
 IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
論文や技術書を読むだけでは身につかない。インプットした知識を定着させるには、自分専用の学習アシスタントが必要です。
「技術書を読んでもすぐ忘れてしまう」「論文を山ほど読んでいるのに体系的な理解が進まない」──エンジニアなら誰しも経験する悩みではないでしょうか。
最近GitHubでトレンド入りしたDeepTutorは、この問題を解決するオープンソースの教育AIアシスタントです。RAG(Retrieval-Augmented Generation)とナレッジグラフを組み合わせて、アップロードした文書から自分専用の学習環境を構築できます。
本記事では、DeepTutorの仕組みからセットアップ、実践的な活用法まで解説します。
DeepTutorとは:RAGベースパーソナライズ学習の新潮流
IT女子 アラ美AI学習アシスタントで知識の定着率を30%から80%に引き上げる
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
DeepTutorは、香港大学のHKUDSラボが公開したオープンソースのAI学習アシスタントです。2025年12月にGitHubでトレンド入りし、急速に注目を集めています。
従来のRAG Q&Aと何が違うのか
一般的なRAGシステムは「質問→検索→回答」という単純なパイプラインですが、DeepTutorは学習に特化した多層アーキテクチャを採用しています。
- Dual-Loop Reasoning:RAG検索、Web検索、論文検索、コード実行を組み合わせたマルチエージェント推論
- ナレッジグラフ統合:エンティティ間の関係性をマッピングし、概念の連結を可視化
- セッション記憶:学習進捗を追跡し、文脈に応じたパーソナライズ応答
主要機能の概要
DeepTutorが提供する機能は大きく5つに分類されます。
- Massive Document Q&A:教科書・論文・技術マニュアルをアップロードしてナレッジベース構築
- Interactive Learning Visualization:複雑な概念をインタラクティブに可視化・分解
- Practice Problem Generator:現在の理解度に合わせた練習問題を自動生成
- Deep Research:トピック探索と文献レビューの自動化
- Idea Generation:研究アイデアの発見と知識ギャップの特定
RAG技術の深掘りについては、コンテキストエンジニアリング入門:AIエージェントの精度を高める設計パターンと実装戦略も参考になります。
IT女子 アラ美DeepTutorのアーキテクチャと技術スタック
DeepTutorは4層構造のアーキテクチャで構成されています。実装を理解するために、各層の役割を整理しましょう。
User Interface Layer
フロントエンドはNext.jsで構築されています。ダークモード対応で、質問応答のインタラクションがリアルタイムに表示されます。
- 双方向クエリ応答:シンプルなチャットUIでドキュメントと対話
- 構造化出力:複雑な情報を整理されたフォーマットで表示
Intelligent Agent Modules
中核となるエージェントは以下の機能を担います。
- Problem Solving Agent:ステップバイステップで問題を解決
- Assessment Agent:カスタムテストを生成
- Research Agent:Web検索・論文検索で情報収集
- Guided Learning Agent:可視化とパーソナライズ応答
Tool Integration Layer
外部ツールとの連携を担当します。
- RAGハイブリッド検索:ベクトル検索とキーワード検索の組み合わせ
- リアルタイムWeb検索:最新情報を取得
- 学術論文データベース:Semantic Scholar等と連携
- Pythonコード実行:計算やデータ分析を実行
- PDFパーシング:ドキュメント解析
Knowledge & Memory Foundation
永続化レイヤーはナレッジグラフとベクトルストアで構成されます。
- Knowledge Graph:エンティティと関係性のマッピング(LightRAGベース)
- Vector Store:埋め込みベースのセマンティック検索
- Memory System:セッション状態と引用追跡
エージェント設計については、Amazon Bedrock AgentCoreでAIエージェントを本番運用するも参考になります。
