お疲れ様です!IT業界で働くアライグマです!
「SELECT * って楽だし、カラムが増えても勝手についてくるから便利じゃない?」
データベースを扱うエンジニアなら、一度はこう思ったことがあるのではないでしょうか。
確かに、アドホックな分析やちょっとした確認クエリではSELECT *は手軽で便利です。
しかし、本番環境のアプリケーションコードやデータパイプラインでSELECT *を多用していると、知らぬ間にデータモデルの保守性が著しく低下するリスクがあります。
私自身、PjMとしてデータ基盤の運用に関わる中で、SELECT *が原因で発生した障害を何度か経験しました。
スキーマ変更のたびにアプリケーションが壊れる、意図しないカラムが公開されてしまう、パフォーマンスが劣化する——こうした問題は、カラム明示化というシンプルな対策で防げるものです。
この記事では、SELECT *がなぜアンチパターンとされるのか、どのような問題を引き起こすのか、そして具体的な改善策を解説します。
SELECT *が引き起こす問題の全体像
SELECT *の問題は、単に「コーディング規約で禁止されているから」という表面的な理由ではありません。
データモデルの変更に対する脆弱性と、意図しないデータ露出という2つの根本的な問題があります。
スキーマ変更時の脆弱性
データベースのテーブルにカラムが追加されたとき、SELECT *を使っているクエリは自動的にそのカラムを取得します。
一見便利に思えますが、これが問題を引き起こすケースは多々あります。
- アプリケーションの想定外のデータ:新しいカラムがNULLを含む場合、アプリケーション側でNullPointerExceptionが発生する
- データ型の不整合:新しいカラムのデータ型がアプリケーションの期待と異なる場合、型変換エラーが発生する
- カラム順序の変更:インデックスでカラムにアクセスしている場合、順序変更で誤ったデータを取得する
私がPjMとして関わったプロジェクトでは、DWHチームがディメンションテーブルに監査用のカラムを追加したところ、下流のBIダッシュボードが一斉に壊れるという事故が発生しました。
原因は、ダッシュボードのクエリがすべてSELECT *で書かれていたことでした。
意図しないデータ露出
SELECT *は、テーブルのすべてのカラムを取得します。
これは、本来公開すべきでないカラムが意図せず露出するリスクを伴います。
たとえば、ユーザーテーブルにpassword_hashやinternal_notesといったカラムが追加された場合、SELECT *を使っているAPIは自動的にこれらのデータを返してしまいます。
Polars実践ガイド:Pandasから移行して大規模データ処理を10倍高速化する設計パターンでも触れていますが、データ処理の設計では「何を取得するか」を明示的に制御することが重要です。
データベースエキスパートへの道 実践的リレーショナルデータベース設計手法でも解説されているように、データベース設計の基本原則として「必要なデータだけを取得する」という考え方があります。
SELECT *はこの原則に反するため、長期的な保守性を損なうのです。
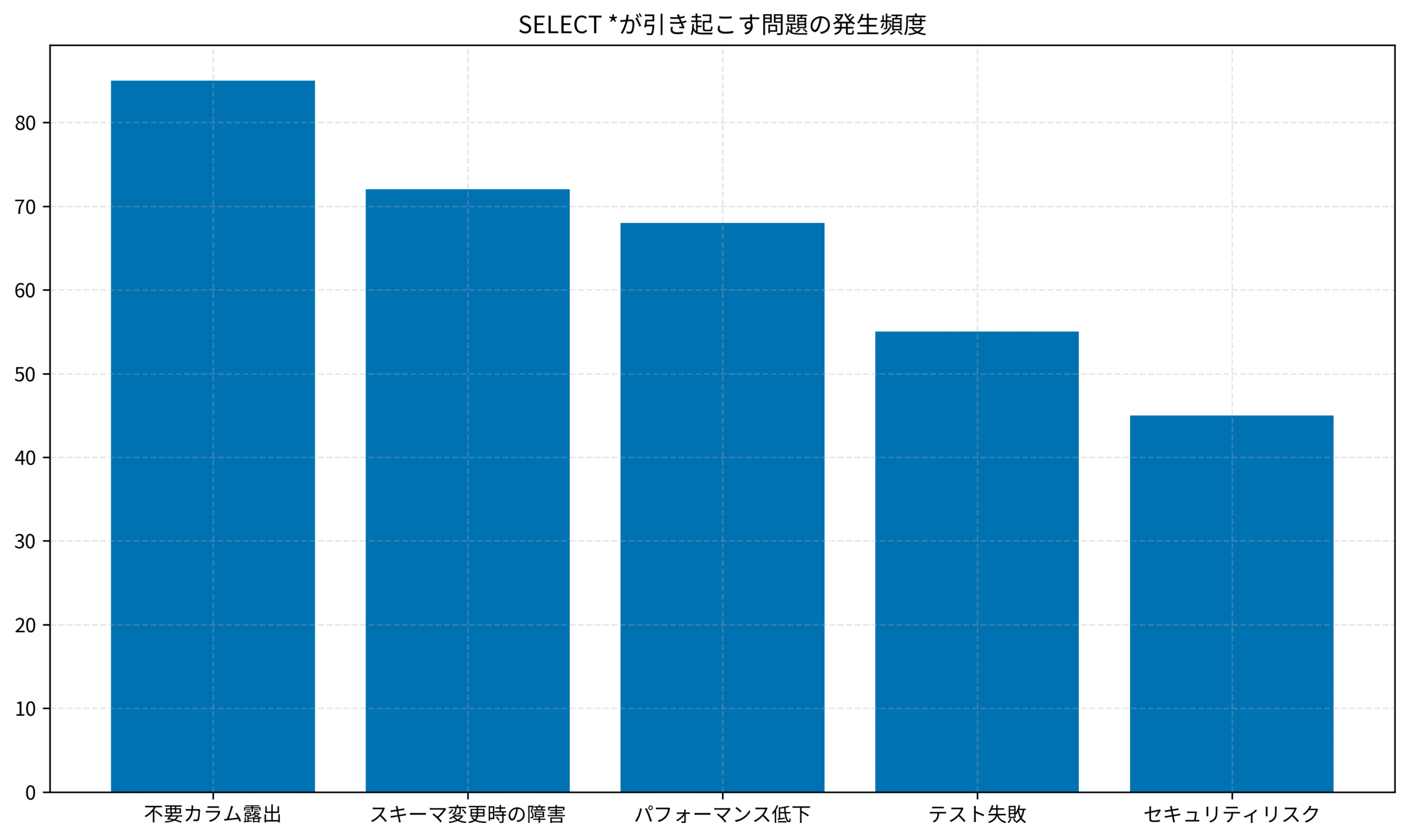
SELECT *の問題を定量的に理解する
SELECT *がどの程度の問題を引き起こすのか、定量的なデータで確認してみましょう。
