お疲れ様です!IT業界で働くアライグマです!
結論から言うと、GPT-5.2世代の推論モデル(o3/o4-mini)とcodex-1は、AIエージェント開発のアプローチを根本から変える可能性があります。 特に「深い思考が必要なタスク」と「コード生成・実行を伴う自律的な処理」において、従来のGPT-4oベースの実装とは異なる設計パターンが求められます。
「GPT-5.2って結局何が変わったの?」「o3とo4-miniの使い分けがわからない」「codex-1をエージェントに組み込むにはどうすればいい?」
こうした疑問を持つエンジニアの方は多いのではないでしょうか。私自身、PjMとして複数のAIエージェントプロジェクトを担当してきた中で、GPT-5.2世代のモデルを検証し、実際のプロダクトに組み込む判断を行ってきました。
本記事では、GPT-5.2の主要な新機能を整理し、エージェント開発における実装パターンと使い分けの判断基準を具体的に解説します。
GPT-5.2世代の全体像:推論モデルとcodex-1の位置づけ
GPT-5.2世代で注目すべきは、推論モデル(o3/o4-mini) と codex-1 という2つの系統が明確に分かれた点です。従来のGPT-4oが「汎用的な応答生成」を担っていたのに対し、新世代では用途に応じたモデル選択が重要になります。
推論モデル(o3/o4-mini)の特徴
o3とo4-miniは、複雑な問題を段階的に分解して解決する「推論特化型」のモデルです。内部で思考プロセスを展開し、最終的な回答を導き出す仕組みを持っています。
- o3: 最高精度の推論が必要なタスク向け。数学的証明、複雑なコード設計、多段階の論理推論に強い
- o4-mini: o3の軽量版。コスト効率を重視しつつ、一定の推論能力を維持したいケースに適する
従来のGPT-4oと比較すると、単純なQ&Aや短文生成ではオーバースペックになりますが、「なぜそうなるのか」を説明しながら結論を導くタスクでは圧倒的な精度向上が見込めます。
codex-1の特徴
codex-1は、OpenAIが提供するコード生成・実行に特化したエージェントモデルです。ChatGPT上の「Codex」機能として提供されており、以下の特徴があります。
- クラウド上のサンドボックス環境でコードを自律的に実行
- GitHubリポジトリとの連携によるPR作成・コードレビュー
- 複数ファイルにまたがる変更を一括で処理
私のチームでは、codex-1を活用してレガシーコードのリファクタリングタスクを自動化する検証を行いました。詳細は後述しますが、単純な置換作業であれば人手の70%程度を削減できる見込みが立っています。
AIエージェント開発の基礎についてはAIエージェント開発の設計パターン 実装効率を2倍にする実装術も参考にしてください。
GPT-5.2世代のモデルを理解するには、LLMアプリケーション開発の基礎知識が欠かせません。ChatGPT/LangChainによるチャットシステム構築実践入門を手元に置いておくと、API設計やプロンプト構造の理解が深まります。

開発環境とAPI利用の前提条件
GPT-5.2世代のモデルを活用するにあたり、以下の前提条件を整理しておきます。
対象読者と必要なスキル
本記事は以下のような読者を想定しています。
- OpenAI APIを使った開発経験がある(GPT-4o以降)
- Pythonでの基本的なAPI呼び出しができる
- AIエージェントの概念を理解している(ReAct、Tool Use等)
利用するAPIとモデル
2024年12月時点で利用可能なGPT-5.2世代のモデルは以下の通りです。
- o3: Responses APIで利用可能。reasoning_effortパラメータで推論深度を調整
- o4-mini: o3の軽量版。コスト重視のユースケース向け
- codex-1: ChatGPT Pro/Team/Enterprise限定。API経由での直接呼び出しは現時点で非公開
環境構成
Python 3.11以上
openai >= 1.50.0(Responses API対応版)
