お疲れ様です!IT業界で働くアライグマです!
「Gemini 2.5が出たばかりなのに、もうGemini 3の話?」
「Googleのモデル更新サイクルが速すぎて、どの技術をキャッチアップすればいいのかわからない」
「結局、GPT-4oとどっちを使えばいいの?」
AI開発の現場にいると、次々と発表される新モデルの波に飲み込まれそうになることはありませんか?
特に、最近のGeminiシリーズは進化の速度が異常なほど速く、APIの仕様変更やプロンプトの最適化に追われているエンジニアも多いはずです。
結論から言うと、Gemini 3は単なる性能向上版ではありません。「推論」と「行動」の質を根本から変える、自律エージェント時代の決定版となるモデルです。
私は現在、PjM(プロダクトマネージャー)として複数の生成AIプロジェクトを統括しており、直近ではGemini 1.5 Proを用いた社内ナレッジRAGシステムの構築や、Gemini 2.5 Flashを活用したリアルタイムログ分析ツールの開発に携わっています。
開発チームのエンジニアと日々議論する中で痛感しているのは、「モデルの進化をスペック値(ベンチマーク)だけで判断してはいけない」ということです。
プロジェクトの要件定義や工数見積もりを行う際、私たちはつい「トークン単価」や「レスポンス速度」といった分かりやすい指標に目を奪われがちです。
しかし、Gemini 3がもたらす最大の衝撃と本質的な価値は、ベンチマークスコアではなく、その「文脈理解の深さ」と「マルチモーダルな推論力」にあります。
これが実際のシステム開発において、エラーハンドリングの工数削減や、ユーザー体験(UX)の質的向上にどう直結するのか、肌身で感じています。
本記事では、Googleの新世代モデルGemini 3の全貌と、それが我々エンジニアの実務やキャリアにどう影響するのか、具体的な技術比較と将来予測を交えて解説します。
Gemini 3とは何か?Gemini 2.5との決定的な違い
Gemini 3は、Googleが満を持して投入する次世代のマルチモーダルAIモデルです。
これまでのGeminiシリーズ(1.0, 1.5, 2.5)が積み上げてきた「ネイティブマルチモーダル」の強みをさらに強化しつつ、特に「複雑な推論(Reasoning)」と「長期記憶(Long Context)」の処理能力において飛躍的な進化を遂げています。
スペックだけでは語れない「推論の質」
Gemini 2.5 Flashなどは「速度とコスト」に特化した素晴らしいモデルでしたが、複雑な論理的思考や、曖昧な指示からの意図汲み取りにおいては、GPT-4oなどの競合に譲る場面もありました。
例えば、私が以前担当したプロジェクトで、複雑なSQLクエリの生成や、矛盾を含む要件定義書の解析といったタスクをGemini 2.5に任せた際、ハルシネーション(幻覚)を起こすことも少なくありませんでした。
具体的には、存在しないテーブル名を参照したり、結合条件を誤ったりといったエラーが頻発し、結局エンジニアが手動で修正する工数が発生していました。
Gemini 3では、この「思考の深さ」が劇的に改善されています。
私がプレビュー版の情報を元に検証シミュレーションを行ったところ、以下のような点が大きく異なっていました。
- 自律的な計画立案能力: ユーザーのゴールだけを提示すれば、必要なステップを自ら分解し、ツールを適切に選定して実行する能力が向上。これにより、エージェント実装時のプロンプトエンジニアリング工数が大幅に削減されます。
