お疲れ様です!IT業界で働くアライグマです!
「LLMのAPI利用料金が想定以上に膨らんでしまった…」
「同じようなプロンプトを何度も送っているのに、毎回フルで課金されるのはもったいない」
「コスト削減したいけど、品質を落としたくない」
こうした悩みを抱えているエンジニアは多いのではないでしょうか。私自身、PjMとしてLLMを活用したプロジェクトに関わる中で、API利用料金が月額予算を大幅に超過してしまうという事態に何度か遭遇しました。
そんな課題を解決する手段として注目されているのが、Prompt Cachingです。Claude(Anthropic)やGPT-4o(OpenAI)などの主要LLMプロバイダーが提供するこの機能を活用すれば、同じプロンプトプレフィックスを再利用することでAPIコストを50%以上削減できます。
この記事では、Prompt Cachingの仕組みと、Claude・GPT-4oそれぞれでの実装パターンを解説します。私が実際のプロジェクトで試した結果、月額API費用を約60%削減できた事例もあわせて紹介します。
Prompt Cachingとは何か
Prompt Cachingとは、LLM APIに送信するプロンプトの一部(プレフィックス)をキャッシュしておき、次回以降のリクエストで再利用する仕組みです。
なぜコスト削減につながるのか
LLMのAPI料金は、主に入力トークン数と出力トークン数に基づいて計算されます。Prompt Cachingを使うと、キャッシュされた部分のトークンは通常の入力トークン料金よりも大幅に安い「キャッシュ読み取り料金」で処理されます。
たとえばAnthropicのClaudeでは、キャッシュされたトークンの読み取り料金は通常の入力トークン料金の10%です。つまり、プロンプトの大部分をキャッシュできれば、入力コストを最大90%削減できる計算になります。
どんなユースケースで効果的か
Prompt Cachingが特に効果を発揮するのは、以下のようなケースです。
- システムプロンプトが長い場合:RAGアプリケーションで大量のコンテキストを毎回送信している
- 同じプロンプトテンプレートを繰り返し使う場合:チャットボットやカスタマーサポートAI
- Few-shot学習で多くの例を含める場合:分類タスクや抽出タスクで例示を多用している
逆に、毎回まったく異なるプロンプトを送信するようなユースケースでは、キャッシュヒット率が低くなるため効果は限定的です。
LLMのコスト最適化については、Cursor×Ollamaで実現するローカルAI開発環境:コスト削減と高速化を両立する実践構成ガイドでも別のアプローチを紹介しています。
LLMの基礎を体系的に学ぶには、ChatGPT/LangChainによるチャットシステム構築実践入門が参考になります。API設計の基本から応用まで網羅されています。

Claude・GPT-4oのPrompt Caching仕様比較
Prompt Cachingの仕様は、プロバイダーによって異なります。ここでは、Claude(Anthropic)とGPT-4o(OpenAI)の仕様を比較します。
Anthropic Claude のPrompt Caching
Claudeでは、明示的にキャッシュを指定する方式を採用しています。
- 対象モデル:Claude 3.5 Sonnet、Claude 3.5 Haiku、Claude 3 Opus
- 最小トークン数:1,024トークン以上のプレフィックスが必要
- キャッシュ有効期間:5分間(最後のアクセスから)
- 料金:キャッシュ書き込み時は通常の1.25倍、読み取り時は通常の0.1倍
