
お疲れ様です!IT業界で働くアライグマです!
「RAGを試してみたいけど、OpenAI APIの課金が怖い」「個人プロジェクトで使うには月額コストが高すぎる」——こうした悩みを抱えていませんか?
実は、月額5ドル以下でも十分に実用レベルのRAGシステムを構築できます。本記事では、コストを抑えながらも本番運用に耐えうるRAG構成を、具体的なアーキテクチャと実装例とともに解説します。
なぜRAGの運用コストが問題になるのか
RAG(Retrieval-Augmented Generation)は、外部知識を検索してLLMに渡すことで、ハルシネーションを抑えつつ最新情報を回答に反映できるアーキテクチャです。しかし、一般的な構成では以下のコストが発生します。
典型的なRAG構成のコスト内訳
- LLM API費用:OpenAI GPT-4oで1Mトークンあたり$5〜$15
- Embedding API費用:text-embedding-3-smallで1Mトークンあたり$0.02
- ベクトルDB費用:Pinecone Starterで無料枠超過後$70/月〜
- インフラ費用:AWS/GCPのコンピュート・ストレージ
個人開発や小規模プロジェクトでは、このコスト構造がボトルネックになりがちです。
MixLMでRAGのリランキングを高速化する実装ガイドでは、検索精度を維持しながらAPI呼び出しを削減する方法も紹介しています。
 IT女子 アラ美
IT女子 アラ美低コストRAGを実現する5つのアーキテクチャ選択肢
コストを抑えるためには、各コンポーネントの選択が重要です。以下に、月額コスト別の構成オプションを整理します。
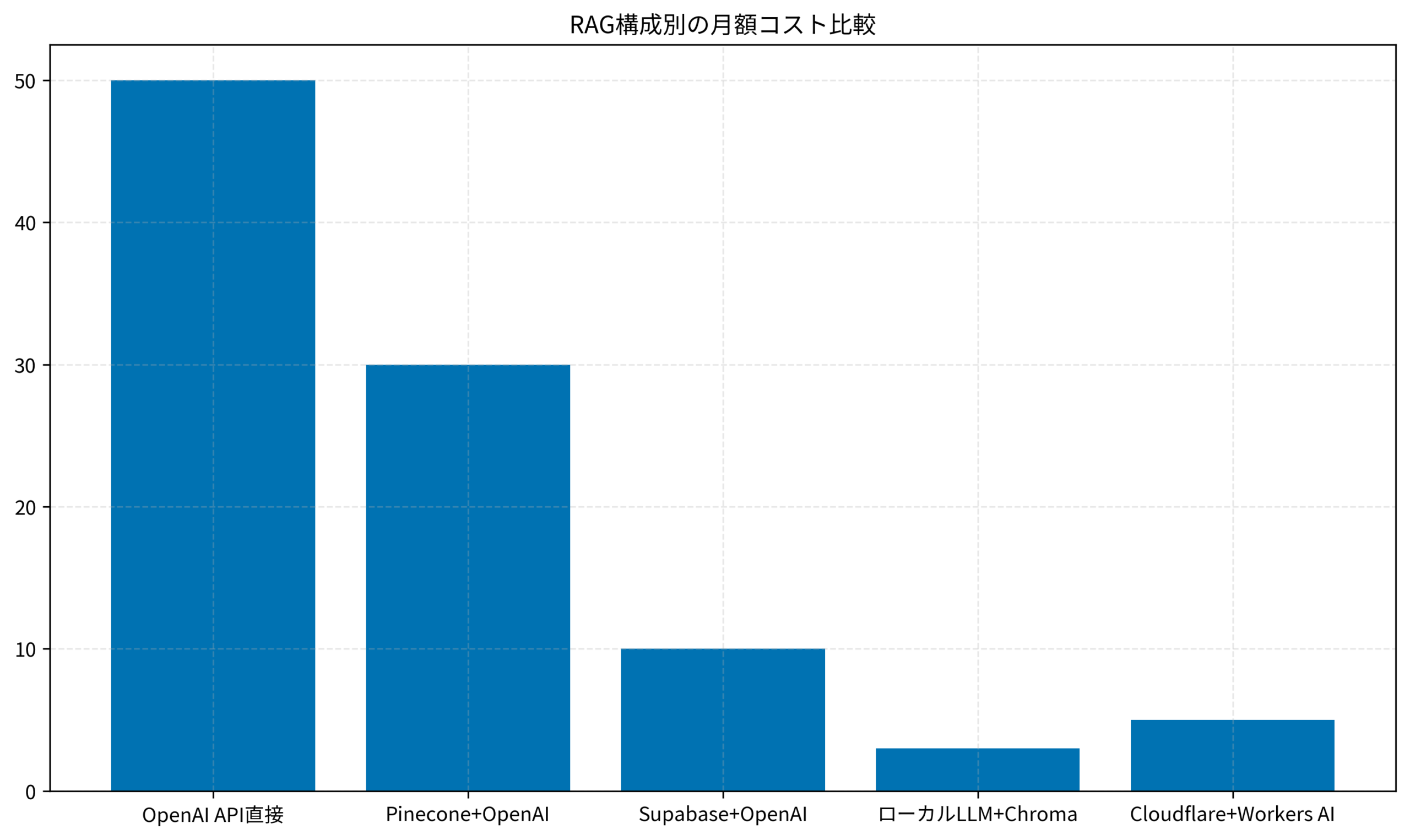
構成1:Cloudflare Workers AI + D1(月額0〜5ドル)
Cloudflare Workers AIは、無料枠で1日10,000リクエストが利用可能です。D1(SQLiteベースのエッジDB)と組み合わせることで、小規模なRAGシステムを無料で構築できます。
構成2:Supabase + OpenAI(月額5〜10ドル)
Supabaseのpgvector拡張を使えば、無料枠内でベクトル検索が可能です。OpenAI APIは従量課金のため、小規模利用なら月額数ドルで収まります。
構成3:ローカルLLM + ChromaDB(月額0ドル)
Ollamaなどでローカルにllama3やphi-3を動かし、ChromaDBでベクトル検索を行う構成。ハードウェア初期投資は必要ですが、ランニングコストはゼロです。
CursorとOllamaで構築するローカルRAG環境では、ローカルLLMを活用した実装例を詳しく解説しています。
IT女子 アラ美実装例:Supabase + OpenAIで月額5ドルRAGを構築する
ここでは、最もバランスの取れた「Supabase + OpenAI」構成の実装手順を解説します。
ステップ1:Supabaseプロジェクトの作成とpgvector有効化
-- pgvector拡張を有効化
CREATE EXTENSION IF NOT EXISTS vector;
-- ドキュメントテーブル作成
CREATE TABLE documents (
id BIGSERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding VECTOR(1536),
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- ベクトル検索用インデックス
CREATE INDEX ON documents USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);ステップ2:Embeddingとドキュメント登録
import openai
from supabase import create_client
supabase = create_client(SUPABASE_URL, SUPABASE_KEY)
openai.api_key = OPENAI_API_KEY
def embed_and_store(text: str, metadata: dict = None):
# Embedding生成(text-embedding-3-small: $0.02/1M tokens)
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
