お疲れ様です!IT業界で働くアライグマです!
TikTokやYouTube Shortsのトレンド分析、手作業でやっていませんか?
動画のメタデータ(再生数、いいね数、ハッシュタグ)をExcelにコピペする作業は、エンジニアにとって苦行でしかありません。
特に、マーケティング部門やクライアントから「毎日このハッシュタグの動画をリストアップして」と頼まれると、それだけで午前中の業務が終わってしまいます。
今回は、Video Scraping APIs とPythonを使って、この苦行を「秒」で終わらせるトレンド収集基盤の作り方を紹介します。
動画データ分析の全体像とメリット
動画プラットフォームのデータ収集は、マーケティングやコンテンツ制作において重要ですが、技術的な壁がいくつも存在します。
公式APIは取得数に厳しい制限があり、個人開発レベルでは満足にデータを取れないことが多いです。
一方で、SeleniumやPlaywrightを使った自作のスクレイピングは、プラットフォーム側のUI変更やCAPTCHA(ボット対策)によって頻繁に動かなくなります。
そのメンテナンスコストは計り知れません。
Video Scraping APIsのような特化型サービスを利用することで、複雑なクローリング処理をAPIプロバイダーに任せ、自分たちはデータ分析という「本質」に集中できるようになります。
- 複数のSNS(TikTok, Instagram, YouTube)のデータを統一的なJSONフォーマットで取得できるため、コードの再利用性が高まります。
- IPローテーションやCAPTCHA対策などの面倒なスクレイピング保守コストが完全になくなります。
- サーバーレス環境(AWS Lambdaなど)に簡単にデプロイでき、運用コストを安く抑えられます。
特に、動画生成AIなどが流行する今、トレンドをリアルタイムに掴むデータの価値は、以前よりも遥かに高まっています。
以下の記事でも解説している動画生成AIツールと組み合わせれば、トレンド検知から動画作成までをAIエージェントに任せることも夢ではありません。
詳しくは LTX-2でAI動画生成をローカル環境で動かす:高品質な一貫性を持つ動画作成ガイド をご覧ください。
 IT女子 アラ美
IT女子 アラ美前提条件と環境整理
今回はPythonを使用してAPI経由でデータを取得し、Pandasで加工するフローを構築します。
想定する読者は、Pythonの基本的な構文が読めるエンジニアや、Excel作業から脱却したいデータアナリストです。
スクレイピングの経験がなくても問題ありませんが、HTTPリクエストの基礎知識があるとスムーズです。
必要な環境
- Python 3.10以上:型ヒントや最新のライブラリ機能を活用するために推奨します。
- pandasライブラリ:取得したJSONデータを表形式に変換し、CSV出力や集計を行うために必須です。
- requestsライブラリ:APIへのHTTPリクエストを送信するために使用します。
- Video Scraping APIs(RapidAPI等で契約)のAPIキー:今回は例としてRapidAPI上のサービスを想定します。
APIキーの管理には python-dotenv などを使って環境変数から読み込むようにしましょう。
ソースコードにAPIキーを直書きしてGitHubにアップロードしてしまう事故を防ぐため、セキュリティには十分注意してください。
環境変数の安全な扱い方や、サーバー構築の基礎については、以下の記事も参考にしてください。
ローカルサーバーの構築は Model Context Protocol (MCP) 実践ガイド:ローカルDBとAIを接続する自作サーバー構築 で詳しく解説しています。
