IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
「AIエージェントを試したいけど、API料金が気になる」「社内データをクラウドに送りたくない」——こうした悩みを抱えるエンジニアの方は少なくありません。
実は、OllamaとCrewAIを組み合わせれば、完全ローカル環境でマルチエージェントシステムを構築できます。API課金ゼロ、データ外部送信ゼロで、複数のAIエージェントが協調して複雑なタスクを自律的に処理する仕組みが手に入るのです。
2025年後半からAIエージェントの実用化が急速に進み、LangChain、AutoGen、CrewAIといったフレームワークが次々と登場しています。中でもCrewAIは「役割ベースのエージェント設計」という直感的なアプローチで、エンジニアからの支持を集めています。
本記事では、OllamaでローカルLLMを動かし、CrewAIでマルチエージェントシステムを構築する手順を、実践的なコード例とともに解説します。
ローカルAIエージェントの全体像と背景
IT女子 アラ美AIエージェントとは、与えられた目標に対して自律的に思考・判断・行動するAIシステムのことです。従来のチャットボットが「質問→回答」の1往復で完結するのに対し、エージェントは複数のステップを自ら計画し、ツールを使い、結果を検証しながらタスクを遂行します。
マルチエージェントシステムでは、さらに複数の専門エージェントが役割分担して協調動作します。たとえば「リサーチャー」がWeb検索で情報を収集し、「ライター」がその情報を元に記事を執筆し、「エディター」が品質チェックを行う——といった分業が可能です。CursorでローカルLLMを活用する方法を解説した記事でも触れた通り、ローカルLLMの性能は飛躍的に向上しており、エージェント用途でも十分な品質を発掮できます。ローカルでAIエージェントを動かすメリットは以下の3点です。
- コスト削減:API課金が発生しないため、大量のリクエストを気兼ねなく実行できる
- プライバシー保護:社内データや個人情報がクラウドに送信されないため、セキュリティポリシーに準拠しやすい
- カスタマイズ性:モデルの選択やファインチューニングを自由に行える
IT女子 アラ美前提条件と環境整理
本記事で構築するローカルAIエージェント環境の前提条件を整理します。
ハードウェア要件
- 最小構成:RAM 16GB以上、VRAM 8GB以上のGPU(7B〜13Bモデル向け)
- 推奨構成:RAM 32GB以上、VRAM 24GB以上のGPU(70Bモデル向け)
- CPU推論:GPUがなくてもOllamaはCPU推論に対応(ただし速度は大幅に低下)
ソフトウェア要件
- Python:3.10以上
- Ollama:0.5.x以上
- CrewAI:0.80.x以上
- OS:macOS、Linux、Windows(WSL2推奨)
Ollamaが未導入の方は、DeepSeek R1をOllamaで動かす方法を解説した記事で基本的なセットアップ手順を詳しく紹介していますので、そちらを先にご確認ください。
IT女子 アラ美ステップ1:OllamaとCrewAIの基本セットアップ
まずはOllamaでローカルLLMを起動し、CrewAIから接続する基本構成を構築します。
Ollamaのモデル準備
エージェント用途では、指示追従性が高く、ツール呼び出しに対応したモデルを選ぶことが重要です。推奨モデルは以下の通りです。
- llama3.1:8b:軽量で高速、基本的なエージェントタスクに最適
- qwen2.5:32b:バランス型、複雑な推論にも対応
- llama3.1:70b:高精度、GPT-4oに匹敵する性能
# モデルのダウンロード
ollama pull llama3.1:8b
# 動作確認
ollama run llama3.1:8b "Hello, are you ready to be an agent?"
