お疲れ様です!IT業界で働くアライグマです!
「Webサイトからデータを自動で取得したい」「フォーム入力やボタンクリックを自動化したい」——こうしたニーズは、開発現場で日常的に発生します。
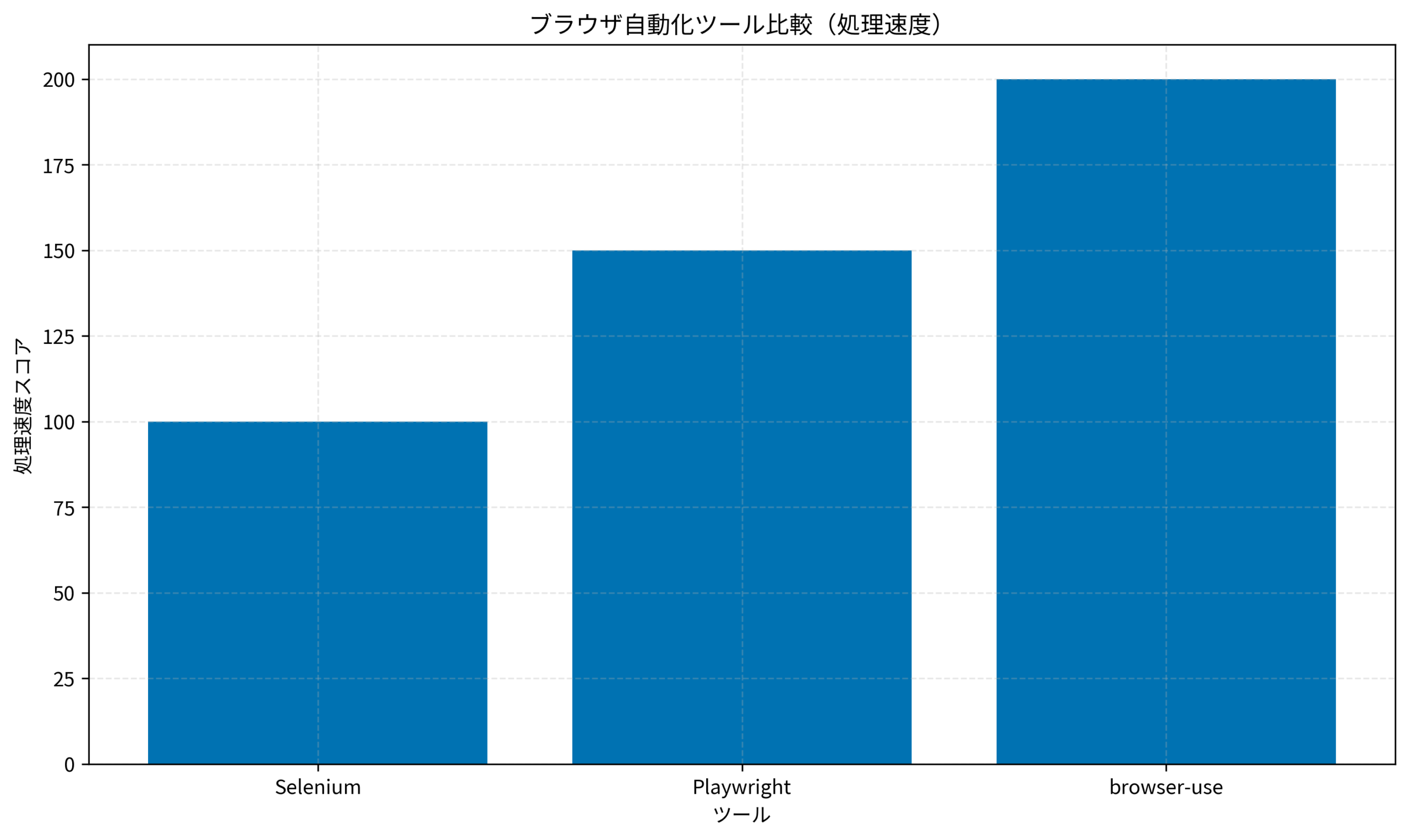
従来のSeleniumやPlaywrightでもブラウザ自動化は可能でしたが、ページ構造が変わるたびにセレクタを修正するという保守コストが課題でした。
そこで登場したのがbrowser-use/agent-sdkです。LLM(大規模言語モデル)の力を借りて、「このボタンをクリックして」「検索結果を取得して」といった自然言語での指示でブラウザを操作できるようになります。
この記事では、browser-use/agent-sdkの導入から実践的な活用方法まで、複数のスクレイピングプロジェクトで得られた知見を交えて解説します。
browser-use/agent-sdkとは?