IT女子 アラ美DeepTutorのセットアップ手順
実際にDeepTutorをローカル環境で動かしてみましょう。Python 3.10とNode.jsが必要です。
Step 1: リポジトリのクローンと環境構築
# リポジトリのクローン
git clone https://github.com/HKUDS/DeepTutor.git
cd DeepTutor
# conda環境の作成(推奨)
conda create -n aitutor python=3.10
conda activate aitutorStep 2: 依存関係のインストール
自動インストールスクリプトが用意されています。
# 自動インストール(推奨)
bash scripts/install_all.sh
# または手動インストール
pip install -r requirements.txt
npm installStep 3: 環境変数の設定
OpenAI APIキーなどの環境変数を設定します。
# .env.exampleをコピー
cp .env.example .env
# .envファイルを編集してAPIキーを設定
# OPENAI_API_KEY=sk-xxxxx
# SEMANTIC_SCHOLAR_API_KEY=xxxxx(オプション)Step 4: アプリケーションの起動
# Webインターフェース起動(フロントエンド + バックエンド)
python scripts/start_web.py
# バックエンド: http://localhost:8001
# フロントエンド: http://localhost:3782Step 5: ナレッジベースの作成
ブラウザでhttp://localhost:3782/knowledgeにアクセスし、「New Knowledge Base」をクリックしてドキュメントをアップロードします。PDF、論文、技術書など複数ファイルの一括アップロードも可能です。
LLM活用の基礎については、GPT-1からGPT-5.2までの特殊トークン解説も参考になります。
IT女子 アラ美ケーススタディ:機械学習論文の体系的理解にDeepTutorを活用
IT女子 アラ美実際にDeepTutorを使って学習効率を改善した事例を紹介します。
状況(Before)
木下さん(仮名・30歳・MLエンジニア)は、業務でRAGシステムを構築することになりました。しかし、関連論文が多すぎて体系的に理解できず、どこから手をつけるべきかわからない状態でした。
- 読むべき論文:RAG、LightRAG、GraphRAG、RAPTOR、HyDEなど20本以上
- 課題:論文間の関係性がわからない、読んでも忘れる、実装との結びつきが弱い
- 時間:業務の合間に学習するため1日30分程度
行動(Action)
木下さんはDeepTutorを導入し、以下のワークフローを構築しました。
ナレッジベースの構築
RAG関連の論文20本をPDFでダウンロードし、DeepTutorにアップロード。1つのナレッジベースとして統合しました。
概念マップの可視化
「RAGの各手法の違いをまとめて」とクエリを投げると、DeepTutorがナレッジグラフから関連性を抽出し、各手法(Naive RAG、Advanced RAG、Modular RAG)の位置づけを可視化しました。
Practice Problemで定着
「RAGのリトリーバー設計についてクイズを出して」とリクエストし、生成された問題に回答。間違えた箇所は自動的に引用元の論文箇所が表示され、復習につながりました。
実装コードの確認
「LightRAGのナレッジグラフ構築部分のコード例を見せて」とクエリすると、論文内のアルゴリズム説明と、GitHubの実装コードを紐づけた解説が返ってきました。
結果(After)
2週間後、木下さんはRAG手法の全体像を把握し、プロジェクトでModular RAGアーキテクチャを採用する判断ができました。
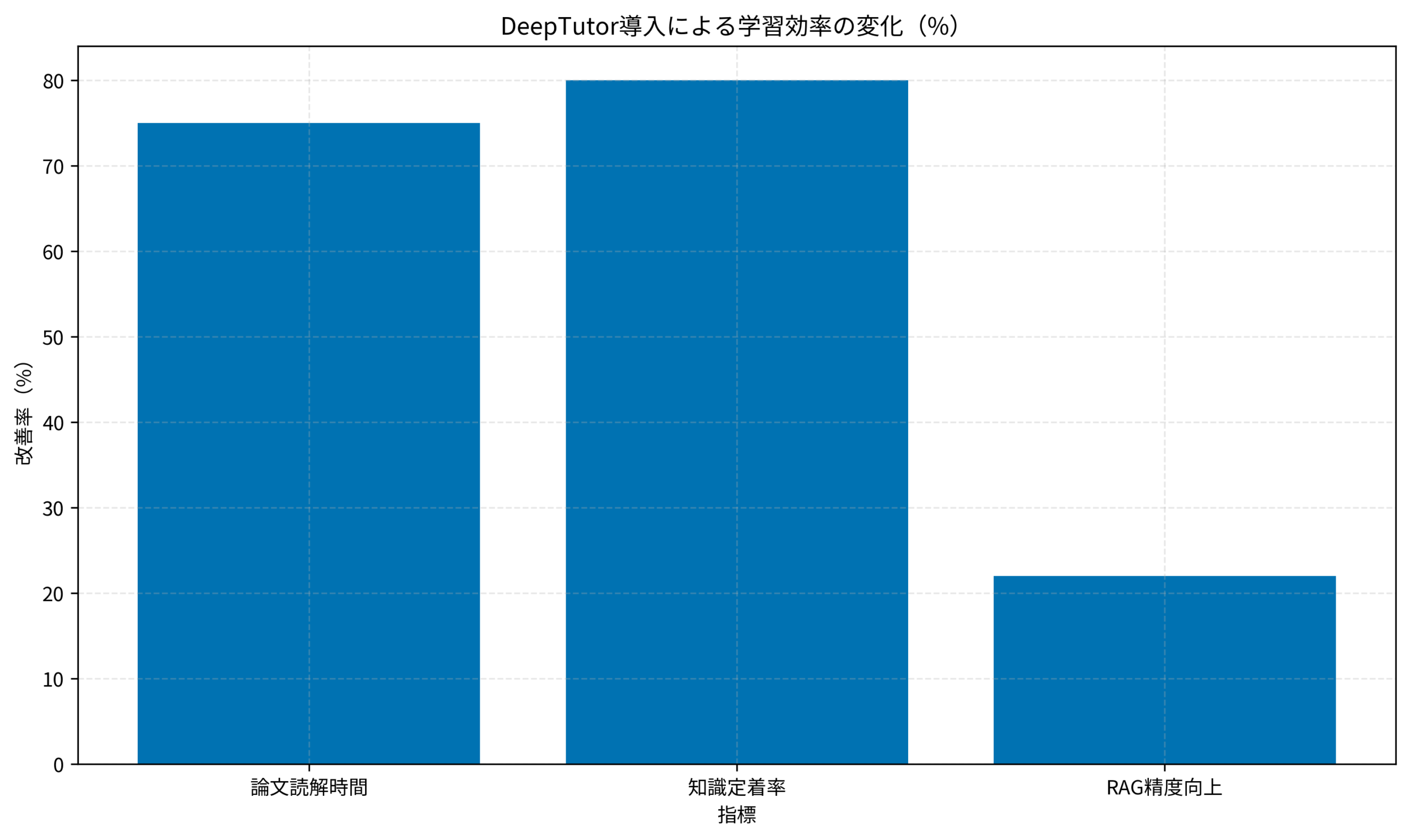
- 学習時間:論文1本あたり3時間 → 45分(75%短縮)
- 定着率:1週間後に概念を説明できる割合が30% → 80%
- 成果:自社RAGシステムにナレッジグラフ連携を追加し、回答精度が22%向上
木下さんは「論文を個別に読むのではなく、ナレッジベースとして統合し概念間の関係性を可視化するアプローチが正解だった」と振り返っています。従来の学習法では論文間のつながりが見えず非効率でしたが、DeepTutorのナレッジグラフ機能により体系的な理解が一気に進んだことが最大の収穫でした。