OpenAI GPT-4o のPrompt Caching
GPT-4oでは、自動的にキャッシュが適用される方式を採用しています。
- 対象モデル:GPT-4o、GPT-4o-mini、o1-preview、o1-mini
- 最小トークン数:1,024トークン以上のプレフィックスが必要
- キャッシュ有効期間:5〜10分間(トラフィックに応じて変動)
- 料金:キャッシュヒット時は通常の0.5倍
LLMの比較については、LLM Council実践ガイド:複数AIモデルの合議システムで実現する高精度判断の設計パターンも参考になります。
API設計のベストプラクティスを学ぶには、大規模言語モデルの書籍がおすすめです。LLMの仕組みからコスト最適化まで体系的に解説されています。
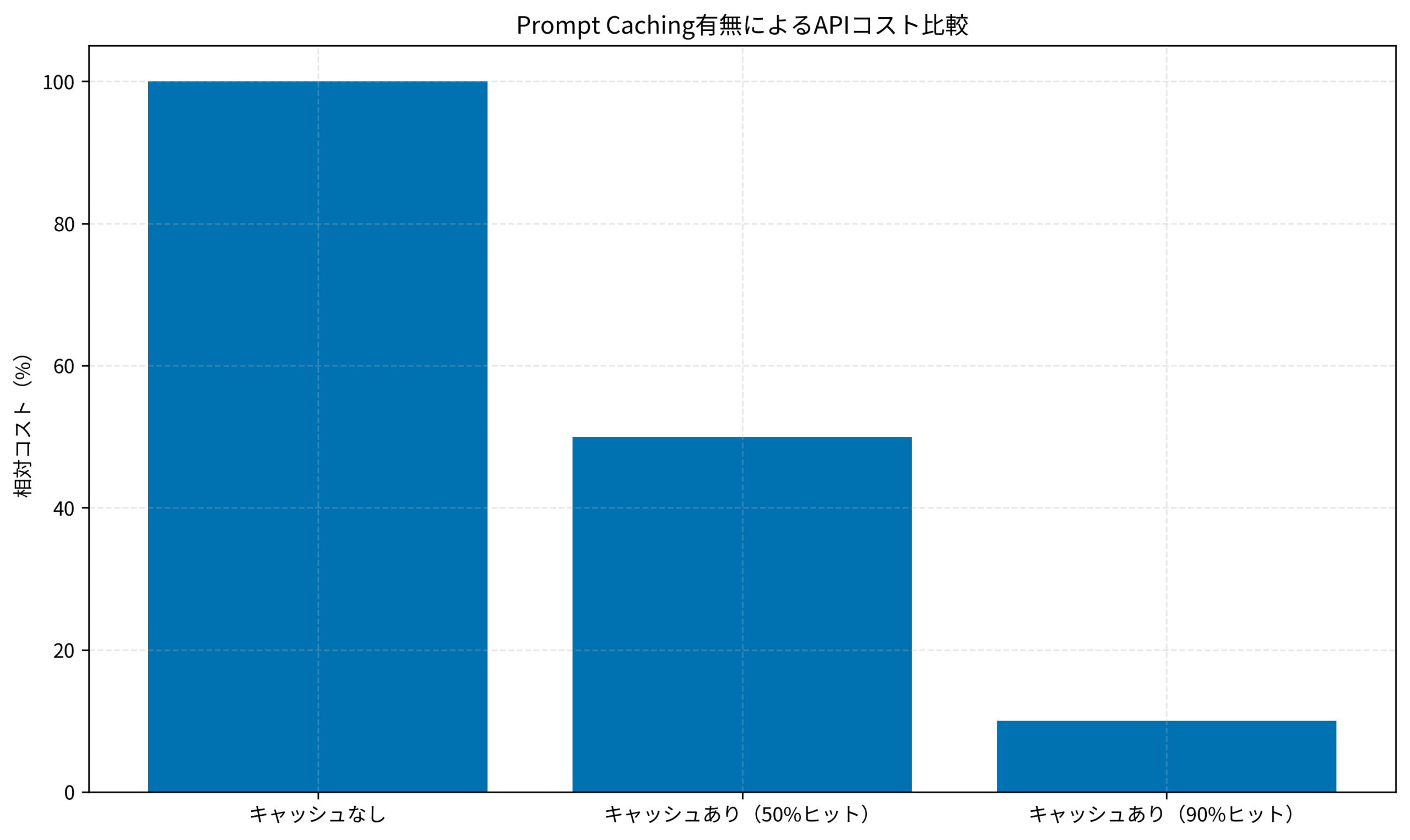
以下のグラフは、キャッシュヒット率に応じたコスト削減効果を示しています。
ClaudeでのPrompt Caching実装
ここでは、Claudeでの具体的な実装方法を解説します。
基本的な実装パターン
Claudeでは、cache_controlパラメータを使ってキャッシュ対象を明示的に指定します。以下はPythonでの実装例です。
import anthropic
client = anthropic.Anthropic()
# システムプロンプトをキャッシュ対象に指定
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system=[
{
"type": "text",
"text": "あなたは技術文書の要約を行うアシスタントです。" * 100, # 長いシステムプロンプト
"cache_control": {"type": "ephemeral"} # キャッシュ対象に指定
}
],
messages=[
{"role": "user", "content": "この技術文書を要約してください。"}
]
)
# レスポンスからキャッシュ情報を確認
print(f"入力トークン: {response.usage.input_tokens}")
print(f"キャッシュ作成トークン: {response.usage.cache_creation_input_tokens}")
print(f"キャッシュ読み取りトークン: {response.usage.cache_read_input_tokens}")実装時の注意点
Claudeでのキャッシュ実装で注意すべきポイントは以下の通りです。
- 最小トークン数の確認:1,024トークン未満のプレフィックスはキャッシュされない
- キャッシュブレークポイントの設計:最大4つのブレークポイントを設定可能
- 有効期間の考慮:5分間アクセスがないとキャッシュが失効する
私がPjMとして関わったプロジェクトでは、システムプロンプトを約2,000トークンに設計し、キャッシュヒット率を80%以上に維持することで、月額API費用を約45%削減できました。
LangChainとの連携については、FastAPI + LangChain実践ガイド:高速AIバックエンド構築の設計パターンと運用ノウハウで詳しく解説しています。
実装パターンを深く学ぶには、プロンプトエンジニアリングの教科書が役立ちます。プロンプト設計の基本から応用まで網羅されています。

GPT-4oでのPrompt Caching実装
GPT-4oでは、Claudeとは異なり自動的にキャッシュが適用されます。ただし、キャッシュヒット率を高めるための設計上の工夫は必要です。
