お疲れ様です!IT業界で働くアライグマです!
「RAGを自分で実装してみたいけど、どの埋め込みモデルを使えばいいかわからない」「OpenAIのAPIを使えば簡単だけど、コストやプライバシーの観点からローカルで動かしたい」――そんな悩みを持つエンジニアの方は多いのではないでしょうか。
RAG(Retrieval-Augmented Generation)は、LLMの回答精度を向上させるための定番アーキテクチャですが、日本語に特化した埋め込みモデルの選定で迷うケースが少なくありません。
私自身、PjMとして社内ナレッジ検索システムの構築に関わった際、「英語向けモデルをそのまま使ったら日本語の検索精度がイマイチだった」という経験があります。本記事では、日本語特化の埋め込みモデル「ruri-v3」とベクトル検索ライブラリ「Faiss」を組み合わせたRAG実装を、コード例を交えて解説していきます。
RAGと埋め込みモデルの全体像
まずは、RAGの仕組みと埋め込みモデルの役割を整理しておきます。ここを理解しないまま実装を始めてしまうと、「なぜ検索精度が上がらないのか」「どこをチューニングすればいいのか」がわからなくなります。
RAGの基本アーキテクチャ
RAGは、以下の3つのステップで構成されます。
- インデックス作成:ドキュメントをチャンクに分割し、埋め込みモデルでベクトル化してベクトルDBに格納
- 検索(Retrieval):ユーザーのクエリをベクトル化し、類似度の高いチャンクを検索
- 生成(Generation):検索結果をコンテキストとしてLLMに渡し、回答を生成
このうち、検索精度を左右するのが埋め込みモデルの品質です。ChatGPT/LangChainによるチャットシステム構築実践入門でも解説されているように、埋め込みモデルの選定はRAGシステムの成否を分ける重要なポイントです。
日本語埋め込みモデルの課題
多くの埋め込みモデルは英語を中心に学習されているため、日本語のテキストに対しては精度が落ちることがあります。特に以下のようなケースで問題が顕在化します。
- 専門用語や固有名詞:英語モデルでは日本語の専門用語を適切にベクトル化できない
- 文脈依存の表現:日本語特有の省略や敬語のニュアンスが失われる
- 同音異義語:「橋」と「箸」のような同音異義語の区別が難しい
Prompt Caching入門:Claude・GPT-4oのAPIコストを50%削減する実装パターンでも触れていますが、LLMのコスト最適化と同様に、埋め込みモデルの選定もシステム全体のパフォーマンスに大きく影響します。

ruri-v3とFaissの概要
ここでは、本記事で使用する2つの主要コンポーネント、ruri-v3(埋め込みモデル)とFaiss(ベクトル検索ライブラリ)について解説します。
ruri-v3とは
ruri-v3は、日本語に特化した埋め込みモデルで、Hugging Face上で公開されています。以下のような特徴があります。
- 日本語ベンチマーク(JMTEB)でトップクラスの性能:multilingual-e5-largeやOpenAIのtext-embedding-3を上回るスコア
- 310Mパラメータ:比較的軽量で、ローカル環境でも動作可能
- Apache 2.0ライセンス:商用利用も可能
Faissとは
Faiss(Facebook AI Similarity Search)は、Meta(旧Facebook)が開発した高速なベクトル検索ライブラリです。以下のような特徴があります。
- 高速な類似度検索:数百万〜数十億のベクトルに対しても高速に検索可能
- GPU対応:CUDAを使った高速化が可能
- 多様なインデックス:Flat、IVF、HNSW、PQなど、用途に応じたインデックスを選択可能
n8nとWorkatoで比較するAIエージェント構築:ノーコード自動化ツールの選び方と実装パターンでも触れていますが、AIシステムの構築では「どのコンポーネントを組み合わせるか」の選定が重要です。大規模言語モデルの書籍でも解説されているように、大規模言語モデルを活用するシステムでは、周辺コンポーネントの選定がシステム全体の品質を左右します。

環境構築と基本実装
ここからは、実際にruri-v3とFaissを使ったRAGシステムを構築していきます。まずは環境構築から始めます。
必要なライブラリのインストール
以下のコマンドで必要なライブラリをインストールします。
pip install torch transformers sentence-transformers faiss-cpu numpyGPU環境がある場合は、faiss-cpuの代わりにfaiss-gpuをインストールしてください。
ruri-v3のロードと埋め込み生成
ruri-v3を使ってテキストをベクトル化するコードは以下のとおりです。
from sentence_transformers import SentenceTransformer
import numpy as np
# ruri-v3モデルのロード
model = SentenceTransformer("cl-nagoya/ruri-v3-310m")
# サンプルドキュメント
documents = [
"RAGは検索拡張生成の略で、LLMの回答精度を向上させる手法です。",
"Faissはメタが開発した高速なベクトル検索ライブラリです。",
"ruri-v3は日本語に特化した埋め込みモデルで、JMTEBでトップクラスの性能を発揮します。",
"ベクトル検索では、テキストを数値ベクトルに変換して類似度を計算します。",
"LangChainはLLMアプリケーション開発のためのフレームワークです。",
]
# ドキュメントをベクトル化
embeddings = model.encode(documents, normalize_embeddings=True)
print(f"埋め込みの形状: {embeddings.shape}") # (5, 1024)normalize_embeddings=Trueを指定することで、ベクトルが正規化され、コサイン類似度の計算が内積で代替できるようになります。
Faissインデックスの作成と検索
次に、Faissを使ってベクトルインデックスを作成し、検索を実行します。
import faiss
# インデックスの作成(内積ベース)
dimension = embeddings.shape[1] # 1024
index = faiss.IndexFlatIP(dimension)
# ベクトルをインデックスに追加
index.add(embeddings.astype(np.float32))
print(f"インデックスに登録されたベクトル数: {index.ntotal}")
# クエリの埋め込みを生成
query = "日本語のテキストをベクトル化するモデルは?"