以下のグラフは、SELECT *を多用しているプロジェクトで発生しやすい問題の傾向を示したものです。
このグラフからわかるように、最も多いのは「不要カラム露出」で、次いで「スキーマ変更時の障害」が続きます。
パフォーマンスへの影響
SELECT *はパフォーマンス面でも問題があります。
不要なカラムを取得することで、以下のようなオーバーヘッドが発生します。
- ネットワーク帯域の浪費:大きなBLOBやTEXTカラムを含むテーブルでは、転送データ量が大幅に増加
- メモリ使用量の増加:アプリケーション側で不要なデータをメモリに保持することになる
- インデックスの非効率な利用:カバリングインデックスが使えなくなり、テーブルスキャンが発生しやすくなる
特にカバリングインデックスの問題は見落とされがちです。
SELECT column1, column2 FROM table WHERE column1 = ?のようなクエリで、(column1, column2)のインデックスがあれば、テーブル本体にアクセスせずにインデックスだけで結果を返せます。
しかしSELECT *にすると、必ずテーブル本体へのアクセスが発生し、パフォーマンスが劣化します。
汚いコードを整理するPjM視点のデザインレビュー実践ガイドでも解説していますが、コードの保守性を高めるには「意図を明示する」ことが重要です。
SELECT *は意図が不明確なため、レビューでも問題を見つけにくくなります。
Clean Code アジャイルソフトウェア達人の技でも強調されているように、コードは「何をしているか」が一目でわかるように書くべきです。
カラムを明示することで、そのクエリが何を取得しようとしているのかが明確になります。
カラム明示化の実践パターン
では、具体的にどのようにSELECT *を改善すればよいのでしょうか。
ここでは、実践的なパターンをいくつか紹介します。
基本パターン:必要なカラムだけを列挙する
最もシンプルな改善策は、必要なカラムを明示的に列挙することです。
-- アンチパターン
SELECT * FROM users WHERE status = 'active';
-- 改善後
SELECT
user_id,
username,
email,
created_at
FROM users
WHERE status = 'active';この書き方には以下のメリットがあります。
- 意図の明確化:このクエリが何を取得しようとしているかが一目でわかる
- スキーマ変更への耐性:新しいカラムが追加されても、このクエリは影響を受けない
- レビューのしやすさ:不要なカラムを取得していないかをレビューで確認できる
dbtにおけるベストプラクティス
dbtを使ったデータパイプラインでは、SELECT *の問題がより顕著になります。
上流のモデルにカラムが追加されると、下流のすべてのモデルに自動的に伝播してしまうためです。
-- models/staging/stg_users.sql
-- アンチパターン
SELECT * FROM {{ source('raw', 'users') }}
-- 改善後
SELECT
id AS user_id,
name AS username,
email,
created_at,
updated_at
FROM {{ source('raw', 'users') }}dbtでは、ステージングレイヤーでカラムを明示的に選択し、必要に応じてリネームすることが推奨されています。