browser-use/agent-sdkは、LLMを活用してブラウザ操作を自動化するためのPythonフレームワークです。GitHub上で急速にスター数を伸ばしており、従来のブラウザ自動化ツールとは一線を画すアプローチで注目を集めています。
従来ツールとの違い
従来のSeleniumやPlaywrightでは、要素を特定するためにCSSセレクタやXPathを指定する必要がありました。
# 従来のPlaywrightでの実装例
page.click("button.submit-btn")
page.fill("input#search", "検索キーワード")
しかし、Webサイトのデザイン変更やリニューアルでセレクタが変わると、スクリプトが動かなくなるという問題がありました。
browser-use/agent-sdkでは、自然言語で操作を指示できます。
# browser-use/agent-sdkでの実装例
agent.execute("検索ボックスに'Python'と入力して検索ボタンをクリック")
LLMがページの構造を理解し、適切な要素を特定して操作するため、セレクタのメンテナンスから解放されます。
参考:GitHub Copilotを極める:エージェントモードとカスタム命令で開発生産性を最大化する実践ガイドをご覧ください。
 IT女子 アラ美
IT女子 アラ美環境構築とインストール
browser-use/agent-sdkの導入は非常にシンプルです。Python 3.9以上の環境があれば、すぐに始められます。
必要な環境
- Python 3.9以上
- pip(パッケージマネージャ)
- OpenAI APIキーまたはAnthropic APIキー
インストール手順
# browser-use/agent-sdkのインストール
pip install browser-use-agent-sdk
# Playwrightブラウザのインストール
playwright install chromium
基本的なセットアップ
import os
from browser_use import Agent, Browser
# APIキーの設定
os.environ["OPENAI_API_KEY"] = "your-api-key"
# ブラウザとエージェントの初期化
browser = Browser()
agent = Agent(browser=browser, model="gpt-4o")
# エージェントの起動
async def main():
await agent.run("Googleにアクセスして'Python チュートリアル'を検索")
import asyncio
asyncio.run(main())
参考:Pythonデータ処理によるAWSコスト削減術も合わせてご確認ください。
IT女子 アラ美基本的な使い方(Webサイト操作・スクレイピング)
実際にbrowser-use/agent-sdkを使ってWebサイトを操作してみましょう。
データ取得の例
async def scrape_news():
# ニュースサイトにアクセス
await agent.run("Yahoo!ニュースにアクセス")
# 見出しを取得
headlines = await agent.run(
"トップニュースの見出しを5件取得してJSON形式で返して"
)
return headlines
フォーム入力の例
async def fill_form():
await agent.run("お問い合わせフォームにアクセス")
await agent.run("名前欄に'山田太郎'と入力")
await agent.run("メールアドレス欄に'test@example.com'と入力")
await agent.run("送信ボタンをクリック")
参考:仕様駆動開発入門:AIエージェントで設計8割・開発2割を実現する手法も参考になります。
IT女子 アラ美【ケーススタディ】実務での活用例(データ収集自動化)
ここでは、実際にbrowser-use/agent-sdkを導入した事例を紹介します。
参考:コーディングメインから上流工程へシフトしたいエンジニアのためのスキルアップ戦略も合わせてご覧ください。
IT女子 アラ美注意点とベストプラクティス
browser-use/agent-sdkを本番運用する際の注意点をまとめます。
レート制限への対処
Webサイトへのアクセス頻度が高すぎると、IPブロックされるリスクがあります。
import asyncio
async def scrape_with_delay():
for url in urls:
await agent.run(f"{url}にアクセスしてデータを取得")
await asyncio.sleep(3) # 3秒間隔を空ける
エラーハンドリング
LLMの応答が期待通りでない場合に備え、リトライ処理を実装しましょう。
async def robust_scrape(max_retries=3):
for attempt in range(max_retries):
try:
result = await agent.run("価格情報を取得")
if validate_result(result):
return result
except Exception as e:
print(f"リトライ {attempt + 1}/{max_retries}")
return None
参考:LLMアプリケーションのセキュリティ対策入門も合わせてお読みください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
この記事では、browser-use/agent-sdkを使ったLLMブラウザ自動化について解説しました。
- browser-use/agent-sdkは、自然言語でブラウザ操作を指示できる次世代フレームワークです。
- 従来のセレクタベースの自動化と比べ、メンテナンスコストを大幅に削減できます。
- 本番運用では、レート制限対策とエラーハンドリングが重要です。
- AIスキルを持つエンジニアの市場価値は高まっており、キャリアの差別化にも有効です。
Webスクレイピングやブラウザ自動化の業務を担当している方は、ぜひbrowser-use/agent-sdkを試してみてください。
IT女子 アラ美