CrewAIプロジェクトの初期化
# 仮想環境の作成
python3 -m venv .venv
source .venv/bin/activate
# CrewAIのインストール
pip install crewai crewai-tools
Ollamaとの接続設定
CrewAIからOllamaのローカルLLMを使用するには、LiteLLMのOllamaプロバイダーを経由します。
from crewai import Agent, Task, Crew, LLM
# OllamaのローカルLLMを設定
llm = LLM(
model="ollama/llama3.1:8b",
base_url="http://localhost:11434"
)
# エージェントの定義
researcher = Agent(
role="リサーチャー",
goal="与えられたトピックについて正確な情報を収集する",
backstory="あなたは経験豊富なリサーチャーです。信頼性の高い情報源から事実を収集し、要点を整理することが得意です。",
llm=llm,
verbose=True
)
# タスクの定義
research_task = Task(
description="AIエージェントの最新トレンドについて調査し、主要な3つのポイントをまとめてください。",
expected_output="AIエージェントの最新トレンドに関する3つの主要ポイントのレポート",
agent=researcher
)
# Crewの実行
crew = Crew(
agents=[researcher],
tasks=[research_task],
verbose=True
)
result = crew.kickoff()
print(result)
エージェントに外部ツールを接続する際は、MCPサーバーの自作方法を理解しておくと設計がスムーズになります。
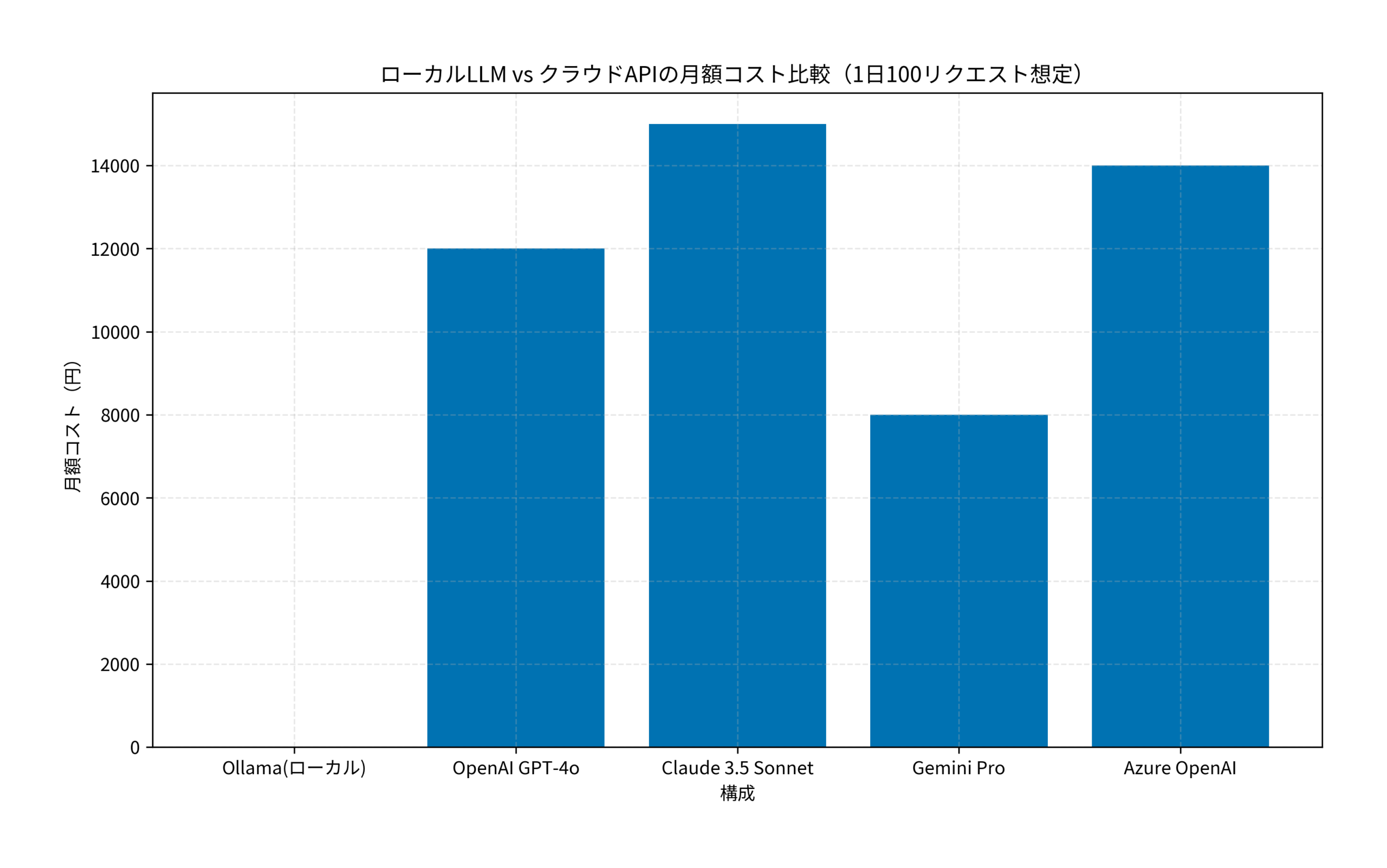
上のグラフの通り、Ollamaを使ったローカル構成では月額コストが実質ゼロになります。1日100リクエスト規模の開発・テスト用途であれば、クラウドAPIと比較して年間10万円以上のコスト削減が見込めます。
IT女子 アラ美ステップ2:マルチエージェント協調の実装
基本セットアップができたら、複数エージェントが協調して動作するマルチエージェントシステムを構築します。ここでは「技術記事の自動リサーチ&レビュー」を例に実装します。
役割ベースのエージェント設計
CrewAIの強みは、各エージェントに明確な役割(Role)・目標(Goal)・背景(Backstory)を設定できる点です。これにより、各エージェントが自分の専門領域に集中した出力を生成します。
from crewai import Agent, Task, Crew, Process, LLM
llm = LLM(
model="ollama/llama3.1:8b",
base_url="http://localhost:11434"
)
# リサーチャーエージェント
researcher = Agent(
role="シニアリサーチャー",
goal="最新の技術トレンドを正確に調査し、エビデンスに基づいたレポートを作成する",
backstory="あなたは10年以上の経験を持つ技術リサーチャーです。複雑な技術トピックを分かりやすく整理し、信頼性の高い情報を提供することに定評があります。",
llm=llm,
allow_delegation=False,
verbose=True
)
# ライターエージェント
writer = Agent(
role="テクニカルライター",
goal="リサーチ結果を元に、読者にとって価値のある技術記事を執筆する",
backstory="あなたはエンジニア向けメディアで活躍するテクニカルライターです。技術的な正確性を保ちながら、初心者にも分かりやすい文章を書くことが得意です。",
llm=llm,
allow_delegation=False,
verbose=True
)
# レビュアーエージェント
reviewer = Agent(
role="品質レビュアー",