LLMトレーニングについては、lightronで始める軽量Megatron実装も参考になります。
IT女子 アラ美DeepTutor活用のコツと発展的な使い方
DeepTutorをより効果的に活用するためのコツを紹介します。
効果的なナレッジベース設計
- トピック単位でナレッジベースを分ける:「RAG論文集」「Kubernetes運用ノウハウ」のように、関連性の高い文書をグルーピング
- ファイル形式の統一:PDFが最も安定。Markdownテキストも対応
- 適切なサイズ:1つのナレッジベースには10〜50ファイル程度が推奨。多すぎると検索精度が低下
効果的なクエリパターン
- 比較質問:「AとBの違いは何ですか?」→複数概念の関係性を整理
- 実装質問:「この手法を実装するにはどうすればいいですか?」→コード例を生成
- クイズ依頼:「〇〇についてクイズを出して」→Practice Problemを活用
- Deep Research:「〇〇の最新研究動向を教えて」→Web検索・論文検索を併用
LLM設定のカスタマイズ
config/agents.yamlでエージェントごとにtemperatureやmax_tokensを調整できます。
# config/agents.yaml の例
solve:
temperature: 0.3 # 正確性重視
max_tokens: 4096
ideagen:
temperature: 0.8 # 創造性重視
max_tokens: 2048強化学習基盤については、OpenTinkerで始める強化学習基盤も参考になります。
IT女子 アラ美よくある質問(FAQ)
Q. DeepTutorはローカル環境だけで動作しますか?
DeepTutor自体はローカルで動作しますが、LLM APIとしてOpenAI APIキーが必要です。オフライン完結で使いたい場合は、Ollama等のローカルLLMを使う設定も可能ですが、回答精度はやや低下します。
Q. DeepTutorを使うとキャリアにどんなメリットがありますか?
RAGやナレッジグラフの実装経験は、AI/ML分野で高く評価されるスキルです。DeepTutorのアーキテクチャを理解することで、自社プロダクトへのRAG実装にも応用できます。ハイクラスエンジニア転職エージェント3社比較で紹介しているエージェントに相談すると、AI関連の高条件ポジションを紹介してもらいやすくなります。
Q. 日本語の論文や技術書にも対応していますか?
DeepTutorはLLMを通じて文書を処理するため、日本語の論文や技術書にも対応しています。ただし、英語文書の方がLLMの処理精度が高い傾向があるため、英語の論文がある場合はそちらを優先的にアップロードすることをおすすめします。
IT女子 アラ美おすすめ学習リソース・サービス
DeepTutorのようなAI学習ツールを活用しながら、Python×AI実装のスキルを体系的に学びたい方には、以下のサービスがおすすめです。実践的なカリキュラムで効率よくスキルアップできます。
サーバー環境の選定や本番運用時のインフラ構成については、エンジニア向けXServer用途別比較ガイドも参考になります。社内のAI学習基盤をリードする社内SEのキャリアを目指す方は社内SE転職エージェント3社比較ガイド、独立してAI案件を取りたい方はフリーランスエージェント5社比較もチェックしてみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
DeepTutorは、RAGとナレッジグラフを組み合わせたオープンソースのAI学習アシスタントです。
本記事のポイントを振り返りましょう。
- DeepTutorの特徴:Dual-Loop Reasoning、ナレッジグラフ統合、セッション記憶による学習特化アーキテクチャ
- 主要機能:Document Q&A、Learning Visualization、Practice Problem Generator、Deep Research
- セットアップ:conda環境を作成し、依存関係をインストール後、OpenAI APIキーを設定して起動
- 活用のコツ:トピック単位でナレッジベースを分け、比較質問・クイズ依頼を活用
技術書や論文を読んでもなかなか定着しない悩みを抱えているなら、DeepTutorで自分専用の学習環境を構築してみてください。ナレッジグラフによる概念の可視化と、Practice Problemによる定着確認で、学習効率が大きく改善するはずです。
IT女子 アラ美








