お疲れ様です!IT業界で働くアライグマです!
「SnowflakeとDatabricks、どっちを選べばいいの?」
「コンピュートとストレージの分離って、具体的に何が違うの?」
「IcebergとDeltaって結局どっちがいいの?」
データ基盤の選定で、こんな悩みを抱えていませんか?
SnowflakeとDatabricksは、どちらもモダンデータスタックの中核を担うプラットフォームですが、設計思想が根本的に異なります。
この違いを理解せずに選定すると、後から「こんなはずじゃなかった」と後悔することになりかねません。
私はPjMとして複数のデータ基盤プロジェクトに関わってきましたが、選定段階での理解不足が後工程のトラブルにつながるケースを何度も見てきました。
この記事では、SnowflakeとDatabricksのコンピュートレイヤーとストレージレイヤーの設計思想を徹底比較し、あなたのプロジェクトに最適な選択ができるようになることを目指します。
SnowflakeとDatabricksの設計思想の違い
まず、両者の根本的な設計思想の違いを理解しましょう。
この違いを押さえておくことで、後続の技術的な比較がスムーズに理解できます。
Snowflake:完全マネージドなデータウェアハウス
Snowflakeは「すべてをマネージドで提供する」という思想で設計されています。
- コンピュートとストレージの完全分離:独自のアーキテクチャで実現
- 独自のメタデータ管理:Snowflake内部で最適化されたメタデータ
- ゼロ運用:チューニングやインデックス設計が基本的に不要
Snowflakeの強みは、運用負荷の低さです。
データエンジニアがインフラの面倒を見る必要がほとんどなく、SQLを書くことに集中できます。
Databricks:オープンスタンダードなレイクハウス
一方、Databricksは「オープンスタンダードを基盤にする」という思想で設計されています。
- Delta Lakeによるストレージ:オープンソースのテーブルフォーマット
- Apache Sparkベースのコンピュート:業界標準のエンジン
- 柔軟なカスタマイズ:細かいチューニングが可能
Databricksの強みは、柔軟性とオープン性です。
ベンダーロックインを避けたい場合や、機械学習ワークロードを重視する場合に適しています。
データ基盤の設計パターンについては、Supabase Edge Functions実践:サーバーレスバックエンドで実現する高速API設計も参考になります。
両者の違いを理解するには、[エンジニアのための]データ分析基盤入門<基本編>のようなデータ基盤の入門書で基礎を固めておくと、技術選定の議論がスムーズになります。

コンピュートレイヤーの比較:Warehouse vs Cluster vs Serverless
次に、コンピュートレイヤーの設計を詳しく比較します。
ここが両者の最も大きな違いの一つです。
Snowflake:Virtual Warehouseの仕組み
SnowflakeのコンピュートはVirtual Warehouseという単位で管理されます。
- サイズ指定:XS〜6XLまでのサイズを選択
- 自動スケーリング:マルチクラスターで負荷分散
- 自動サスペンド:アイドル時に自動停止してコスト削減
Virtual Warehouseの特徴は、シンプルさです。
サイズを選ぶだけで、クラスタの細かい設定を気にする必要がありません。