goal="記事の技術的正確性、論理的整合性、読みやすさを検証する",
backstory="あなたはコードレビューと技術文書のレビューを専門とするシニアエンジニアです。細部まで見逃さない正確さと、建設的なフィードバックで知られています。",
llm=llm,
allow_delegation=False,
verbose=True
)
タスクの連鎖とプロセス管理
CrewAIでは、タスクをsequential(順次実行)またはhierarchical(階層型)で実行できます。
# タスク定義
research_task = Task(
description="Ollamaを使ったローカルAIエージェントの最新動向を調査してください。主要なフレームワーク、性能ベンチマーク、実用事例を含めてください。",
expected_output="技術トレンドレポート(500文字以上)",
agent=researcher
)
writing_task = Task(
description="リサーチ結果を元に、エンジニア向けの技術記事を執筆してください。具体的なコード例を含め、実践的な内容にしてください。",
expected_output="技術記事の本文(1000文字以上)",
agent=writer,
context=[research_task]
)
review_task = Task(
description="執筆された記事をレビューしてください。技術的な誤り、論理の飛躍、改善点を指摘してください。",
expected_output="レビューコメントと改善提案のリスト",
agent=reviewer,
context=[writing_task]
)
# Crewの構成と実行
crew = Crew(
agents=[researcher, writer, reviewer],
tasks=[research_task, writing_task, review_task],
process=Process.sequential,
verbose=True
)
result = crew.kickoff()
エージェントの実行結果は、SupabaseとPostgreSQLを活用したAIエージェント構築の記事で紹介した手法でデータベースに永続化すると、継続的な改善サイクルを回せるようになります。
IT女子 アラ美実装後の効果検証(ケーススタディ)
IT女子 アラ美中村さん(仮名・33歳・バックエンドエンジニア・経験9年)のケース
状況(Before)
- 社内ドキュメントのレビュー作業に週あたり約8時間を費やしていた
- OpenAI APIの月額コストが約3万円に達していた
- セキュリティポリシーにより社内データをクラウドAPIに送信できない部署があった
行動(Action)
- Ollama + Llama 3.1 70Bをオンプレミスサーバー(RTX 4090搭載)に導入
- CrewAIで「ドキュメント分析エージェント」「改善提案エージェント」「フォーマットチェックエージェント」の3体構成を構築
- 社内GitLabのWebhookと連携し、MRが作成されるたびに自動レビューを実行する仕組みを実装
結果(After)
- レビュー作業時間が週8時間から週2時間に短縮(75%削減)
- API課金が月額3万円からゼロに(年間36万円のコスト削減)
- セキュリティポリシーに完全準拠し、全部署での利用が可能になった
中村さんは振り返ります。「最初からローカル構成で検証していれば、セキュリティ審査の手戻りなく全部署に展開できた。クラウドAPIは手軽だが、社内データを扱う場面ではローカルファーストで設計するのが正解だった」。
さらに、Claude Codeの実践スキルガイドで紹介したAIコーディング支援と組み合わせると、開発プロセス全体のAI活用が加速します。
IT女子 アラ美さらなる実践・活用に向けて
ローカルAIエージェントの基盤が構築できたら、さらに発展させるためのステップを紹介します。
モデルのファインチューニング
特定のドメイン(法務、医療、金融など)に特化したエージェントを構築する場合、ベースモデルをファインチューニングすることで精度が大幅に向上します。OllamaではModelfileを使ってカスタムモデルを作成できます。