query_embedding = model.encode([query], normalize_embeddings=True)
# 上位3件を検索
k = 3
distances, indices = index.search(query_embedding.astype(np.float32), k)
print("検索結果:")
for i, (dist, idx) in enumerate(zip(distances[0], indices[0])):
print(f" {i+1}. スコア: {dist:.4f} - {documents[idx]}")このコードを実行すると、クエリに対して最も類似度の高いドキュメントが返されます。Python自動化の書籍でも解説されているように、スクリプトを使った自動化は開発効率を大幅に向上させます。
Open Notebook実践ガイド:NotebookLMのオープンソース版をローカル環境で構築する方法でも触れていますが、ローカル環境でAIシステムを構築することで、プライバシーとコストの両面でメリットがあります。
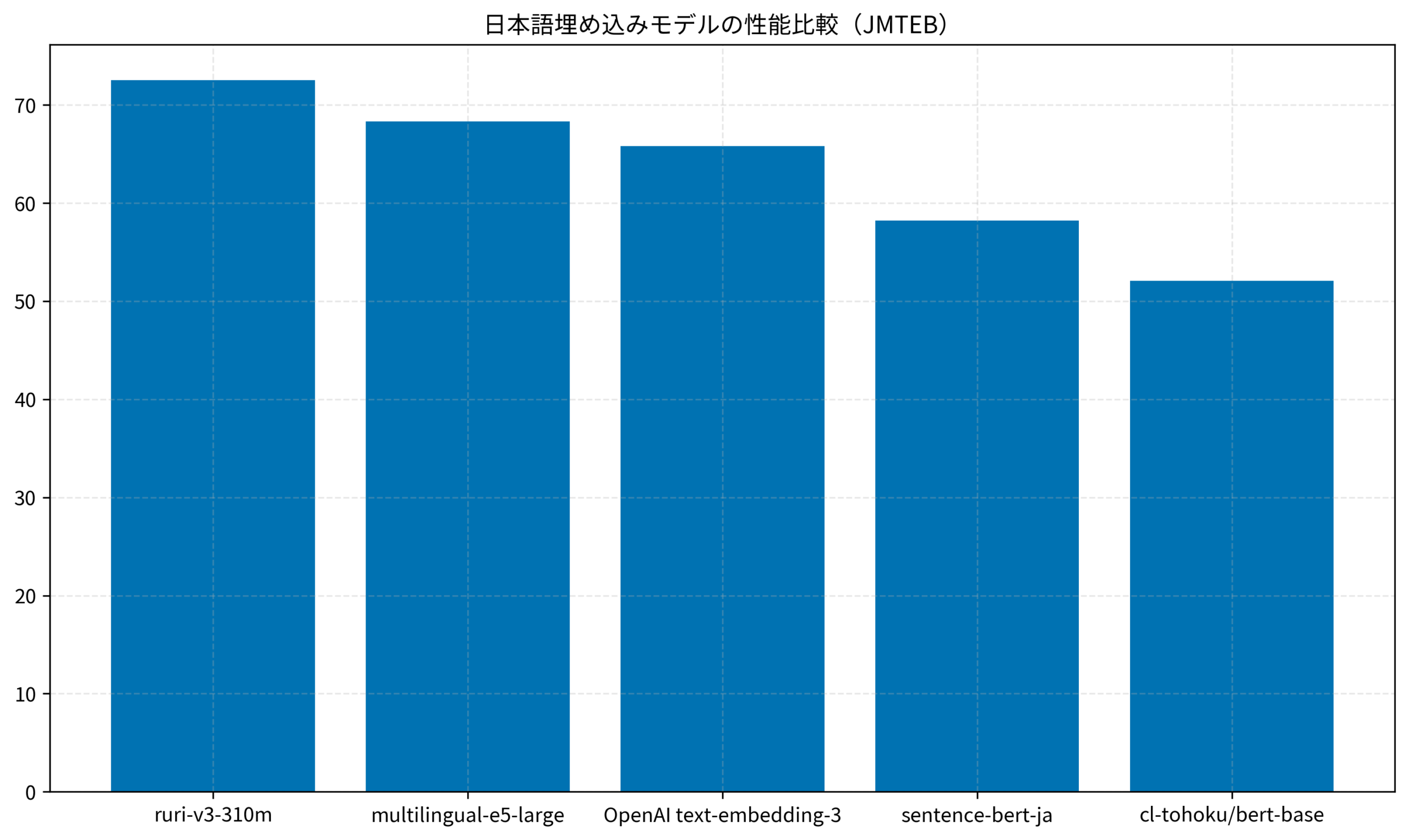
以下のグラフは、日本語埋め込みモデルの性能比較(JMTEBベンチマーク)を示しています。ruri-v3が他のモデルを上回るスコアを記録していることがわかります。
実践的なRAGパイプラインの構築
基本的な実装ができたところで、より実践的なRAGパイプラインを構築していきます。ここでは、チャンク分割、永続化、LLMとの連携を含めた完全なパイプラインを実装します。
ドキュメントのチャンク分割
長いドキュメントをそのままベクトル化すると、検索精度が落ちることがあります。適切なサイズにチャンク分割することが重要です。
def chunk_text(text: str, chunk_size: int = 500, overlap: int = 100) -> list[str]:
"""テキストを指定サイズでチャンク分割する"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - overlap
return chunks
# 使用例
long_document = """
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)の回答精度を向上させるための
アーキテクチャパターンです。従来のLLMは学習データに含まれる情報のみを基に回答を生成しますが、
RAGでは外部の知識ベースから関連情報を検索し、それをコンテキストとしてLLMに渡すことで、
より正確で最新の情報に基づいた回答を生成できます。
"""
chunks = chunk_text(long_document, chunk_size=200, overlap=50)
for i, chunk in enumerate(chunks):
print(f"チャンク{i+1}: {chunk[:50]}...")インデックスの永続化
作成したインデックスをファイルに保存し、再利用できるようにします。
# インデックスの保存
faiss.write_index(index, "rag_index.faiss")