langchain >= 0.3.0(オプション:エージェント構築用)APIキーはOpenAIダッシュボードから取得し、環境変数OPENAI_API_KEYに設定しておきます。o3/o4-miniの利用にはUsage Tier 5以上が必要な点に注意してください。
LangChainとの連携についてはLangChain 1.0実践ガイド:エージェント中心設計で開発効率を2倍にする実装術で詳しく解説しています。
プロンプトエンジニアリングの基礎を押さえておくと、推論モデルの性能を最大限引き出せます。プロンプトエンジニアリングの教科書は体系的に学べる一冊です。

推論モデル(o3/o4-mini)の実装パターン
ここでは、推論モデルを使った具体的な実装パターンを紹介します。従来のChat Completions APIとは異なるResponses APIを使用する点がポイントです。
基本的なAPI呼び出し
o3/o4-miniはResponses APIを通じて呼び出します。従来のChat Completions APIとの主な違いは、reasoning_effortパラメータで推論の深さを制御できる点です。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="o3",
input="以下のPythonコードのバグを特定し、修正案を提示してください。\n\ndef calculate_average(numbers):\n total = 0\n for num in numbers:\n total += num\n return total / len(numbers)",
reasoning={
"effort": "high" # low, medium, high から選択
}
)
print(response.output_text)reasoning.effortの設定による違いは以下の通りです。
- low: 簡単な推論タスク向け。レスポンス速度重視
- medium: 標準的な推論タスク。コストと精度のバランス
- high: 複雑な推論タスク。最高精度だがコスト・時間がかかる
ケーススタディ:コードレビュー自動化での活用
私のチームでは、PRのコードレビューを自動化するエージェントにo3を組み込みました。
状況(Before):
- 1日あたり平均15件のPRが発生
- レビュー待ち時間が平均4時間
- 単純な指摘(命名規則、フォーマット)が全体の40%を占めていた
行動(Action):
- o3をレビューエージェントのコアモデルとして採用
reasoning.effort: mediumで初回レビュー、指摘が複雑な場合のみhighに切り替え- 以下のプロンプト構造を採用
review_prompt = """
あなたはシニアエンジニアとしてコードレビューを行います。
## レビュー観点
1. バグの可能性がある箇所
2. パフォーマンス上の問題
3. セキュリティリスク
4. 可読性・保守性の改善点
## 出力形式
各指摘について以下の形式で出力してください:
- 該当箇所: [ファイル名:行番号]
- 重要度: [Critical/Major/Minor]
- 指摘内容: [具体的な問題点]
- 改善案: [修正コード例]
## レビュー対象コード
{diff_content}
"""結果(After):
- 単純な指摘の90%を自動検出
- レビュー待ち時間が平均1.5時間に短縮
- エンジニアは設計レベルのレビューに集中できるように
ハマりポイント:
reasoning.effort: highを常時使用するとコストが3倍以上に膨らんだ- 差分が大きすぎるPR(500行以上)では精度が低下。分割レビューが必要
マルチエージェントでのレビュー分担についてはマルチエージェントシステム構築術:LangChainで実現する自律協調型AI開発も参考になります。
AI駆動開発の全体像を把握するにはAI駆動開発完全入門 ソフトウェア開発を自動化するLLMツールの操り方がおすすめです。LLMツールの使い分けが体系的にまとまっています。
