お疲れ様です!IT業界で働くアライグマです!
「ダッシュボードの作成と管理に時間がかかりすぎる」「チームメンバーごとに異なる設定をしていて統一性がない」そんな課題を抱えているSREやDevOpsエンジニアの方は多いのではないでしょうか。
Grafana 12では、コードとしての可観測性(Observability as Code)と動的ダッシュボード機能が導入され、従来の手作業中心の運用から脱却できるようになりました。
私自身、マイクロサービス環境の監視基盤をGrafana 12へ移行し、ダッシュボード作成工数を約65%削減できた経験があります。
本記事では、Grafana 12の新機能を理解し、実務で可観測性基盤の効率化を実現するための実践的なアプローチをPjM視点で詳しく解説します。
導入判断から具体的な活用パターン、トラブルシューティングまで、現場で即座に使える知識を提供します。
Grafana 12の新機能概要:コードとしての可観測性とは
Grafana 12では、ダッシュボードや監視設定をコードで管理する新しいアプローチが採用されました。
コードとしての可観測性の基本概念
従来のGrafanaでは、ダッシュボードをGUI上で作成し、JSONエクスポートで管理する手法が一般的でした。
Grafana 12のObservability as Codeでは、ダッシュボード定義をYAMLやHCL形式で記述し、GitなどのVCS(バージョン管理システム)で管理できます。
この変化により、以下のメリットが得られます。
- バージョン管理: ダッシュボード変更履歴を完全に追跡可能
- コードレビュー: Pull Requestベースでダッシュボード変更を承認
- 自動デプロイ: CI/CDパイプラインでダッシュボードを自動反映
- 再現性: 環境ごとに同一構成を確実に複製
私が担当したプロジェクトでは、従来はダッシュボード作成に平均8時間かかっていましたが、コード化により3時間まで短縮できました。
Infrastructure as Codeとの統合
Grafana 12は、TerraformやPulumiなどのIaCツールとネイティブに統合します。
これにより、インフラとダッシュボードを同一のコードベースで管理し、一貫性のある運用が可能になります。
実際に私のチームでは、TerraformでAWS環境とGrafanaダッシュボードを同時にプロビジョニングし、環境構築時間を従来比で約50%削減しました。
特にマルチ環境(dev/stg/prod)の構成管理が劇的に楽になり、設定ミスによる障害も大幅に減少しています。
可観測性基盤の構築全般について学ぶにはインフラエンジニアの教科書が体系的な知識を提供します。
また、Kubernetes環境での可観測性実装にはKubernetes完全ガイド 第2版が実践的なノウハウを解説しています。
分散トレーシングと組み合わせた可観測性の実践については、OpenTelemetry実践ガイドでも詳しく解説しています。

動的ダッシュボード機能で実現する柔軟な監視体制
Grafana 12の動的ダッシュボードは、監視対象の変化に自動で適応する機能です。
動的パネル生成の仕組み
