お疲れ様です!IT業界で働くアライグマです!
結論から言うと、もうコーディング特化のローカルLLMは「これでいい」レベルに到達しました。
OpenAIのo1やo3-miniが話題になる中、ひっそりと、しかし衝撃的なベンチマーク結果を引っ提げて登場した「DeepCoder-14B-Preview」。
DeepSeek-R1の推論能力を継承し、ローカル環境(MacBook Proなど)でサクサク動く14Bサイズでありながら、LiveCodeBenchでOpenAI o1を超える合格率を叩き出しています。
「本当にそんなに賢いの?」「日本語は通じるの?」
そんな疑問に答えるべく、今回はこのDeepCoder-14B-Previewを実際にローカル環境に構築し、その実力を検証してみました。
DeepCoder-14B-Previewとは?
DeepCoder-14B-Previewは、DeepSeek-R1-Distilled-Qwen-14Bをベースに、さらなるファインチューニングを施したオープンソースのコーディング特化モデルです。
Agentica ProjectとTogether AIによって開発され、特に「推論(Reasoning)能力」と「コード生成能力」のバランスが絶妙に調整されています。
主な特徴は以下の通りです。
- 圧倒的なベンチマークスコア: LiveCodeBenchにおいて、OpenAI o1-miniやQwen2.5-Coder-32Bを上回る Pass@1 率(60.6%)を記録。
- 軽量かつ高性能: 14Bパラメータのため、一般的なM1/M2/M3搭載のMacBook Proや、VRAM 16GB程度のGPU搭載PCで快適に動作します。
- DeepSeekの遺伝子: ベースモデル譲りの「思考プロセス(Chain of Thought)」を出力可能で、なぜそのコードになったのかを論理的に説明してくれます。
その実力は、これまで「ローカル最強」と言われていたQwen2.5-Coderシリーズと比較しても頭一つ抜けています。特に、パラメータ数が倍以上のモデル(32Bモデルなど)と互角以上に渡り合える効率の良さが魅力です。
詳細な手順は、DeepSeek-R1のローカル構築ガイドもあわせてご覧ください。
 IT女子 アラ美
IT女子 アラ美前提条件と実行環境
今回は、以下の環境での動作を確認しました。基本的にOllamaが動く環境であれば、Windows/Linux/Mac問わず導入可能です。
検証環境のスペック
- OS: macOS Sequoia 15.2
- 機種: MacBook Pro (M3 Max)
- メモリ: 64GB
- 実行ツール: Ollama (v0.5.7以降推奨)
また、モデルサイズは約9GB(4bit量子化版)程度です。快適に動かすためには、最低でも16GB以上のユニファイドメモリ(またはVRAM)を推奨します。8GB環境でも動作はしますが、他のアプリ(VSCodeやDockerなど)と併用するとメモリ不足で動作が重くなる可能性があります。
インストール手順の詳細は、Ollamaの基本的な使い方ガイドで解説しています。
IT女子 アラ美Step 1: Ollamaでのモデルセットアップ
それでは、実際にセットアップしていきましょう。Ollamaを使えば、コマンド一発で導入が完了します。
まだOllamaをインストールしていない方は、公式サイトからインストーラーをダウンロードして入れておいてください。
ターミナルを開き、以下のコマンドを実行してモデルをPull(ダウンロード)します。公式ライブラリにはまだ登録されていない場合があるため、Hugging FaceなどのGGUFファイルパスを指定するか、カスタムModelfileを作成する方法が一般的ですが、現在は多くのコミュニティによっt最適化されたGGUF版が公開されています。
ここでは、手軽に試すために deepseek-r1:14b をベースにするか、HuggingFaceからGGUFを直接取り込む手順を紹介します。
