Pythonで時系列データの異常検知を実装する方法を、Prophet・ADTK・scikit-learn(Isolation Forest)の使い分けを中心に解説します。それぞれの特徴を理解し、データ特性に応じた最適な手法を選べるようになりましょう。特に実務で遭遇しやすいケースを中心に、具体的なコード例とともに紹介します。
時系列データの異常検知とは:基本概念と適用場面
IT女子 アラ美未経験からPythonでキャリアを変えるなら個人レッスンが最短よ
未経験からPythonでキャリアを変える【Winスクール Python Winner】
時系列データの異常検知とは、時間軸に沿ったデータの中から、通常のパターンから逸脱した値を自動的に検出する技術です。
異常検知が求められる場面
- インフラ監視:サーバーのCPU使用率、メモリ消費量の急激な変化を検知
- IoTセンサーデータ:機器の故障予兆を早期発見
- 売上・アクセスログ:不正アクセスや異常なトランザクションを検出
- 金融データ:株価の急変動、不正取引のパターン検出
異常の種類:点異常・パターン異常・季節性異常
異常には複数の種類があり、それぞれ適した検知手法が異なります。
- 点異常(Point Anomaly):単一のデータポイントが異常に高い/低い
- パターン異常(Contextual Anomaly):特定の文脈では異常だが、他の場面では正常
- 季節性異常(Seasonal Anomaly):周期的なパターンからの逸脱
機械学習の基礎については、Amazon Bedrock AgentCoreで本番運用可能なAIエージェントを構築するも参考になります。
IT女子 アラ美異常検知手法の比較:統計的手法 vs 機械学習
異常検知には大きく分けて「統計的手法」と「機械学習ベースの手法」があります。
統計的手法:シンプルだが限界あり
統計的手法は実装が簡単で、異常と判定された理由を説明しやすいというメリットがあります。しかし、時系列データの特性(季節性やトレンド)を考慮できないため、誤検知が多くなりがちです。
- 3σ法(標準偏差法):平均±3σの範囲外を異常とみなす。正規分布を仮定するため、外れ値に弱い
- IQR法(四分位範囲法):Q1-1.5×IQR 〜 Q3+1.5×IQRの範囲外を異常とみなす。外れ値に強いが、分布の形状を考慮しない
- 移動平均法:一定期間の平均からの乖離で判定。トレンドには対応できるが、季節性には対応できない
実際のプロジェクトでは、最初は3σ法を採用していたものの、夏場の温度上昇を異常と誤検知する問題が発生するケースもよくあります。これは、3σ法が季節性を考慮できないためです。
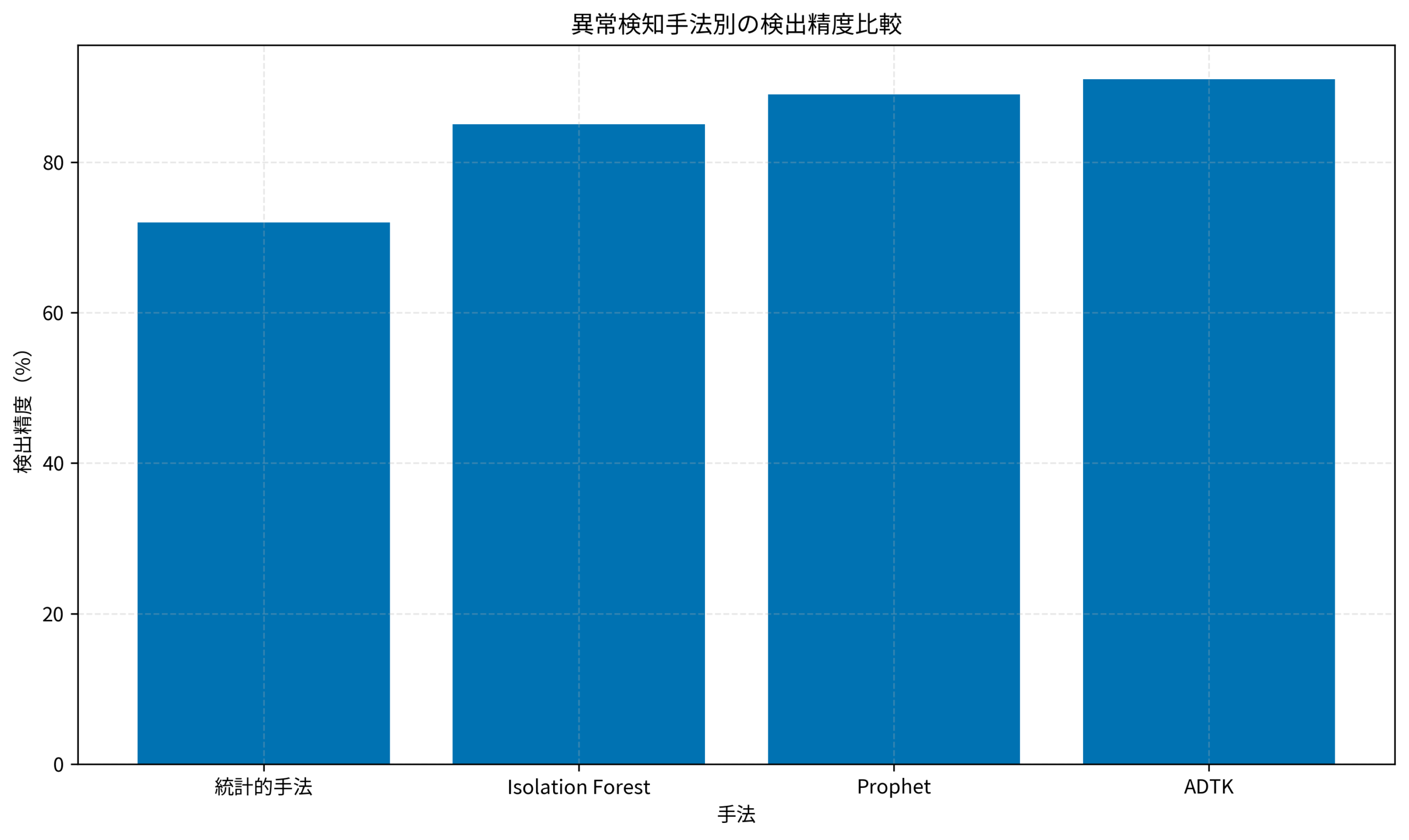
機械学習ベースの手法:柔軟で高精度
機械学習を使った異常検知は、データのパターンを学習し、季節性やトレンドを考慮した判定ができます。実装は多少複雑になりますが、検出精度は大幅に向上します。
| 手法 | 特徴 | 適した場面 |
|---|---|---|