IT女子 アラ美ステップ1:基本的な実装・設定
まずは、特定のキーワードに関連する動画リストを取得する基本的なスクリプトを作成します。
ここでは requests を使ってAPIを叩き、結果をJSONで受け取ります。
自作でスクレイピングをする場合、ここでブラウザ操作のコードを書く必要がありますが、APIならたった数行で完結します。
以下のコードは、キーワード「Python programming」に関連する動画を検索し、タイトル、再生数、いいね数を抽出してデータフレームとして表示する例です。
import requests
import pandas as pd
import os
from dotenv import load_dotenv
# .envファイルからAPIキーを読み込み
load_dotenv()
def fetch_trending_videos(keyword):
# RapidAPIのエンドポイント例(実際のエンドポイントに合わせて変更してください)
url = "https://example-video-scraping-api.p.rapidapi.com/search"
headers = {
"X-RapidAPI-Key": os.getenv("RAPIDAPI_KEY"),
"X-RapidAPI-Host": "example-video-scraping-api.p.rapidapi.com"
}
# パラメータ設定:クエリと取得件数
params = {"query": keyword, "limit": "50"}
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status() # エラーチェック
data = response.json()
return data.get('data', [])
except Exception as e:
print(f"エラーが発生しました: {e}")
return []
# メイン処理
if __name__ == "__main__":
videos = fetch_trending_videos("Python programming")
if videos:
# Pandas DataFrameに変換して見やすく整形
df = pd.DataFrame(videos)
# 必要なカラムのみ抽出
print(df[['title', 'views', 'likes']].head())
# CSVに保存する場合
# df.to_csv("videos.csv", index=False)
else:
print("動画データが見つかりませんでした。")
このスクリプトを実行するだけで、指定したキーワードの動画データが表形式で手に入ります。
ブラウザを立ち上げる必要もなければ、ヘッドレスモードの調整に悩む必要もありません。
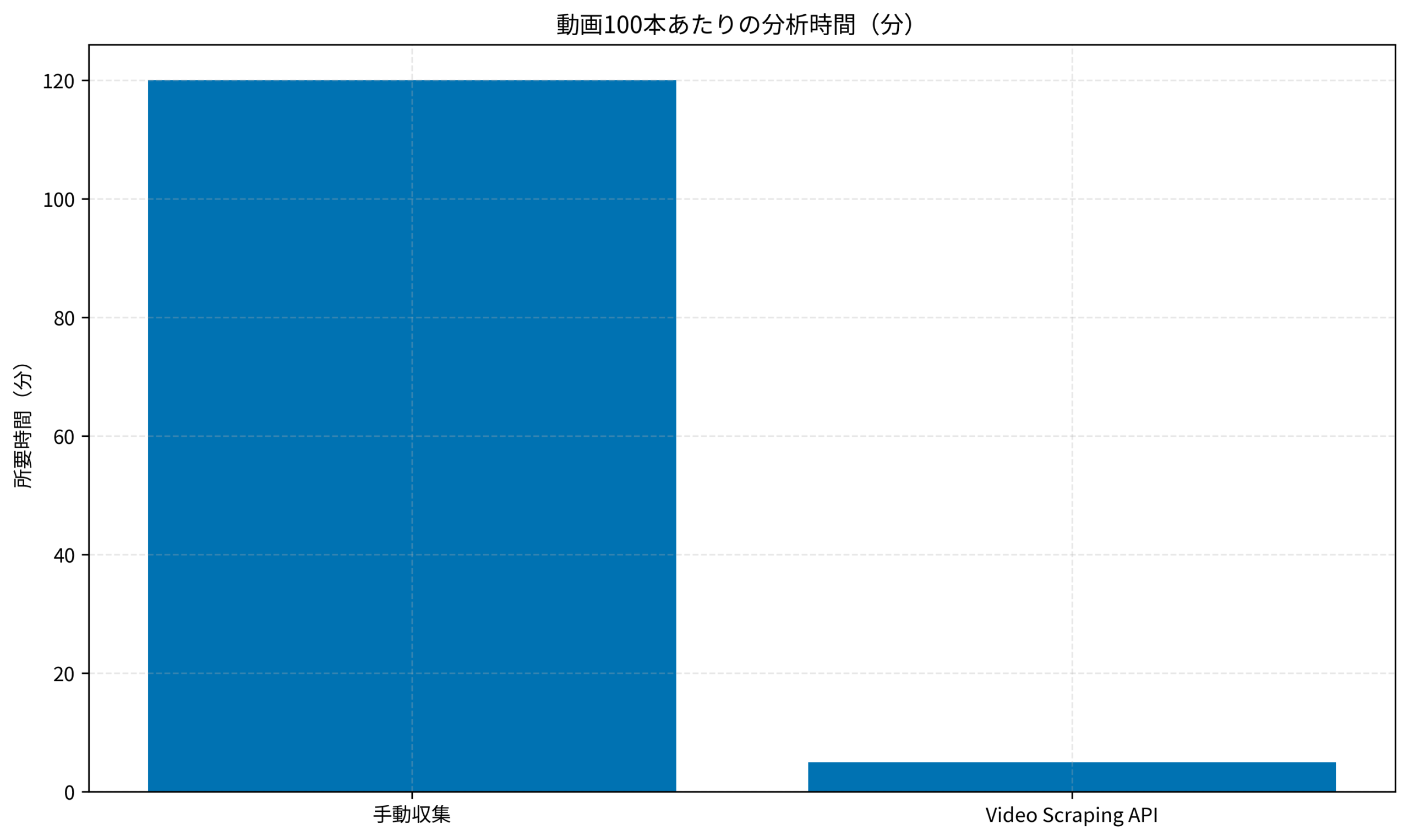
以下は、手動でデータを集めた場合とAPIを使用した場合の時間コストの比較グラフです。
100本の動画データを集める時間は、手動では約120分(1本1分少々)かかりますが、APIならわずか5分(実行時間+確認含め)で完了します。
この差は圧倒的であり、浮いた時間を分析や次のアクションプラン策定に充てることができます。
さらに高度なブラウザ操作が必要な場合は、自律型AI活用も検討できます。
詳しい手順は browser-use/agent-sdkでLLMブラウザ自動化エージェントを構築する もあわせてご覧ください。