embedding = response.data[0].embedding
# Supabaseに保存
supabase.table("documents").insert({
"content": text,
"embedding": embedding,
"metadata": metadata or {}
}).execute()ステップ3:検索と回答生成
def rag_query(query: str, top_k: int = 3) -> str:
# クエリをEmbedding化
query_embedding = openai.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
# ベクトル検索(Supabase RPC)
results = supabase.rpc("match_documents", {
"query_embedding": query_embedding,
"match_count": top_k
}).execute()
# コンテキスト構築
context = "\n\n".join([r["content"] for r in results.data])
# GPT-4o-miniで回答生成(低コスト)
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"以下のコンテキストを参考に回答してください:\n{context}"},
{"role": "user", "content": query}
]
)
return response.choices[0].message.contentコンテキストエンジニアリング入門では、コンテキスト構築のベストプラクティスを詳しく解説しています。
IT女子 アラ美ケーススタディ:社内ドキュメント検索RAGを月額3ドルで運用した事例
あるスタートアップのエンジニアBさん(当時29歳)が、社内ドキュメント検索システムをRAGで構築した事例を紹介します。
状況(Before)
- 社内Wikiが1,500ページ以上に肥大化し、必要な情報を見つけるのに平均15分かかっていた
- 既存の全文検索では関連性の低い結果が多く、チャットで同僚に聞く方が早い状態
- 外部SaaSの導入は月額$200以上かかり、予算承認が下りなかった
行動(Action)
- アーキテクチャを自前で設計し構築:Supabase(無料枠)+ OpenAI text-embedding-3-small + GPT-4o-miniの構成を採用。Bさんは週末2日間でプロトタイプを実装した
- ドキュメントをバッチでEmbedding化:1,500ページを約50万トークンでEmbedding化。コストは約$0.01で完了。インクリメンタル更新スクリプトを追加し、新規ドキュメントは自動でベクトル化される仕組みを導入した
- Slack Botとして公開:社内Slackから質問を投げると、RAGが関連ドキュメントを検索して回答を返すBotを実装したところ、利用率が急上昇した
結果(After)
- 情報検索時間が平均15分から30秒に短縮(97%削減)
- 月間約2,000クエリを処理し、月額コストはOpenAI API $2.50 + Supabase無料枠 = 約$3で運用
- チャットでの「これどこに書いてある?」質問が70%減少し、チーム全体の生産性が向上
Amazon Bedrock AgentCoreでAIエージェントを本番運用するでは、エンタープライズ規模でのAI運用についても解説しています。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
月額5ドル以下でも、十分に実用的なRAGシステムを構築・運用することは可能です。
- コスト削減の鍵は、LLM(GPT-4o-mini)とベクトルDB(Supabase pgvector)の選択
- Cloudflare Workers AI + D1構成なら無料枠内で運用可能
- ローカルLLM + ChromaDBならランニングコストゼロ
- 小規模から始めて、トラフィック増加に応じてスケールアップする戦略が有効
RAGは「高コスト」というイメージがありますが、構成次第で個人開発でも手が届く技術です。まずは小さく始めて、効果を確認しながら拡張していくアプローチをおすすめします。
IT女子 アラ美