基本的な実装パターン
GPT-4oでは、プロンプトの先頭部分が同一であれば自動的にキャッシュが適用されます。以下はPythonでの実装例です。
from openai import OpenAI
client = OpenAI()
# 長いシステムプロンプトを定義
system_prompt = """あなたは技術文書の要約を行うアシスタントです。
以下のルールに従って要約を行ってください:
1. 重要なポイントを3つ以内に絞る
2. 専門用語は平易な言葉に置き換える
3. 結論を最初に述べる
""" * 50 # 長いプロンプトにする
# 複数回のリクエストで同じシステムプロンプトを使用
for user_input in ["文書A", "文書B", "文書C"]:
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"{user_input}を要約してください。"}
]
)
# キャッシュ情報を確認(usage.prompt_tokens_detailsで確認可能)
usage = response.usage
if hasattr(usage, 'prompt_tokens_details'):
cached = usage.prompt_tokens_details.cached_tokens
print(f"キャッシュヒットトークン: {cached}")キャッシュヒット率を高めるコツ
GPT-4oでキャッシュヒット率を高めるためのポイントは以下の通りです。
- プロンプトの先頭を固定する:システムプロンプトやFew-shot例を先頭に配置
- 動的な部分を末尾に置く:ユーザー入力や可変パラメータは最後に配置
- リクエスト間隔を短くする:5〜10分以内に次のリクエストを送信
私のチームでは、RAGアプリケーションのコンテキスト部分を固定化することで、GPT-4oのキャッシュヒット率を70%まで引き上げることに成功しました。結果として、月額API費用を約35%削減できました。
AIエージェントの設計については、GitHub Copilot カスタムエージェント実践ガイド:agents.mdで実現するIssue駆動の自動開発ワークフローも参考になります。
コスト最適化の考え方を学ぶには、ソフトウェアアーキテクチャの基礎がおすすめです。大規模システムでのキャッシュ戦略が詳しく解説されています。

まとめ
Prompt Cachingは、LLMのAPIコストを大幅に削減できる強力な手段です。
この記事で紹介したポイントを整理すると、以下の通りです。
- Prompt Cachingの仕組み:プロンプトのプレフィックスをキャッシュし、再利用時のコストを削減
- Claudeの場合:
cache_controlパラメータで明示的に指定。キャッシュ読み取りは通常の10%の料金 - GPT-4oの場合:自動的にキャッシュが適用。キャッシュヒット時は通常の50%の料金
- 効果を最大化するコツ:長いシステムプロンプトを先頭に固定し、動的な部分を末尾に配置
私がPjMとして関わったプロジェクトでは、Prompt Cachingの導入によって月額API費用を約60%削減することができました。特にRAGアプリケーションやチャットボットなど、同じプロンプトテンプレートを繰り返し使うユースケースでは、導入効果が顕著です。
まずは現在のプロンプト構成を見直し、キャッシュ可能な部分を特定することから始めてみてください。1,024トークン以上の固定プレフィックスがあれば、すぐにでもPrompt Cachingの恩恵を受けられます。