IT女子 アラ美ステップ2:発展的な活用・応用パターン
単にデータを取るだけでなく、継続的に監視することで「バズる予兆」を検知できます。
「今日の再生数」と「昨日の再生数」を比較し、急激に伸びている動画(バイラル動画)をいち早く見つけることができれば、マーケティング施策に即座に反映できます。
ここでは、CronやGitHub Actionsでスクリプトを定期実行し、前日比で急激に再生数が伸びた動画をSlackに通知するシステムのアイデアを紹介します。
def notify_slack(message):
webhook_url = os.getenv("SLACK_WEBHOOK_URL")
requests.post(webhook_url, json={"text": message})
# 再生数が1万回以上伸びた動画を通知するロジックの例
for video in videos:
# 実際にはDBなどに保存した過去データと比較します
growth = video['views'] - previous_views.get(video['id'], 0)
if growth > 10000:
msg = f"🚀 急上昇動画を検知しました: {video['title']} (+{growth} views)"
notify_slack(msg)
このように、データ収集を自動化した先には「通知」や「レポート生成」の自動化が待っています。
ここまで作り込めば、あなたは立派な「データエンジニア」としての価値を提供できるようになるでしょう。
APIコストの管理も重要です。データを無数に集めるとすぐにAPI上限に達してしまいます。
以下の記事で紹介している可視化ツールなどを使い、コストパフォーマンスを意識した運用を心がけましょう。
このコスト管理手法については SherlockでLLMアプリの通信・トークン消費を完全可視化:APIコスト削減 が役立ちます。
IT女子 アラ美実装後の効果検証(ケーススタディ)
実際にこの Video Scraping API 基盤を導入したマーケティングチームの事例を紹介します。
ごく小規模なチームでしたが、自動化によって大きな成果を挙げることができました。
状況(Before)
導入前、チームは疲弊していました。
- マーケティング担当者が毎日2時間かけてTikTokとYouTubeを巡回し、スプレッドシートに再生数やコメント数を手入力していました。
- データの粒度が粗く「週次」での推移しか追えなかったため、トレンド発生から対策までのタイムラグが大きくなっていました。
- 手入力によるミスも多発し、データの信頼性が低い状態でした。
行動(Action)
そこで、PythonとAPIを用いた自動収集システムを構築しました。
- Video Scraping APIを導入し、毎朝6時に指定キーワードのデータを全自動で取得・DB保存するバッチを作成しました。
- Streamlitを使って簡易的な可視化ダッシュボードを作成し、エンジニア以外でもブラウザから最新トレンドを確認できるようにしました。
- 急上昇キーワードをSlackに通知するBotを稼働させました。
結果(After)
効果は劇的でした。
- データ収集作業時間がゼロになり、月間約40時間の工数を削減することに成功しました。
- トレンド発生から記事化までのリードタイムが短縮し、メディアのPV数が前月比1.5倍に増加しました。
- 空いた時間で動画の中身の分析や企画立案に注力できるようになり、チームの士気が向上しました。