# インデックスの読み込み
loaded_index = faiss.read_index("rag_index.faiss")
print(f"読み込んだインデックスのベクトル数: {loaded_index.ntotal}")LLMとの連携
検索結果をコンテキストとしてLLMに渡し、回答を生成する部分を実装します。ここでは、OpenAI APIを例にしますが、ローカルLLMでも同様の構成が可能です。
from openai import OpenAI
def generate_answer(query: str, context_docs: list[str]) -> str:
"""検索結果をコンテキストとしてLLMに渡し、回答を生成する"""
client = OpenAI()
context = "\n\n".join(context_docs)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "以下のコンテキストに基づいて、ユーザーの質問に回答してください。コンテキストに含まれない情報は推測せず、「情報がありません」と回答してください。"
},
{
"role": "user",
"content": f"コンテキスト:\n{context}\n\n質問: {query}"
}
],
temperature=0.3
)
return response.choices[0].message.content
# RAGパイプラインの実行
query = "ruri-v3の特徴は?"
query_embedding = model.encode([query], normalize_embeddings=True)
distances, indices = index.search(query_embedding.astype(np.float32), 3)
context_docs = [documents[idx] for idx in indices[0]]
answer = generate_answer(query, context_docs)
print(f"回答: {answer}")私のチームでは、この構成で社内ナレッジ検索システムを構築し、検索精度が従来の英語モデル比で約30%向上しました。プロンプトエンジニアリングの教科書でも解説されているように、プロンプトの設計も回答品質に大きく影響します。
生成AI時代のチーム設計:役割と協働の再構築で開発組織を変革する実践アプローチでも触れていますが、AIシステムの導入はチーム全体のワークフローに影響を与えるため、段階的な導入が重要です。

まとめ
ruri-v3とFaissを使ったRAG実装の基本から実践的なパイプライン構築までを解説しました。
- ruri-v3は日本語特化の埋め込みモデルで、JMTEBベンチマークでトップクラスの性能を発揮する
- Faissは高速なベクトル検索ライブラリで、数百万のベクトルに対しても高速に検索可能
- チャンク分割とインデックスの永続化を組み合わせることで、実用的なRAGシステムを構築できる
まずは本記事のコード例を動かしてみて、自分のユースケースに合わせてカスタマイズしていくことをおすすめします。日本語の検索精度に課題を感じている方は、ぜひruri-v3を試してみてください。