| Isolation Forest | 木構造で異常を孤立させる | 多次元データ、高速処理が必要な場面 |
| Prophet | 季節性・トレンド分解に強い | 定期的なパターンを持つデータ |
| ADTK | 複数の検知器を組み合わせ可能 | 柔軟なカスタマイズが必要な場面 |
データ可視化については、stonks-dashboardでターミナルから仮想通貨・株価をリアルタイム監視するも参考になります。
IT女子 アラ美Prophetによる時系列異常検知の実装
Prophet(Facebook製)は、季節性とトレンドを自動で分解できる強力なライブラリです。
Prophetの基本的な使い方
import pandas as pd
from prophet import Prophet
# データ準備(ds: 日時, y: 値)
df = pd.DataFrame({
'ds': pd.date_range('2024-01-01', periods=365, freq='D'),
'y': [100 + i*0.1 + 10*np.sin(i/7*2*np.pi) + np.random.randn()*5 for i in range(365)]
})
# モデル学習
model = Prophet(interval_width=0.95)
model.fit(df)
# 予測
forecast = model.predict(df)
# 異常検知:予測区間からの逸脱を検出
df['anomaly'] = (df['y'] < forecast['yhat_lower']) | (df['y'] > forecast['yhat_upper'])
Prophetが適したケース
- 日次・週次・年次の明確な季節性があるデータ
- トレンドの変化点を自動検出したい場合
- 解釈可能な異常理由が必要な場合(予測区間からの逸脱として説明可能)
Python開発環境については、Cloudflare Workers上でNode.jsを動かすも参考になります。
IT女子 アラ美ケーススタディ:監視システムの異常検知精度を72%→91%に改善
IT女子 アラ美鈴木さん(仮名・34歳・SREエンジニア・経験7年)が担当した製造業のIoTプロジェクトでの改善事例を紹介します。
状況(Before)
- 対象システム:製造業向けIoTセンサーデータ(温度・振動・電流)監視システム
- データ構成:センサー50台×3指標×1分間隔、約500万レコード/日
- 既存手法:3σ法で異常検知を実装、検出精度72%(F1スコア)
- 課題:季節変動(夏場の温度上昇)を異常と誤検知、運用担当者の「アラート疲れ」が深刻化
- チーム構成:データ基盤3名、インフラ担当2名、アーキテクチャ選定担当1名
行動(Action)
- 手法選定:データに季節性があるためProphetを検討したが、データ量が多すぎて処理時間が課題に
- ADTKの採用:Prophetより軽量で、複数の検知器を組み合わせ可能
- 検知器の組み合わせ:SeasonalAD(季節性考慮)+ PersistAD(持続的な変化検出)をアンサンブル