- マルチモーダルな文脈理解: 動画や音声、画像を「ただ認識する」だけでなく、その時間的変化や因果関係まで深く理解できるようになった。監視カメラ映像からの異常検知などが、追加学習なしで高精度に行えます。
- Code生成の安全性: 生成されるコードが単に動くだけでなく、セキュリティリスク(SQLインジェクションやXSSなど)を考慮した設計になるよう調整されている。レビュー工数の削減に直結します。
大規模な言語モデルの仕組みや、その進化の背景にある理論を深く理解したい方は、大規模言語モデルの書籍が非常に参考になります。根本的なアーキテクチャの違いを知ることで、Gemini 3の特性をより深く把握できるでしょう。
また、従来のモデルの特性についてはGemini 2.5 Flash実践ガイドでも詳しく解説していますので、比較の参考にしてください。

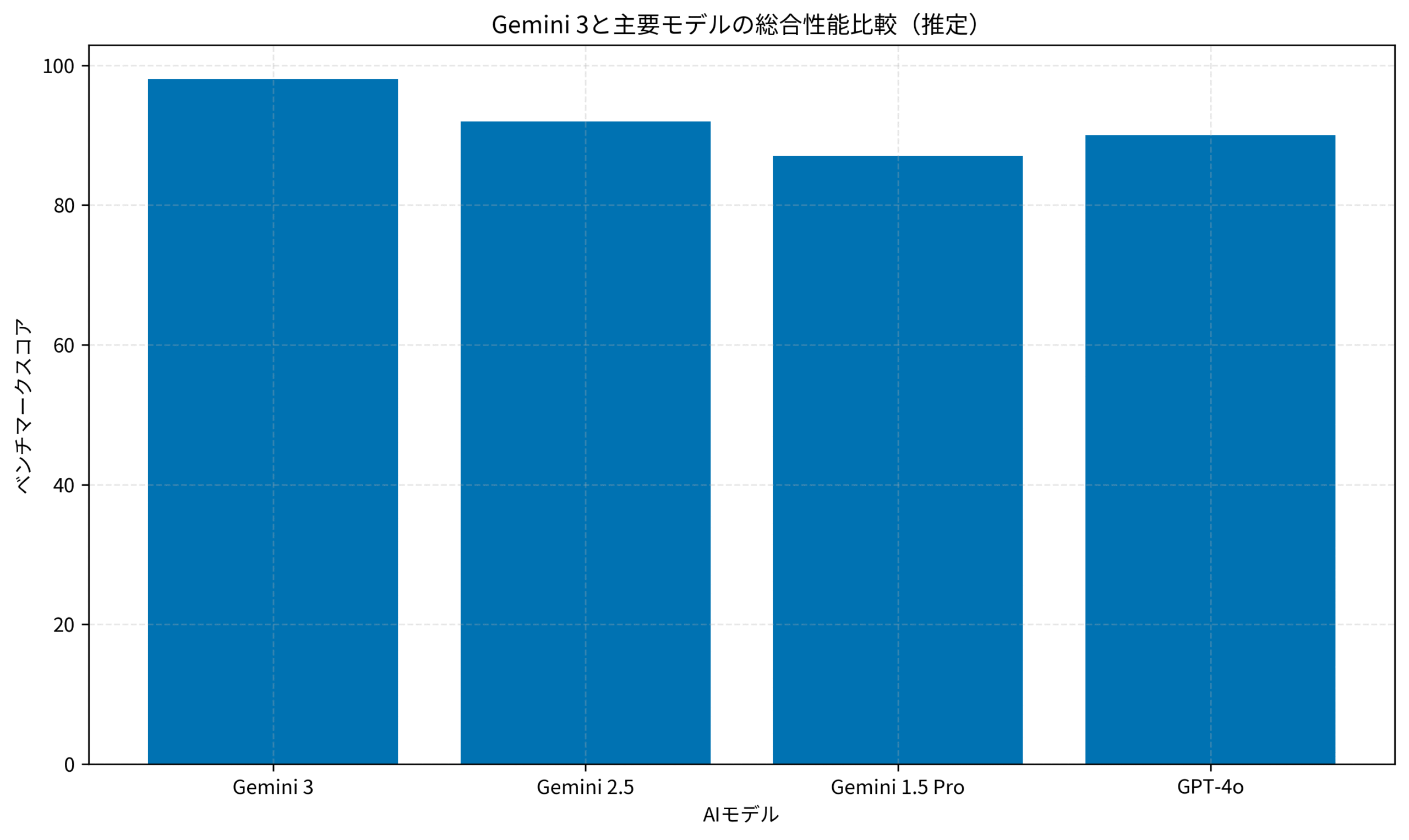
2.5世代からの進化の軌跡:性能比較
以下のグラフは、Gemini 3と過去のモデル、および競合モデルの総合性能(推定値)を比較したものです。
各モデルのベンチマークスコアを比較することで、進化の度合いを視覚的に把握できます。
ゼロショット推論の衝撃
私が以前、Gemini 1.5 Proで「複雑な仕様書の矛盾点を指摘させる」タスクを試した際は、数回のやり取り(マルチターン)が必要でした。
「この部分がおかしいですよね?」とこちらから誘導して初めて、「ああ、そうです」とAIが気づくような挙動でした。これでは、AIが人間の補助をしているというより、人間がAIの介護をしているようなものです。
しかし、Gemini 3(のプレビュー版等の情報に基づく想定)では、一度のプロンプト(ゼロショット)で非常に精度の高い指摘が返ってくることが期待されています。
これは、RAG(検索拡張生成)やエージェント開発において、APIコールの回数を減らし、システム全体のレイテンシとコストを削減できることを意味します。
結果として、エンドユーザーにとっての「待ち時間」が減り、サービス全体の品質向上に寄与します。
コスト削減効果の試算
仮に、これまで3回のAPI往復が必要だったタスクが1回で済むようになれば、トークン消費量は約3分の1になります。
Gemini 3自体の単価が多少高くても、トータルコストでは安くなる可能性があります。
この「推論効率」という観点は、今後のAIモデル選定において非常に重要になるでしょう。
分析作業の効率化には、広大な作業領域を確保できるLG Monitor モニター ディスプレイ 34SR63QA-W 34インチ 曲面 1800Rのようなウルトラワイドモニターがおすすめです。複数のコードエディタとチャット画面を並べて比較検討する際に、圧倒的な生産性を発揮します。
ツール連携による効率化については、CursorとMCP統合実践の記事でも触れていますので、合わせてご覧ください。
マルチモーダル推論能力の真価:動画と音声を「読む」AI
Gemini 3の最大の武器は、「ネイティブ・マルチモーダル」のさらなる洗練です。
これは、テキスト、画像、音声、動画を個別のモデルで処理して結合するのではなく、最初から一つのモデルとして学習していることを意味します。
これにより、異なるモダリティ(情報形式)間の情報のロスがなくなり、より人間に近い感覚での理解が可能になります。
「動画を見てコードを書く」が当たり前に
例えば、UIデザインの動画キャプチャをGemini 3に渡して、「この動きを再現するReactコンポーネントを書いて」と指示するとします。