これにより、上流のスキーマ変更が下流に伝播することを防げます。
Supabase Edge Functionsで構築するサーバーレスAPI設計パターンでも解説していますが、データアクセス層では「何を取得するか」を明示的に定義することが重要です。
リファクタリング(第2版)でも述べられているように、リファクタリングの基本は「小さな変更を積み重ねる」ことです。
既存のSELECT *を一度にすべて書き換えるのではなく、新規開発から徐々にカラム明示化を適用していくのが現実的なアプローチです。

チームへの展開と運用ルール
個人の意識だけでは、SELECT *の問題を根本的に解決することはできません。
チーム全体でルールを共有し、仕組みとして防ぐことが重要です。
コーディング規約への明記
まず、チームのコーディング規約にSELECT *の禁止を明記しましょう。
ただし、単に「禁止」と書くだけでは効果が薄いです。
なぜ禁止なのか、どのような問題が発生するのかを具体的に説明することが重要です。
私がPjMとして関わったプロジェクトでは、以下のような規約を設けました。
- 本番コードでの
SELECT *は原則禁止:アドホックな分析やデバッグ目的を除き、本番コードでは必ずカラムを明示する - 例外を認める場合は理由をコメントに記載:どうしても
SELECT *を使う必要がある場合は、その理由をコメントに残す - レビューでのチェック項目に追加:プルリクエストのレビュー時に、
SELECT *がないかを確認する
静的解析ツールの活用
人間のレビューだけに頼るのではなく、静的解析ツールを活用して自動的に検出することも効果的です。
SQLFluffなどのリンターを使えば、SELECT *を含むクエリを自動的に検出できます。
# .sqlfluff
[sqlfluff:rules:L044]
# SELECT * を禁止
enabled = TrueCIパイプラインに組み込むことで、SELECT *を含むコードがマージされることを防げます。
FastAPI + LangChain実践ガイド:高速AIバックエンド構築の設計パターンと運用ノウハウでも解説していますが、コード品質を維持するには自動化が欠かせません。
[エンジニアのための]データ分析基盤入門<基本編>でも述べられているように、データ基盤の運用では「人に依存しない仕組み」を作ることが重要です。
静的解析ツールの導入は、その第一歩となります。

まとめ
SELECT *は一見便利に見えますが、データモデルの保守性を著しく低下させるアンチパターンです。
この記事で解説した内容を振り返ると、以下のポイントが重要です。
- スキーマ変更への脆弱性:カラム追加や変更時にアプリケーションが壊れるリスクがある
- 意図しないデータ露出:本来公開すべきでないカラムが自動的に取得されてしまう
- パフォーマンスの劣化:不要なデータ転送やカバリングインデックスの非効率な利用が発生する
- カラム明示化が解決策:必要なカラムだけを列挙することで、これらの問題を防げる
- チームでの仕組み化が重要:コーディング規約と静的解析ツールで、組織的に対策する
まずは新規開発からSELECT *を使わない習慣をつけ、既存コードは徐々にリファクタリングしていくのが現実的なアプローチです。
小さな変更の積み重ねが、長期的なデータモデルの保守性を大きく向上させます。