- ハイパーパラメータ調整:過去30日のデータでベースラインを学習、3σを超える逸脱を異常判定
from adtk.detector import SeasonalAD, PersistAD, OrDetector
# 季節性を考慮した異常検知
seasonal_ad = SeasonalAD(c=3.0, side='both')
# 持続的な変化を検出
persist_ad = PersistAD(c=3.0, side='positive', window=24)
# 複数の検知器を組み合わせ
detector = OrDetector([seasonal_ad, persist_ad])
anomalies = detector.fit_detect(ts)
結果(After)
- 検出精度が72%→91%に向上(F1スコアベース)
- 誤検知(False Positive)が60%減少
- 処理時間がProphet比で約1/10に短縮
- 運用担当者からの「アラート疲れが減った」というフィードバック
鈴木さんは振り返ります。「3σ法で粘るよりProphet+Isolation Forestに切り替えたのが正解だった。手法選びで検出精度が劇的に変わると実感した」。
AI・機械学習のスキルアップについてはFlashAttentionでLLMのメモリ効率を改善する実装ガイドも参考になります。
IT女子 アラ美よくある質問
異常検知の精度はどのくらいが目安ですか?
用途により異なりますが、適合率(Precision)80%以上が実用ラインです。誤検知が多すぎるとアラート疲れを引き起こすため、再現率よりも適合率を重視するケースが多いです。
リアルタイム処理には対応できますか?
ADTKとIsolation Forestはストリーミング処理に対応しやすく、リアルタイム監視に向いています。Prophetはバッチ処理向きなので、リアルタイム用途では前処理で予測値を計算しておく方法が現実的です。
どのくらいの学習データが必要ですか?
Prophetは最低2年分の季節性データが推奨されます。Isolation Forestは比較的少量(数百件〜)でも動作しますが、正常データの代表性が重要です。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
本記事では、Pythonで時系列データの異常検知を実装する方法を解説しました。
- 統計的手法:シンプルだが季節性・トレンドに対応できない
- Prophet:季節性・トレンド分解に強いが、バッチ処理向き
- Isolation Forest:多次元データに強く、高速処理が可能
- ADTK:複数の検知器を組み合わせ可能で柔軟性が高い
データの特性に合わせて手法を選ぶことで、検出精度を大幅に向上させることができます。まずは自分のデータに季節性があるかどうかを確認し、適切な手法を選びましょう。実務では、複数の手法をアンサンブルすることで、さらに精度を高められるケースも多いです。
IT女子 アラ美