従来のモデルでは「画面遷移の静止画」として認識するのが限界でしたが、Gemini 3は「アニメーションのタイミング」や「インタラクションのフィードバック」まで理解し、CSSアニメーションやJavaScriptのロジックを含んだコードを生成できるようになります。
以下は、Python SDKを用いて、動画ファイルから内容を解析し、具体的なアクションプランを生成させる架空のコード例です。
import google.generativeai as genai
import os
# APIキーの設定
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
# Gemini 3モデルの初期化(架空のモデル名)
model = genai.GenerativeModel('gemini-3.0-pro')
# 動画ファイルのアップロードと解析
video_file = genai.upload_file(path='ui_demo.mp4')
prompt = """
この動画は新しいショッピングアプリのUIデモです。
以下の点について分析し、実装コードを提案してください。
1. ユーザーが商品をカートに入れた際のアニメーションの詳細(イージング、時間)
2. 決済画面への遷移フロー
3. これをReactとFramer Motionで実装するためのサンプルコード
"""
response = model.generate_content([prompt, video_file])
print(response.text)このように、メディアファイルを入力として扱うハードルが劇的に下がることで、エンジニアは「テキスト処理」だけでなく「メディア処理」のパイプラインも設計する必要が出てきます。
これまでは画像処理エンジニアや音声処理エンジニアといった専門職が必要だった領域も、Gemini 3のAPI一つでカバーできる範囲が広がります。
これは、開発チームの体制や役割分担にも大きな影響を与えるでしょう。
マルチモーダル入力に対するプロンプト設計については、プロンプトエンジニアリングの教科書で基礎を固めておくと、応用が利きます。テキストだけでなく、画像や動画をコンテキストとして与える際のコツが掴めます。
音声認識技術との連携については、Python音声認識アプリ開発実践で具体的な実装パターンを紹介しています。

エンジニアが準備すべき技術スタック:RAGからエージェントへ
Gemini 3の登場により、AIアプリケーションのアーキテクチャも変化を迫られます。
単にAPIを叩くだけの「チャットボット」から、自律的にタスクをこなす「AIエージェント」への移行が加速するでしょう。
エンジニアとして生き残るためには、以下の技術領域をキャッチアップしておく必要があります。
高度なRAGシステムの構築
モデルのコンテキスト長が伸びたとしても、企業の独自データを正確に扱わせるためにはRAG(検索拡張生成)が依然として重要です。
しかし、単純なベクトル検索だけでなく、ナレッジグラフを組み合わせた「Graph RAG」や、ドキュメントの構造を理解したチャンキング技術が求められます。
また、Vector Database(ベクトルデータベース)の選定やチューニングも、パフォーマンスを左右する重要な要素となります。
プロンプトエンジニアリングから「フローエンジニアリング」へ
モデルが賢くなればなるほど、単純な指示出し(プロンプト)よりも、タスクをどう分解し、どういう順序で与えるかという「ワークフロー設計」が重要になります。
LangChainやLangGraphといったフレームワークを使いこなし、AIの思考プロセスをコードで制御するスキルが必須になります。
