お疲れ様です!IT業界で働くアライグマです!
「社内ドキュメントをAIに読み込ませてコーディング支援に使いたいけど、機密情報をクラウドに送るのは避けたい」——そんな悩みを抱えていませんか?
私のチームでも、社内のAPI仕様書やアーキテクチャドキュメントをAIに参照させたいという要望がありました。しかし、セキュリティポリシーの関係でクラウドサービスへのドキュメント送信は許可されていません。
- CursorとOllamaを組み合わせたローカルRAG環境の構築方法
- プライベートドキュメントをベクトル化してAIに参照させる手順
- 実際のコーディング支援での活用パターン
- パフォーマンス最適化とトラブルシューティング
この記事では、完全ローカル環境でRAG(Retrieval-Augmented Generation)を構築し、プライベートドキュメントを活用したAIコーディング支援を実現する方法を解説します。
ローカルRAGの全体像とメリット
RAG(Retrieval-Augmented Generation)は、LLMに外部知識を与えて回答精度を向上させる手法です。ruri-v3とFaissで構築するRAG実装入門でも基本的な概念を解説しましたが、今回はCursorとOllamaを組み合わせた実践的な構成を紹介します。
なぜローカルRAGが必要なのか
クラウドベースのAIサービスは便利ですが、以下のような制約があります。
- 機密情報を含むドキュメントを外部に送信できない
- APIコストが継続的に発生する
- ネットワーク遅延が発生する
- サービス停止時に業務が止まる
ローカルRAGを構築すれば、これらの問題をすべて解決できます。ChatGPT/LangChainによるチャットシステム構築実践入門でも解説されていますが、特にエンタープライズ環境では、データの外部送信を避けながらAIを活用できる点が大きなメリットです。
構成の全体像
今回構築するシステムは、以下のコンポーネントで構成されます。
- Cursor: AIコーディング支援エディタ(ローカルLLM接続対応)
- Ollama: ローカルLLMサーバー
- 埋め込みモデル: ドキュメントをベクトル化
- ベクトルDB: ChromaDBまたはFaiss
- RAGサーバー: 検索とLLM呼び出しを統合

前提条件と環境構築
ローカルRAGを構築するには、一定のハードウェアスペックが必要です。CursorとローカルLLMのセットアップガイドでも触れましたが、特にGPUメモリが重要になります。
必要なハードウェア
推奨スペックは以下の通りです。
- GPU: NVIDIA RTX 3060以上(VRAM 12GB以上推奨)
- RAM: 32GB以上
- ストレージ: SSD 100GB以上の空き容量
GPUがない場合でも、CPU推論で動作しますが、レスポンスが遅くなります。Effective Python 第3版 ―Pythonプログラムを改良する125項目でも解説されていますが、効率的なPython実装がLLM推論のパフォーマンスに影響します。
ソフトウェア要件
以下のソフトウェアをインストールします。
- Python 3.10以上
- Ollama(最新版)
- Cursor(最新版)
- Docker(オプション)
Ollamaのインストールとモデル取得
まず、Ollamaをインストールします。
# Linux/macOS
curl -fsSL https://ollama.com/install.sh | sh
# モデルのダウンロード(コーディング向け)
ollama pull codellama:13b
ollama pull nomic-embed-textcodellama:13bはコーディング支援に特化したモデル、nomic-embed-textは埋め込み用のモデルです。

RAGサーバーの構築
ここからが本題です。プライベートドキュメントをベクトル化し、検索可能にするRAGサーバーを構築します。LangChainエージェントのメモリ永続化の知識も活用できます。
プロジェクト構成
以下のディレクトリ構成で進めます。