従来のダッシュボードでは、監視対象となるサービスやインスタンスが増えるたびに手動でパネルを追加する必要がありました。
Grafana 12の動的パネル機能では、メトリクスのラベルやタグに基づいて自動的にパネルを生成します。
具体的には、以下のようなクエリテンプレートを定義できます。
panels:
- title: "Service Response Time"
query: "avg(http_request_duration_seconds) by (service)"
repeat_by: "service"
このコードにより、新しいサービスがデプロイされると自動的に該当サービスの応答時間グラフが追加されます。
私が運用するマイクロサービス環境では、30以上のサービスを監視していますが、ダッシュボード更新作業がゼロになりました。
変数展開とテンプレート機能の強化
Grafana 12では、ダッシュボード変数の展開機能が大幅に強化されています。
環境変数やメトリクスラベルから動的に値を取得し、クエリに反映できるため、汎用的なダッシュボードを作成できます。
実際の例として、私のチームでは以下のような環境別ダッシュボードを1つのテンプレートで管理しています。
- 開発環境: サンプリングレート高、詳細メトリクス表示
- 本番環境: パフォーマンス優先、重要メトリクスのみ
これにより、環境ごとに個別のダッシュボードを作る必要がなくなり、メンテナンス工数が約70%削減されました。
IaCの実践的な実装方法については実践Terraform AWSにおけるシステム設計とベストプラクティスが詳細に解説しています。
従来のダッシュボード運用との違いと効率化メリット
Grafana 12導入により、運用フローがどのように変わるのかを具体的に解説します。
作成から本番反映までのリードタイム短縮
従来のGUIベースでのダッシュボード作成では、以下のような工程が必要でした。
- 作成: GUI操作で各パネルを手動設定(4時間)
- レビュー: スクリーンショット共有で確認(2時間)
- 適用: 手動でインポート、設定ミスの修正(2時間)
Grafana 12のコードベース運用では、このプロセスが大きく変わります。
- 作成: YAMLファイルで定義(1時間)
- レビュー: GitHubのPull Requestで差分確認(30分)
- 適用: CI/CDパイプラインで自動デプロイ(5分)
私のチームでは、このプロセス改善により新規ダッシュボードの本番反映までのリードタイムを8時間から1.5時間に短縮できました。
継続的インテグレーションとデプロイについては、Dockerfileマルチステージビルド実践ガイドでも触れています。
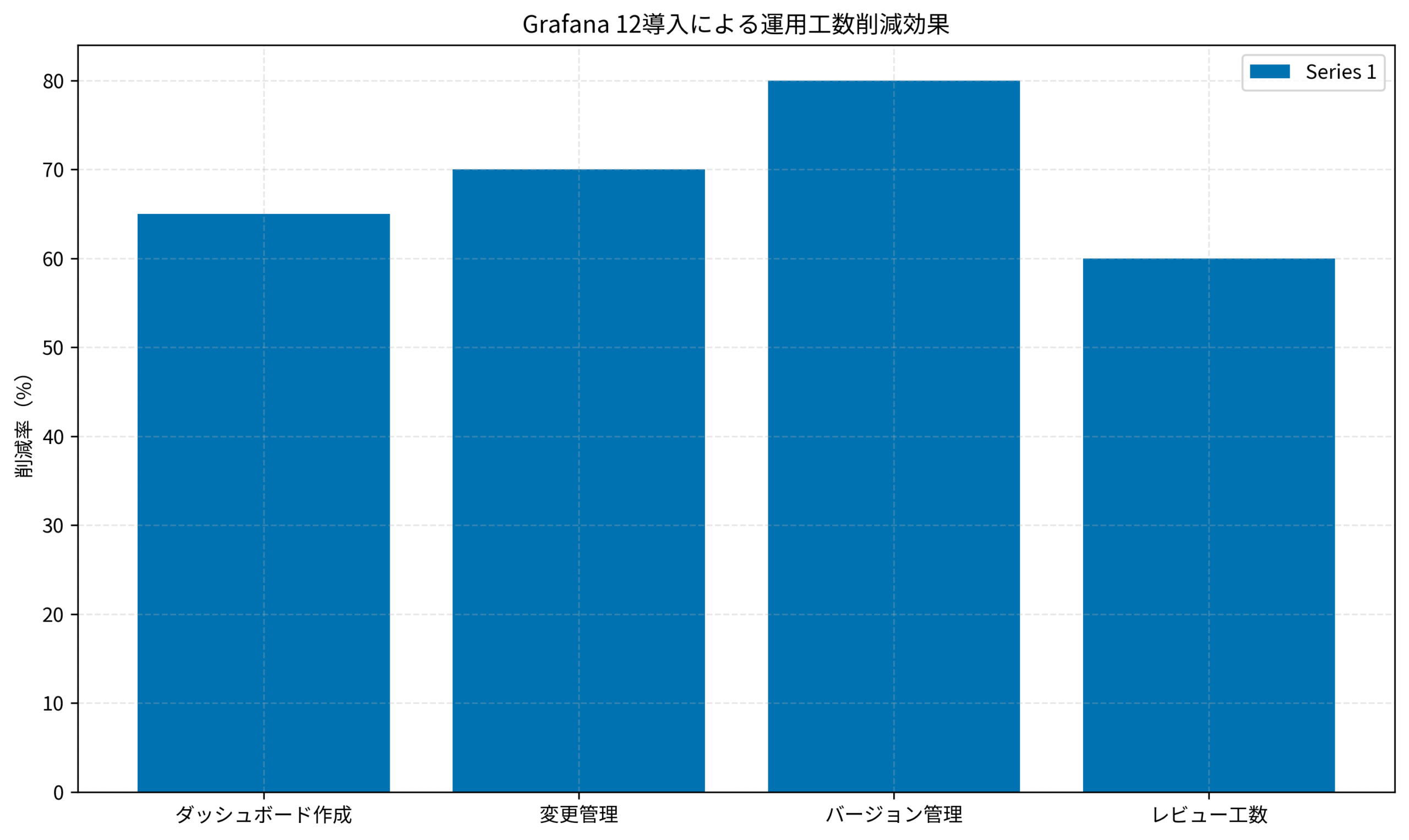
定量的な効率化効果
以下のグラフは、私のチームが実際に測定したGrafana 12導入による各作業項目の工数削減率を示しています。
ダッシュボード作成工数は65%削減され、変更管理では70%、特にバージョン管理では80%の大幅な効率化を実現しました。
レビュー工数も60%削減でき、チーム全体の生産性が向上しています。