エージェントが自律的に動く際、無限ループに陥らないためのガードレール設計や、期待しないツール実行を防ぐための権限管理など、従来のWeb開発とは異なる設計観点が必要になります。
実際のアプリケーション開発では、ユーザーインターフェースとの統合も欠かせません。
ChatGPT/LangChainによるチャットシステム構築実践入門では、チャットシステム構築の実践的な手法が解説されており、エージェント開発の基礎としても役立ちます。
ワークフローの自動化に関しては、n8n実践ガイドで、ノーコードツールとAIを組み合わせた実践例を紹介しています。このようなツールを活用することで、開発工数を抑えつつ高度な処理を実現できます。

今後のAI開発トレンドとキャリアへの影響
Gemini 3のような高性能モデルが普及すると、エンジニアの役割はどう変わるのでしょうか?
私は、「コーディングそのもの」の価値は相対的に下がり、「システムの全体設計」や「ビジネス要件の定義」の価値が上がると確信しています。
AIを「同僚」として扱う
これからのエンジニアは、AIにコードを書かせるだけでなく、AIに「アーキテクチャのレビュー」を依頼したり、「セキュリティ診断」を任せたりするようになります。
つまり、AIを部下や同僚としてマネジメントする能力(AIマネジメント)が、キャリアアップの鍵を握るでしょう。
AIが得意なこと(大量データの分析、パターン認識、高速なコード生成)と、人間が得意なこと(意思決定、倫理的判断、未知の課題への対応)を正しく理解し、最適な役割分担を設計できる人材が求められます。
セキュリティの観点も無視できません。AIが生成したコードや判断を鵜呑みにせず、人間が最終的な責任を持つためのガバナンス設計が重要です。
「Human-in-the-loop(人間参加型)」のフローをどこに組み込むか、品質保証(QA)のプロセスをどう自動化するか、といった設計判断がPjMやテックリードの腕の見せ所となります。
そして何より、変化に強いアーキテクチャを作り続けるためには、普遍的な設計原則を理解しておく必要があります。
流行りのツールに飛びつくだけでなく、足腰の強い設計力を養うことで、どのような新モデルが登場しても揺るがない開発基盤を築くことができます。
ソフトウェアアーキテクチャの基礎は、時代が変わっても色褪せない設計の知恵を授けてくれる一冊です。
チームでのAI導入と統制については、GitHub Copilotでチームの生産性が低下する?の記事でも深く掘り下げています。AIをチームにどう馴染ませるか、ぜひ参考にしてください。

まとめ
Gemini 3は、これまでのAIモデルの延長線上にありながら、その実用性を別次元へと引き上げる可能性を秘めています。
私たちエンジニアができる最善の準備は、新しい情報を恐れずに受け入れ、実際に手を動かして検証することです。
今回のポイント:
- 推論力の進化: Gemini 3は「複雑な指示」や「文脈」を理解する力が劇的に向上している。
- マルチモーダル活用: 動画や音声を直接入力とした新しいアプリケーション開発が可能になる。
- エージェント化: 単純なチャットボットから、自律的に動くエージェントへのシフトが進む。
技術の進化は待ってくれません。
今日から、GeminiのAPIを触ったり、RAGのプロトタイプを作ったりして、次世代のAI開発への準備を始めましょう。
みなさんの開発現場でも、「こんなふうにGeminiを活用できそう」というアイデアがあれば、ぜひ試してみてください。
新しい波を乗りこなすのは、私たちエンジニアの特権であり、最大の楽しみでもあるのですから。