-- Snowflakeでのウェアハウス作成例
CREATE WAREHOUSE analytics_wh
WITH WAREHOUSE_SIZE = 'MEDIUM'
AUTO_SUSPEND = 300
AUTO_RESUME = TRUE
MIN_CLUSTER_COUNT = 1
MAX_CLUSTER_COUNT = 3;Databricks:Clusterの柔軟な構成
DatabricksのコンピュートはClusterという単位で管理されます。
- ノード構成:ドライバーノードとワーカーノードを個別に設定
- インスタンスタイプ:AWSやAzureのインスタンスを直接選択
- オートスケーリング:ワーカー数の最小・最大を設定
Clusterの特徴は、細かいチューニングが可能なことです。
ワークロードに応じて最適な構成を追求できます。
Databricks Serverless:運用負荷の軽減
最近のDatabricksでは、Serverlessオプションも提供されています。
これはSnowflakeのようなマネージド体験を提供するもので、クラスタ管理の手間を省けます。
ただし、Serverlessは従来のClusterよりコストが高くなる傾向があるため、ワークロードの特性に応じて使い分けが必要です。
分散処理の基礎については、Polars実践ガイド:Pandasから移行して大規模データ処理を10倍高速化する設計パターンで解説しています。
コンピュートの設計を深く理解するには、Kubernetes完全ガイド 第2版が参考になります。分散システムの基礎を押さえておくと、両者の設計思想の違いがより明確に理解できます。
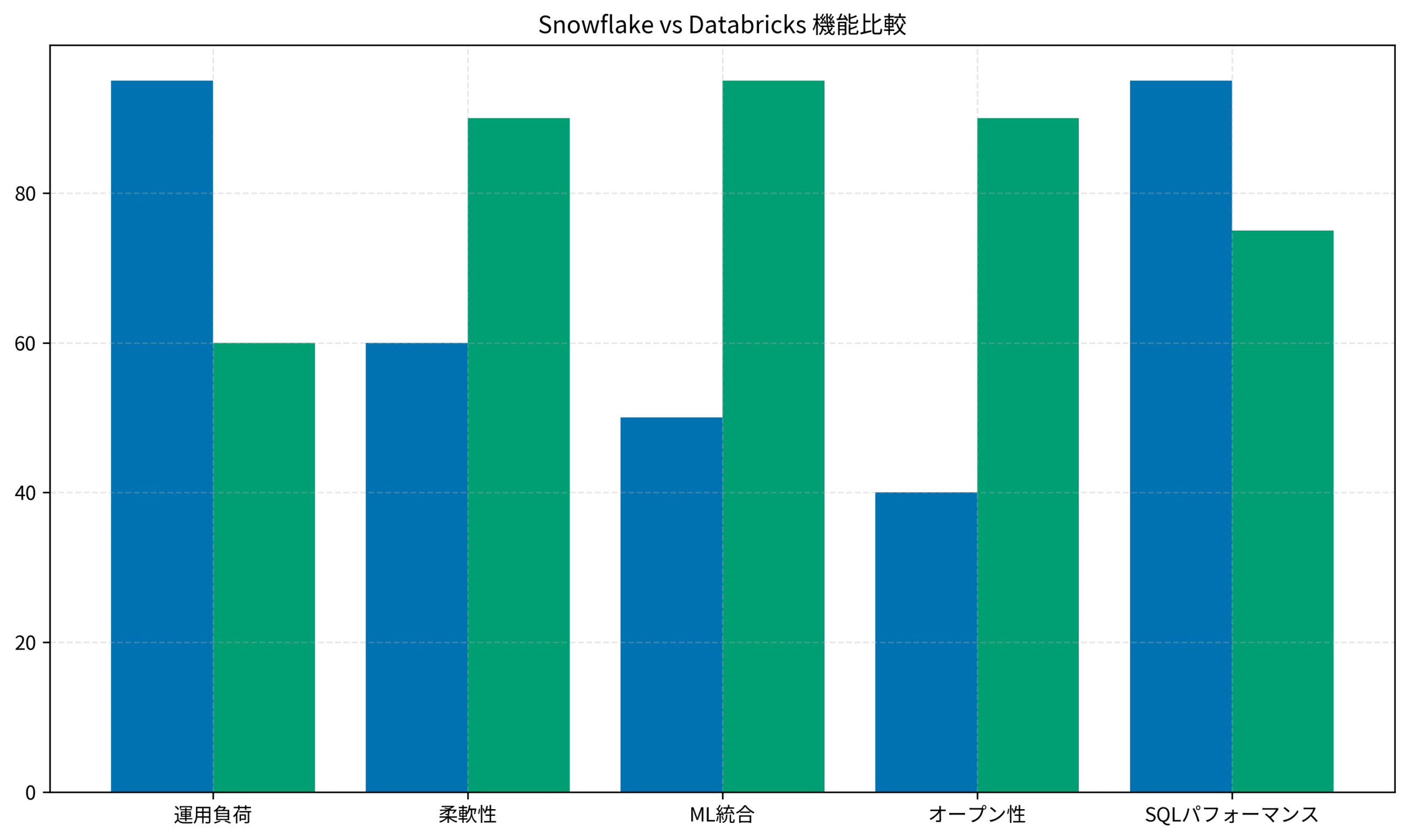
ストレージレイヤーの比較:Iceberg vs Delta vs 独自メタデータ
ストレージレイヤーの設計は、データの可搬性とベンダーロックインに直結する重要なポイントです。
Snowflake:独自メタデータによる最適化
Snowflakeは独自のメタデータ管理を採用しています。
- マイクロパーティション:自動的にデータを最適なサイズに分割
- クラスタリング:クエリパターンに応じた自動最適化
- Time Travel:過去のデータ状態への簡単なアクセス
この独自設計により、クエリパフォーマンスが非常に高いのがSnowflakeの強みです。
一方で、データをSnowflake外に持ち出す際には変換が必要になります。
Databricks:Delta Lakeによるオープンフォーマット
DatabricksはDelta Lakeというオープンソースのテーブルフォーマットを採用しています。
- ACIDトランザクション:データレイク上でのトランザクション保証
- スキーマ進化:カラム追加などの変更に柔軟に対応
- タイムトラベル:過去のバージョンへのアクセス
Delta Lakeの最大の利点は、オープンスタンダードであることです。
Databricks以外のツールからもDelta形式のデータにアクセスできます。
Apache Iceberg:第三の選択肢
最近では、Apache Icebergも注目を集めています。
SnowflakeもDatabricksも、Icebergテーブルのサポートを強化しています。
- Snowflake:Iceberg Tablesとして外部テーブルをサポート
- Databricks:UniFormでDeltaとIcebergの相互運用を実現