RAG(検索拡張生成)との統合
エージェントにRAGを組み込むことで、社内ドキュメントやナレッジベースを参照しながらタスクを実行できるようになります。ChromaDBやFAISSなどのベクトルデータベースとの連携が効果的です。
監視とログ管理
本番運用では、エージェントの実行ログ、トークン消費量、エラー率を監視する仕組みが不可欠です。PrometheusとGrafanaを使った監視ダッシュボードの構築を推奨します。
こうした実装経験は、エンジニアの技術ブランディング戦略で解説した通りGitHubやブログで発信することで、エンジニアとしての市場価値向上にもつながります。AIエージェント構築スキルを活かしてフリーランスで高単価案件を狙うならフリーランスエージェント5社比較ガイドも参考にしてください。
IT女子 アラ美よくある質問(FAQ)
Q. OllamaとCrewAIの組み合わせで商用利用は可能ですか?
Ollama自体はオープンソースで商用利用可能です。ただし、使用するLLMモデルのライセンスを個別に確認する必要があります。Llama 3.1はMeta Llama 3.1 Community Licenseに基づき、月間アクティブユーザー7億人未満であれば商用利用が許可されています。
Q. CrewAIの無料版と有料版(Enterprise)の違いは何ですか?
CrewAIのオープンソース版(pip install crewai)は機能制限なく無料で利用できます。Enterprise版はエージェントのデプロイ管理、モニタリングダッシュボード、チームコラボレーション機能が追加されたクラウドサービスです。本記事で解説した内容は全て無料版で実行できます。
Q. ローカルLLMのレスポンスが遅い場合、どう改善できますか?
モデルサイズを小さくする(70B→8B)、量子化モデル(Q4_K_M等)を使う、GPUメモリに収まるサイズのモデルを選ぶ、の3つが基本的な対策です。また、Ollamaのnum_ctxパラメータでコンテキスト長を短くすることでも速度が改善します。
自分のスキルを活かしてフリーランスとして独立したい方は、以下の5社を比較して最適なエージェントを見つけましょう。
| 比較項目 | techadapt | Midworks | レバテックフリーランス | フリーランスボード | IT求人ナビ |
|---|---|---|---|---|---|
| 単価帯 | 月60〜120万円高単価特化 | 月50〜90万円中〜高単価 | 月60〜120万円Web系直請け中心 | 月40〜150万円30万件横断検索 | AI診断適正単価を自動提案 |
| マージン | 10〜20%公開 | 10〜15%公開 | 非公開・案件ごと | —検索サイト | 案件ごと |
| 保障・福利厚生 | 限定的案件品質で勝負 | 正社員並み社保・交通費・研修 | 基本的健診・税務サポート | —スカウト機能あり | 相談サポートチャット・オンライン |
| 対応エリア | 首都圏東京・神奈川中心 | 首都圏+関西大阪・名古屋 | 首都圏中心+リモート主要都市対応 | 全国対応リモート・週3可 | 全国対応リモートあり |
| おすすめ度 | 経験3年以上 | 独立初期 | Web系経験者 | A相場把握に | B+初心者向け |
| 公式サイト | 案件を探す | 案件を探す | 案件を探す | 案件を検索 | AI診断する |
IT女子 アラ美まとめ
本記事では、OllamaとCrewAIを使ってローカル環境でマルチエージェントシステムを構築する方法を解説しました。
- Ollama + CrewAIで、API課金ゼロ・データ外部送信ゼロのAIエージェント環境が構築できる
- 役割ベースのエージェント設計により、リサーチ・執筆・レビューなどの複雑なワークフローを自動化できる
- ケーススタディでは、レビュー時間75%削減・年間36万円のコスト削減を実現した
まずはOllamaでモデルをダウンロードし、CrewAIで単一エージェントを動かすところから始めてみてください。ローカルAIエージェントの世界は、思っている以上に実用的で、すぐに業務改善に活かせるはずです。
IT女子 アラ美