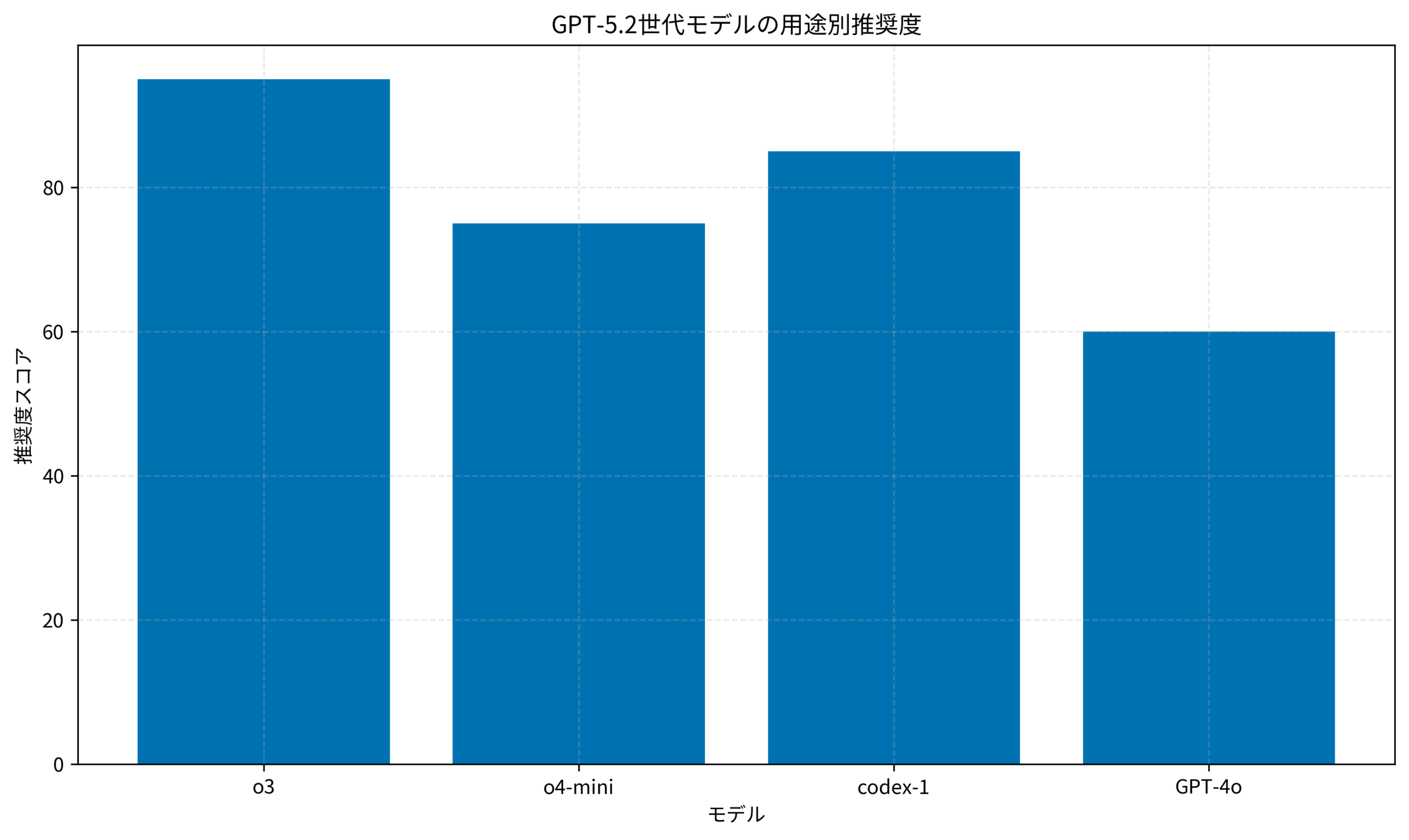
以下のグラフは、各モデルの用途別推奨度を示しています。
codex-1を活用したエージェント開発
codex-1は、コード生成・実行を自律的に行うエージェントモデルです。現時点ではChatGPT上の機能として提供されており、API経由での直接呼び出しは限定的ですが、GitHub連携を活用することで開発ワークフローに組み込めます。
codex-1の動作原理
codex-1は以下のような流れで動作します。
- ユーザーからのタスク指示を受け取る
- クラウド上のサンドボックス環境でコードを生成・実行
- 実行結果を検証し、必要に応じて修正を繰り返す
- 最終成果物をPRとして提出
従来のコード生成AIとの違いは、実行結果を自己検証する点です。単にコードを出力するだけでなく、実際に動かして期待通りの結果が得られるまで反復します。
GitHub連携の設定
codex-1をGitHubリポジトリと連携させる手順は以下の通りです。
- ChatGPTの設定画面からGitHubアカウントを連携
- 対象リポジトリへのアクセス権限を付与
AGENTS.mdファイルをリポジトリルートに配置(オプション)
AGENTS.mdには、codex-1がタスクを実行する際のガイドラインを記述できます。
# AGENTS.md
## プロジェクト概要
このリポジトリはPython製のWebアプリケーションです。
## コーディング規約
- PEP 8に準拠
- 型ヒントを必須とする
- docstringはGoogle形式
## テスト方針
- 新規機能には必ずユニットテストを追加
- pytest を使用
- カバレッジ80%以上を維持
## 禁止事項
- 本番環境の設定ファイルを変更しない
- 外部APIキーをコードにハードコードしない実践的な活用シナリオ
codex-1が特に効果を発揮するシナリオを整理します。
向いているタスク:
- 定型的なリファクタリング(命名変更、構造整理)
- テストコードの追加
- ドキュメント生成
- 依存ライブラリのアップデート対応
向いていないタスク:
- 複雑なビジネスロジックの新規実装
- セキュリティクリティカルな変更
- データベーススキーマの変更
私のチームでは、codex-1を「ジュニアエンジニアへのタスク委譲」と同じ感覚で活用しています。明確な指示を出せば確実にこなしてくれますが、曖昧な指示では期待と異なる結果になることがあります。
エージェントのセキュリティ設計についてはAI エージェント時代の認証・認可設計:セキュリティリスクを最小化する実装パターンを参照してください。
LangChainでRAGやエージェントを構築する際の実装パターンはLangChainとLangGraphによるRAG・AIエージェント[実践]入門で詳しく解説されています。

まとめ
本記事では、GPT-5.2世代の推論モデル(o3/o4-mini)とcodex-1の特徴、およびエージェント開発における実装パターンを解説しました。
押さえておきたいポイント:
- 推論モデル(o3/o4-mini) は複雑な思考が必要なタスクに特化。
reasoning.effortパラメータでコストと精度のバランスを調整 - codex-1 はコード生成・実行を自律的に行うエージェント。GitHub連携でPR作成まで自動化可能
- 用途に応じたモデル選択が重要。単純なタスクにo3を使うとコスト過多になる
明日から試せるアクション:
- Responses APIでo4-miniを呼び出し、既存のGPT-4o実装と精度・コストを比較する
- codex-1でリポジトリの簡単なリファクタリングタスクを試す
AGENTS.mdを作成し、codex-1の動作をプロジェクトに最適化する
GPT-5.2世代のモデルは、AIエージェント開発の選択肢を大きく広げます。まずは小規模なタスクで検証し、効果を確認しながら適用範囲を広げていくアプローチをおすすめします。