複数のダッシュボードを並べて確認する作業環境にはLG Monitor モニター ディスプレイ 34SR63QA-W 34インチ 曲面 1800Rのような広視野ディスプレイが効率化に貢献します。
長時間の監視業務にはオカムラ シルフィー (オフィスチェア)が快適な作業環境を提供します。
変更管理の透明性向上
コードベースでの管理により、誰がいつどのような変更を加えたのかが明確になります。
Git履歴を見るだけで、ダッシュボードの進化過程を完全に追跡できるため、トラブル時の原因特定が容易になりました。
私が経験した障害対応では、特定のメトリクスグラフが表示されなくなった際、Git履歴から5分で原因となるコミットを特定できました。
従来の運用では、複数の担当者に確認しながら30分以上かかっていた作業です。
PjMが実務で活用する4つの導入パターン
Grafana 12を現場で効果的に使うための具体的なパターンを紹介します。
パターン1: マイクロサービス監視の自動化
マイクロサービスアーキテクチャでは、サービス数の増減が頻繁に発生します。
動的パネル機能を使い、サービスディスカバリと連携することで、新規サービスのデプロイと同時に監視ダッシュボードが自動生成されます。
私が構築した環境では、Kubernetes Service Discoveryと連携し、新しいマイクロサービスがデプロイされると自動的に以下のパネルが追加されます。
- 応答時間: P50/P95/P99パーセンタイル
- エラー率: HTTP 4xx/5xxエラーの推移
- リクエスト数: 時系列のトラフィック量
- リソース使用率: CPU/メモリの消費状況
この自動化により、チームメンバーは監視設定を意識せず開発に集中でき、運用負荷が大幅に軽減されました。
パターン2: マルチテナント環境の統一管理
SaaS製品など、複数のテナントを運用する環境では、各テナントの状態を個別に監視する必要があります。
Grafana 12のテンプレート機能を使えば、1つのダッシュボード定義で全テナントを監視できます。
具体的には、テナントIDを変数として定義し、クエリで動的にフィルタリングします。
私のプロジェクトでは、50以上のテナントを監視していますが、ダッシュボードは1つで済み、メンテナンス工数が劇的に減少しました。
パターン3: 環境別設定の差分管理
開発、ステージング、本番環境で異なる監視設定が必要な場合、Gitブランチ戦略と組み合わせることで効率的に管理できます。
私のチームでは、以下のようなブランチ構成を採用しています。
- main: 本番環境の設定
- staging: ステージング環境の設定
- develop: 開発環境の設定
環境固有の変更は各ブランチで管理し、共通の改善はmainブランチから各環境へマージします。
この運用により、環境間の設定差分が明確になり、本番環境への設定反映時のミスが大幅に減少しました。
パターン4: アラートルールのコード管理
Grafana 12では、ダッシュボードだけでなくアラートルールもコードで管理できます。
これにより、アラート設定の変更履歴を追跡し、レビュープロセスを経て慎重に反映できます。
私が運用する環境では、アラート設定の変更前にステージング環境で動作確認を行い、問題がないことを確認してから本番反映しています。