Icebergを選択することで、将来的なプラットフォーム移行の自由度を確保できます。
私がPjMとして関わったプロジェクトでは、ベンダーロックインを避けるためにIcebergを採用したケースがありました。
初期の学習コストはかかりましたが、後からDatabricksからSnowflakeへの部分移行がスムーズにできたのは大きなメリットでした。
データ基盤のアーキテクチャについては、LangChain 1.0エージェントアーキテクチャ完全ガイドでも触れているエージェント設計の考え方が参考になります。
ストレージ設計の詳細を学ぶには、ドメイン駆動設計がおすすめです。データベースの内部構造を理解することで、各フォーマットの設計意図が見えてきます。

ユースケース別の選定ガイド
ここまでの比較を踏まえて、ユースケース別の選定ガイドを整理します。
Snowflakeが向いているケース
- SQLベースのBI・分析が中心:SQLに特化した最適化が効く
- 運用負荷を最小化したい:マネージドサービスの恩恵を最大限に
- データ共有が重要:Snowflake Data Marketplaceの活用
- 小〜中規模のチーム:専任のデータエンジニアが少ない場合
Databricksが向いているケース
- 機械学習ワークロードが多い:MLflowやFeature Storeの統合
- ストリーミング処理が必要:Structured Streamingの活用
- オープンスタンダードを重視:ベンダーロックインを避けたい
- 細かいチューニングが必要:大規模データ処理の最適化
ハイブリッド構成という選択肢
実際のプロジェクトでは、両方を組み合わせるケースも増えています。
- Databricks:データレイク・ETL・機械学習
- Snowflake:BI・レポーティング・データ共有
この構成では、Icebergを共通フォーマットとして使うことで、両者間のデータ連携がスムーズになります。
私が関わったプロジェクトでは、当初Databricksのみで構築していましたが、BI部門からの要望でSnowflakeを追加導入しました。
Icebergを採用していたおかげで、データの二重管理を避けながら両方のプラットフォームを活用できています。
クラウドアーキテクチャの設計については、Cursor×ローカルLLM完全ガイドでも触れているローカル環境との連携の考え方が参考になります。
プロジェクトの技術選定を進める際には、ソフトウェアアーキテクチャの基礎で基礎を固めておくと、チーム内での議論がスムーズになります。

まとめ
SnowflakeとDatabricksは、どちらも優れたデータプラットフォームですが、設計思想が根本的に異なります。
この記事で解説したポイントを振り返ると、
- Snowflake:完全マネージド・独自最適化・運用負荷最小
- Databricks:オープンスタンダード・柔軟性・ML統合
- コンピュート:Warehouse(シンプル)vs Cluster(柔軟)
- ストレージ:独自メタデータ vs Delta Lake(オープン)
- Iceberg:両者をつなぐ共通フォーマットとして注目
どちらを選ぶかは、チームのスキルセット・ワークロードの特性・将来の拡張性を総合的に判断する必要があります。
迷ったら、まずは小規模なPoCで両方を試してみることをおすすめします。
実際に触ってみることで、ドキュメントだけでは分からない使用感の違いが見えてきます。