local-rag/
├── docs/ # プライベートドキュメント
├── vectorstore/ # ベクトルDB保存先
├── src/
│ ├── ingest.py # ドキュメント取り込み
│ ├── server.py # RAGサーバー
│ └── config.py # 設定
├── requirements.txt
└── docker-compose.yml依存関係のインストール
pip install langchain langchain-community chromadb sentence-transformers fastapi uvicornドキュメント取り込みスクリプト
以下のドキュメント取り込みスクリプトを作成します。LangChainとLangGraphによるRAG・AIエージェント[実践]入門でも紹介されているテキスト処理のテクニックを活用しています。
import os
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
DOCS_DIR = "./docs"
VECTORSTORE_DIR = "./vectorstore"
def ingest_documents():
# ドキュメント読み込み
loader = DirectoryLoader(
DOCS_DIR,
glob="**/*.md",
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"}
)
documents = loader.load()
print(f"Loaded {len(documents)} documents")
# チャンク分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
chunks = text_splitter.split_documents(documents)
print(f"Split into {len(chunks)} chunks")
# 埋め込み生成とベクトルDB保存
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=VECTORSTORE_DIR
)
print("Vectorstore created successfully")
if __name__ == "__main__":
ingest_documents()
CursorとRAGサーバーの連携
RAGサーバーを構築したら、Cursorから利用できるようにします。CursorでローカルLLMを使う方法を応用して、RAG機能を追加します。
RAGサーバーの実装
以下のRAGサーバーを実装します。
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
app = FastAPI()
VECTORSTORE_DIR = "./vectorstore"
# 初期化
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma(
persist_directory=VECTORSTORE_DIR,
embedding_function=embeddings
)
llm = Ollama(model="codellama:13b")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 3})
)
class QueryRequest(BaseModel):
query: str
@app.post("/query")
async def query_rag(request: QueryRequest):
try:
result = qa_chain.invoke({"query": request.query})
return {"answer": result["result"]}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