このように、単純作業をプログラムに置き換えることは、単なるコスト削減以上の価値(機会損失の防止、創造性の向上)を生み出します。
エンジニアとしての評価を高めるためにも、こうした「実績」を作ることは非常に重要です。
アウトプットの戦略については、以下の記事も参考にしてください。
戦略の詳細は 『技術力はあるのに評価されない』を防ぐアウトプット戦略 で解説しています。
IT女子 アラ美さらなる実践・活用に向けて
今回はAPIによる収集がメインでしたが、収集したデータを生成AI(LLM)に渡して「なぜバズっているのか」を分析させるのも面白いでしょう。
動画のタイトルや説明文、コメント欄の感情分析を行えば、より深いインサイトが得られます。
技術の組み合わせで、システムはさらに強力になります。
また、こうした自動化スキルを活かして、フリーランスとして活動することも視野に入れてみてください。
多くの企業がデータ収集や分析の自動化に課題を抱えています。
詳しくは Model Context Protocol (MCP) 実践ガイド などで、さらに高度なAI連携についても学んでみてください。
IT女子 アラ美キャリアパスと案件獲得
今回紹介したようなデータ収集・自動化のスキルは、フリーランス市場で非常に高い需要があります。
特に「業務効率化」や「データ分析基盤構築」の案件は単価も安定しています。
自分のスキルがどれくらいの価値になるのか、まずはエージェントに相談してみるのがおすすめです。
キャリアについては Staff+エンジニアのキャリア戦略:技術職として経営にインパクトを与える「影響力の広げ方」 も参考にしてください。
自分のスキルを活かしてフリーランスとして独立したい方は、以下の5社を比較して最適なエージェントを見つけましょう。
| 比較項目 | techadapt | Midworks | レバテックフリーランス | フリーランスボード | IT求人ナビ |
|---|---|---|---|---|---|
| 単価帯 | 月60〜120万円高単価特化 | 月50〜90万円中〜高単価 | 月60〜120万円Web系直請け中心 | 月40〜150万円30万件横断検索 | AI診断適正単価を自動提案 |
| マージン | 10〜20%公開 | 10〜15%公開 | 非公開・案件ごと | —検索サイト | 案件ごと |
| 保障・福利厚生 | 限定的案件品質で勝負 | 正社員並み社保・交通費・研修 | 基本的健診・税務サポート | —スカウト機能あり | 相談サポートチャット・オンライン |
| 対応エリア | 首都圏東京・神奈川中心 | 首都圏+関西大阪・名古屋 | 首都圏中心+リモート主要都市対応 | 全国対応リモート・週3可 | 全国対応リモートあり |
| おすすめ度 | 経験3年以上 | 独立初期 | Web系経験者 | A相場把握に | B+初心者向け |
| 公式サイト | 案件を探す | 案件を探す | 案件を探す | 案件を検索 | AI診断する |
IT女子 アラ美まとめ
Video Scraping APIsを活用すれば、泥臭いデータ収集作業から解放され、スマートな開発ライフを送ることができます。
- APIを使えば、複数SNSのデータを統一フォーマットで扱え、保守の手間が激減します。
- Pythonスクリプト数行で自動化が可能であり、初心者でも導入しやすいのが特徴です。
- 余った時間で「データの中身」の分析や、新しいサービスの開発に注力できるようになります。
ぜひ、身の回りの単純作業をPythonで自動化してみてください。その経験は必ずエンジニアとしての資産になります。
手動作業で消耗するのは今日で終わりにしましょう。
IT女子 アラ美