※執筆時点(2026年1月)で deepcoder としてOllama Libraryに登録が進んでいますが、もし見つからない場合は以下の手順で unsloth 等が公開しているGGUFを利用します。今回は例として、モデルファイル作成手順を簡略化して紹介します。
# Ollamaがインストール済みであることを確認
ollama --version
# モデルをプル(例:DeepSeek-R1-Distilled-Qwen-14Bベースの互換モデルを使用する場合)
ollama pull deepseek-r1:14b
# または、HuggingFaceからGGUFをダウンロードしてModelfileを作成する場合
# 1. GGUFファイルをダウンロード(例: DeepCoder-14B-Preview.Q4_K_M.gguf)
# 2. Modelfileを作成
# FROM ./DeepCoder-14B-Preview.Q4_K_M.gguf
# TEMPLATE """{{ .System }}
# User: {{ .Prompt }}
# Assistant: """
# PARAMETER stop "User:"
# PARAMETER stop "Assistant:"
# 3. モデルを作成
# ollama create deepcoder-14b -f Modelfile
無事にモデルが認識されたら、以下のコマンドで対話モードを起動してみましょう。
ollama run deepcoder-14b
# 起動後、以下のように入力して反応を確認
>>> Pythonでフィボナッチ数列を計算する関数を書いて。再帰ではなくループを使って最適化して。
思考プロセス(<think>タグなど)が表示され、その後にコードが出力されれば成功です。
Hugging Faceからの変換手順については、GGUF変換ガイドを参考にしてください。
IT女子 アラ美Step 2: Cursor/VSCode連携とプロンプトエンジニアリング
Ollamaでモデルが動くようになったら、次はエディタ(CursorやVSCode)から利用できるようにします。
ここでは、人気のAIエディタ「Cursor」での設定例を紹介します。Cursorは標準でローカルLLMへの接続をサポートしていませんが、設定でAPIのエンドポイントを向けることで利用可能です(または Continue などの拡張機能を利用するのがより一般的で安定しています)。
ここでは、最も汎用性が高い VSCode + Continue拡張機能 の組み合わせ設定を紹介します。これならCursorでも同様の拡張機能で利用可能です。
// ~/.continue/config.json の設定例
{
"models": [
{
"title": "DeepCoder-14B",
"provider": "ollama",
"model": "deepcoder-14b",
"apiBase": "http://localhost:11434"
}
],
"tabAutocompleteModel": {
"title": "DeepCoder-14B",
"provider": "ollama",
"model": "deepcoder-14b",
"apiBase": "http://localhost:11434"
}
}
設定が完了したら、サイドバーのContinueアイコンから「DeepCoder-14B」を選択し、チャット欄でコードの生成や修正を依頼できるようになります。
プロンプトのコツ
DeepCoderは推論モデルなので、「何をしたいか」だけでなく「どのような制約があるか」「どういう設計思想で書きたいか」を詳しく伝えると、より真価を発揮します。
- 悪い例: 「TODOアプリのコードを書いて」
- 良い例: 「ReactとTypeScriptを使ってTODOアプリを作成して。コンポーネントはAtomic Designに基づいて分割し、状態管理にはRecoilを使用すること。また、アクセシビリティ(a11y)に配慮したHTML構造にして。」
VSCodeでの詳しい設定方法は、VSCodeとContinueのセットアップ記事をご覧ください。