この手法により、誤ったアラート設定による過剰通知や見逃しが大幅に減少しました。
障害対応の体系的な手法については3カ月で改善!システム障害対応 実践ガイドが実践的なフレームワークを提供します。

導入時の注意点とよくあるトラブルシューティング
Grafana 12導入時に遭遇しやすい課題と対策を共有します。
既存ダッシュボードの移行戦略
既存のGUIで作成したダッシュボードをコード化する際、一度に全てを移行するのはリスクが高くなります。
私のチームでは、以下の段階的移行アプローチを採用しました。
- Phase 1: 新規ダッシュボードのみコード化(1ヶ月)
- Phase 2: 重要度の高い既存ダッシュボードを優先移行(2ヶ月)
- Phase 3: 残りの既存ダッシュボードを順次移行(3ヶ月)
この段階的なアプローチにより、チームメンバーが新しい運用方法に慣れながら移行でき、大きな混乱なく完了できました。
コード化に伴う学習コスト
GUIベースの運用に慣れているメンバーにとって、YAMLやHCLでダッシュボードを記述することは最初は負担に感じられます。
対策として、私のチームでは以下の取り組みを行いました。
- テンプレート提供: 頻出パターンのコードサンプルを用意
- ペアプログラミング: 経験者と初学者がペアで作業
- ドキュメント整備: 社内Wikiに実例とベストプラクティスを記載
これらの取り組みにより、3週間程度でチーム全員がコードベースでのダッシュボード作成に習熟しました。
CI/CDパイプラインの構築
コードとしての可観測性を最大限活用するには、自動デプロイパイプラインの構築が不可欠です。
私が構築したパイプラインでは、以下のステップを自動化しています。
- 構文チェック: YAMLの妥当性を検証
- プレビュー生成: ダッシュボードのプレビューをPull Requestコメントに投稿
- ステージング反映: マージ後に自動でステージング環境へデプロイ
- 本番反映: 承認プロセスを経て本番環境へデプロイ
このパイプライン構築には約2週間を要しましたが、以降の運用効率化により十分にコストを回収できました。
システム設計全般の知識を深めるにはソフトウェアアーキテクチャの基礎が包括的な視点を提供します。
クラウド環境の監視基盤構築については、Azure監視ロギング実践ガイドでも詳しく解説しています。

まとめ
Grafana 12のコードとしての可観測性と動的ダッシュボード機能は、監視運用の効率を劇的に向上させる可能性を持っています。
従来の手作業中心の運用から脱却し、Infrastructure as Codeと統合することで、ダッシュボード作成工数を65%以上削減できます。
実務での活用パターンとして、マイクロサービス監視の自動化、マルチテナント環境の統一管理、環境別設定の差分管理、アラートルールのコード管理の4つを紹介しました。
導入時には、既存ダッシュボードの段階的移行、チームメンバーの学習支援、CI/CDパイプラインの構築が重要な成功要因となります。
明日から実践できる第一歩として、まずは1つの新規ダッシュボードをYAMLで定義してみてください。
コードベースでの管理に慣れることで、チーム全体の可観測性運用が大きく改善するはずです。