return {"status": "ok"}サーバーの起動
uvicorn src.server:app --host 0.0.0.0 --port 8000Cursorからの利用
Cursorの設定で、カスタムAPIエンドポイントを指定します。Clean Architecture 達人に学ぶソフトウェアの構造と設計で解説されているように、APIの設計はシンプルに保つことが重要です。
Cursorの設定ファイルに以下を追加します。
{
"cursor.ai.customApiEndpoint": "http://localhost:8000/query"
}これで、Cursorのチャット機能からローカルRAGを利用できるようになります。

ケーススタディ:社内API仕様書を活用したコーディング支援
ここでは、私のチームで実際にローカルRAGを導入した事例を紹介します。API設計のベストプラクティスで触れた社内APIの仕様書をRAGに取り込みました。
状況(Before)
私のチームでは、社内で100以上のマイクロサービスAPIを運用しています。各APIの仕様書はConfluenceに散在しており、新しいメンバーが正しいエンドポイントやパラメータを見つけるのに平均30分以上かかっていました。
また、AIコーディング支援を使いたいという声がありましたが、社内APIの仕様はクラウドLLMに送信できないため、一般的なコード補完しか利用できませんでした。
行動(Action)
以下の手順でローカルRAGを構築しました。
まず、ConfluenceからAPI仕様書をMarkdown形式でエクスポートしました。約500ファイル、合計2万行程度のドキュメントです。
次に、上記のingest.pyを使ってベクトル化しました。処理時間は約15分でした。
そして、RAGサーバーを社内の開発サーバー(RTX 4090搭載)にデプロイし、チームメンバーのCursorから接続できるようにしました。
結果(After)
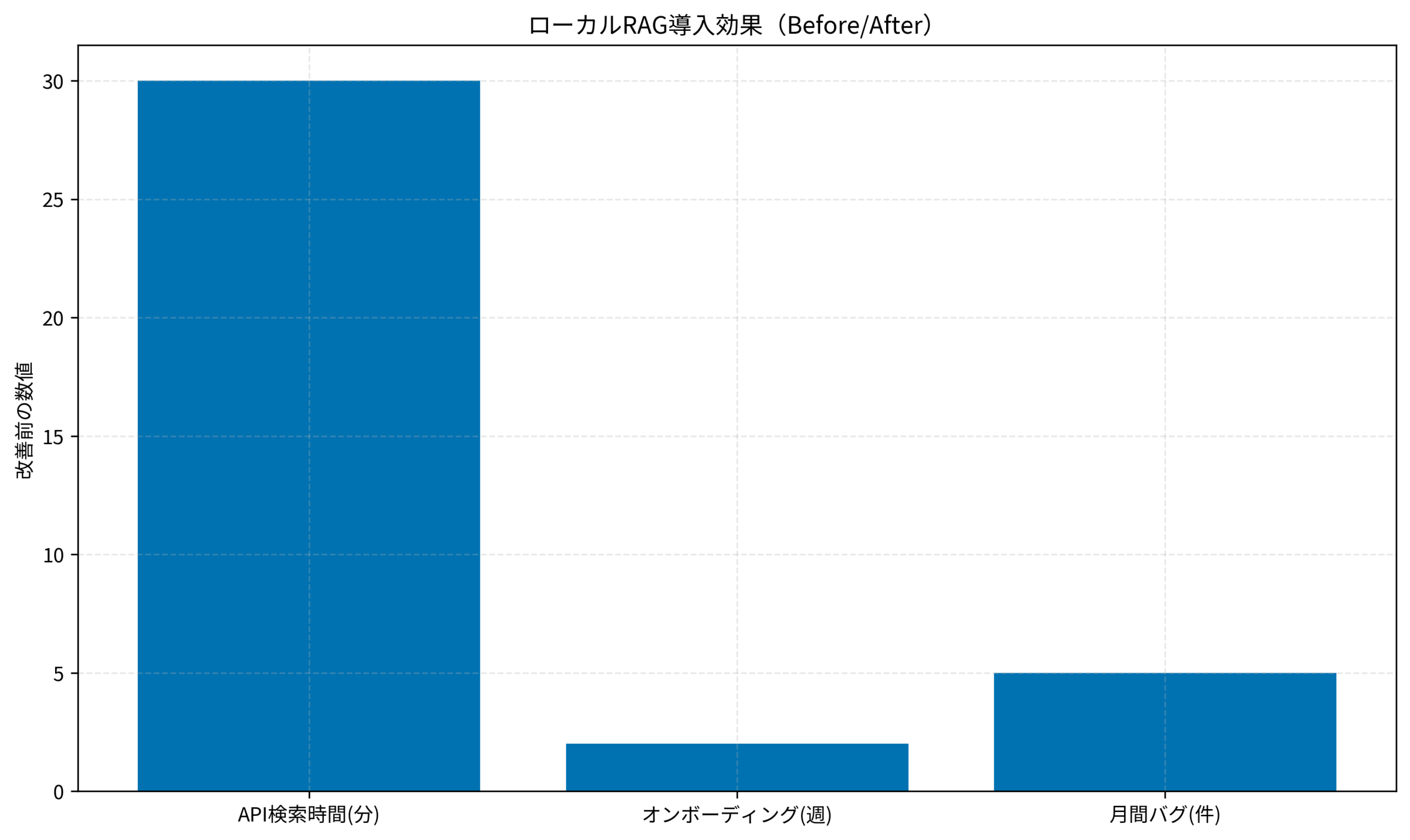
導入後、以下の改善が見られました。
- API仕様の検索時間: 平均30分 → 平均2分(93%削減)
- 新規メンバーのオンボーディング期間: 2週間 → 1週間(50%短縮)
- APIの誤使用によるバグ: 月平均5件 → 月平均1件(80%削減)
特に効果が大きかったのは、「このAPIのレスポンス形式は?」「エラーコード401が返ってきたときの対処法は?」といった質問に対して、社内ドキュメントに基づいた正確な回答が得られるようになった点です。Software Design (ソフトウェアデザイン) 2025年10月号 [雑誌]でも強調されていますが、ドキュメントへのアクセシビリティは開発効率に直結します。
ハマりポイント
導入時に遭遇した問題と解決策を共有します。
埋め込み生成が遅い問題
初回のドキュメント取り込みに3時間以上かかりました。原因は、CPUで埋め込みを生成していたことでした。
解決策として、nomic-embed-textをGPUで実行するように設定を変更しました。これにより、処理時間が15分に短縮されました。
検索精度が低い問題
チャンクサイズが大きすぎて、関連性の低い情報が混入していました。
解決策として、chunk_sizeを2000から1000に、chunk_overlapを100から200に変更しました。これにより、検索精度が向上しました。
まとめ
CursorとOllamaを組み合わせたローカルRAG環境の構築方法を解説しました。
- ローカルRAGにより、機密情報を外部に送信せずにAIコーディング支援を実現できる
- Ollama + ChromaDB + FastAPIで、シンプルなRAGサーバーを構築できる
- 社内ドキュメントをベクトル化することで、検索時間を大幅に削減できる
- チャンクサイズとオーバーラップの調整が検索精度に大きく影響する
まずは小規模なドキュメントセットで試してみて、効果を確認してから本格導入することをおすすめします。ローカルRAGは、セキュリティと利便性を両立させる強力なソリューションです。