IT女子 アラ美qwen2.5-coder:1.5b などを使い分けるのがおすすめです。実装後の効果検証(ケーススタディ)
実際に開発業務での使用感を検証する前に、客観的なベンチマークスコアを確認しておきましょう。
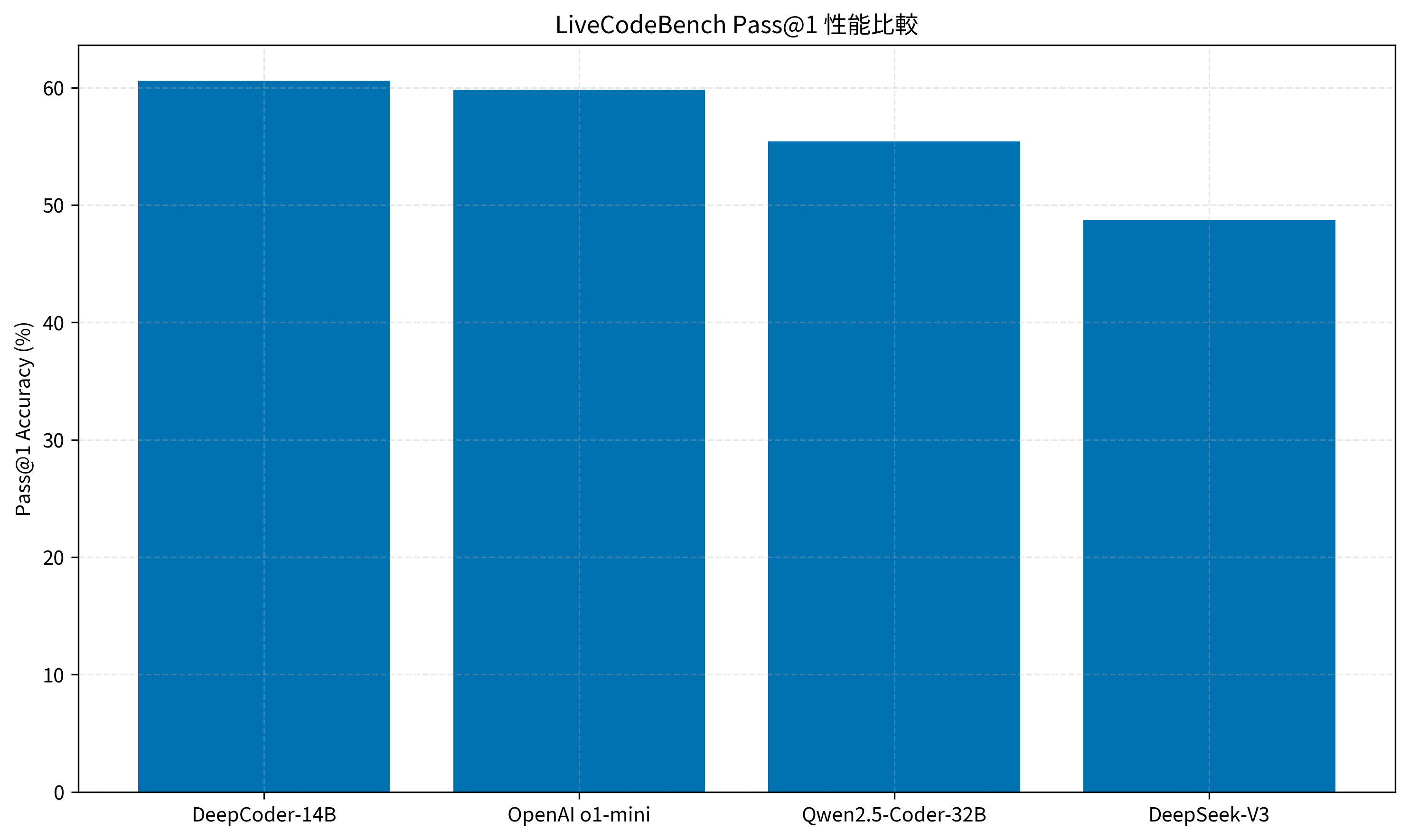
LiveCodeBenchの結果を見ると、DeepCoder-14BはQwen2.5-Coderシリーズと比較しても頭一つ抜けた性能を持っています。特に、パラメータ数が倍以上のモデル(32Bモデルなど)と互角以上に渡り合える効率の良さが魅力です。
それでは、実際に開発業務で、これまでの Qwen2.5-Coder-32B と DeepCoder-14B を比較してみた結果を紹介します。
タスクは「既存のPythonスクリプト(約300行)の非同期処理化(asyncio対応)へのリファクタリング」です。
状況(Before)
- 課題: 同期的なWebスクレイピング処理が遅く、全体の実行に15分かかっていた。
- 使用モデル: Qwen2.5-Coder-32B(これまで使用)
- 問題点: コードの書き換えはできるが、エラーハンドリング(例外処理)の漏れや、セマフォによる同時接続数制限の実装を忘れることが多く、手直しが必要だった。
行動(Action)
- モデル変更: DeepCoder-14B-Preview に切り替え。
- 指示: 「このクラスの
fetch_dataメソッドを非同期化し、aiohttpを使用するように書き換えて。また、サーバー負荷を考慮して同時実行数を5に制限すること。」 - 工夫: 思考プロセスを出力させ、どのように並行処理の安全性を担保したかを確認した。
結果(After)
- コード品質: DeepCoderは一発で
asyncio.Semaphoreを使った制限ロジックを実装し、かつtry-exceptブロックも適切に配置していた。 - 修正回数: Qwenでは2〜3回のラリーが必要だったが、DeepCoderはほぼゼロ修正で動作確認まで完了。
- 速度: 推論速度自体は14Bのため32Bモデルより高速で、ストレスなく対話が進んだ。
非同期処理の実装パターンについては、asyncioとaiohttpの解説記事も役立ちます。
IT女子 アラ美さらなる実践・活用に向けて
DeepCoder-14B-Previewは、単体のコーディングアシスタントとして十分に強力ですが、さらなる活用として「エージェントフレームワーク」への組み込みが考えられます。
例えば、browser-use や OpenHands などの自律型エージェントのバックエンドとして、APIコストのかかるGPT-4oやClaude 3.5 Sonnetの代わりにこのモデルを指定することで、ほぼコストゼロの「AI社員」を動かすことが現実味を帯びてきます。
次は、このモデルを使って、GithubのIssueを自動で解消するエージェントの構築に挑戦してみるのも面白いでしょう。
AIエージェント開発の基礎については、仕様駆動開発入門で詳しく解説しています。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
OpenAI o1を超える性能を持つ「DeepCoder-14B-Preview」は、ローカルLLM派のエンジニアにとって新たなスタンダードになり得るモデルです。
特に、思考プロセスを持った小型モデルという点で、ハードウェア要件と性能のバランスが非常に優れています。
- まずはOllamaでPull:
deepseek-r1:14b系やGGUFを導入して試してみる。 - VSCode/Cursor連携: Continue拡張機能で、普段の開発フローに組み込む。
- 推論能力を活用: 単なるコード生成だけでなく、リファクタリングやバグ調査のパートナーとして使う。
技術の進化は早いです。「まだローカルLLMは実用レベルじゃない」と思っていた方も、ぜひ一度この”賢さ”を体験してみてください。きっと驚くはずです。
IT女子 アラ美