
お疲れ様です!IT業界で働くアライグマです!
PostGISで地理空間データを扱うプロジェクトに参加していると、「なぜか位置情報検索が遅い」「インデックスを作ったはずなのに効いていない」という問題に遭遇することがあります。
筆者も以前、数百万件の店舗データを持つプロジェクトで、「半径5km以内の店舗検索」に10秒以上かかるという問題に悩まされました。結論から言えば、空間インデックスの設計ミスとANALYZE不足が原因でした。
本記事では、PostGISの空間インデックス(GiSTインデックス)の仕組みと、ANALYZE統計情報の役割を理解し、地理空間クエリを劇的に高速化する方法を解説します。
PostGISの空間インデックスとは
空間インデックスは、地理空間データに対する検索を高速化するためのデータ構造です。PostgreSQLの通常のB-Treeインデックスは一次元データ向けですが、地理空間データは二次元(あるいは三次元)なので、専用のインデックスが必要になります。
GiSTインデックスの仕組み
PostGISでは主にGiST(Generalized Search Tree)インデックスを使用します。GiSTはR-Tree構造をベースにしており、空間オブジェクトを「バウンディングボックス(最小外接矩形)」で階層的に管理します。
- バウンディングボックス:各ジオメトリを囲む最小の矩形
- 階層構造:ルートから葉まで、空間を再帰的に分割
- クエリ時の動作:検索範囲と重なるボックスだけを辿ることで、検索対象を絞り込む
-- 空間インデックスの作成
CREATE INDEX idx_shops_geom ON shops USING gist(geom);
-- インデックスのサイズ確認
SELECT pg_size_pretty(pg_relation_size('idx_shops_geom'));データベースのパフォーマンスチューニングは実装の細部に宿ります。Rails8でSQLiteを本番運用する記事も参考にしてください。
 IT女子 アラ美
IT女子 アラ美ANALYZEと統計情報の重要性
空間インデックスを作っても、クエリプランナーが正しく使ってくれないケースがあります。その原因の多くは、統計情報(カタログ情報)の不足です。
ANALYZEの役割
PostgreSQLのクエリプランナーは、テーブルの統計情報をもとに最適な実行計画を選択します。ANALYZEコマンドは、この統計情報を更新します。
- 行数推定:テーブルにどれくらいのデータがあるか
- 値の分布:どのような値がどれくらいの頻度で出現するか
- 空間的な広がり:ジオメトリがどの程度の領域に分布しているか
-- テーブルの統計情報を更新
ANALYZE shops;
-- 特定カラムの統計情報を確認
SELECT attname, n_distinct, correlation
FROM pg_stats
WHERE tablename = 'shops' AND attname = 'geom';統計情報が古いとどうなるか
統計情報が実際のデータと乖離していると、クエリプランナーは間違った推定をしてしまいます。データベースの内部動作を理解することが重要で、Goで実装するヘッドレスワークフローエンジンでも触れたトランザクション設計の考え方が参考になります。
- シーケンシャルスキャンを選択:インデックスがあるのにフルスキャン
- ネストループが選ばれる:ハッシュ結合の方が速いのに
- 並列クエリが起動しない:行数推定が少なすぎて
IT女子 アラ美ケーススタディ:店舗検索クエリの高速化
状況(Before)
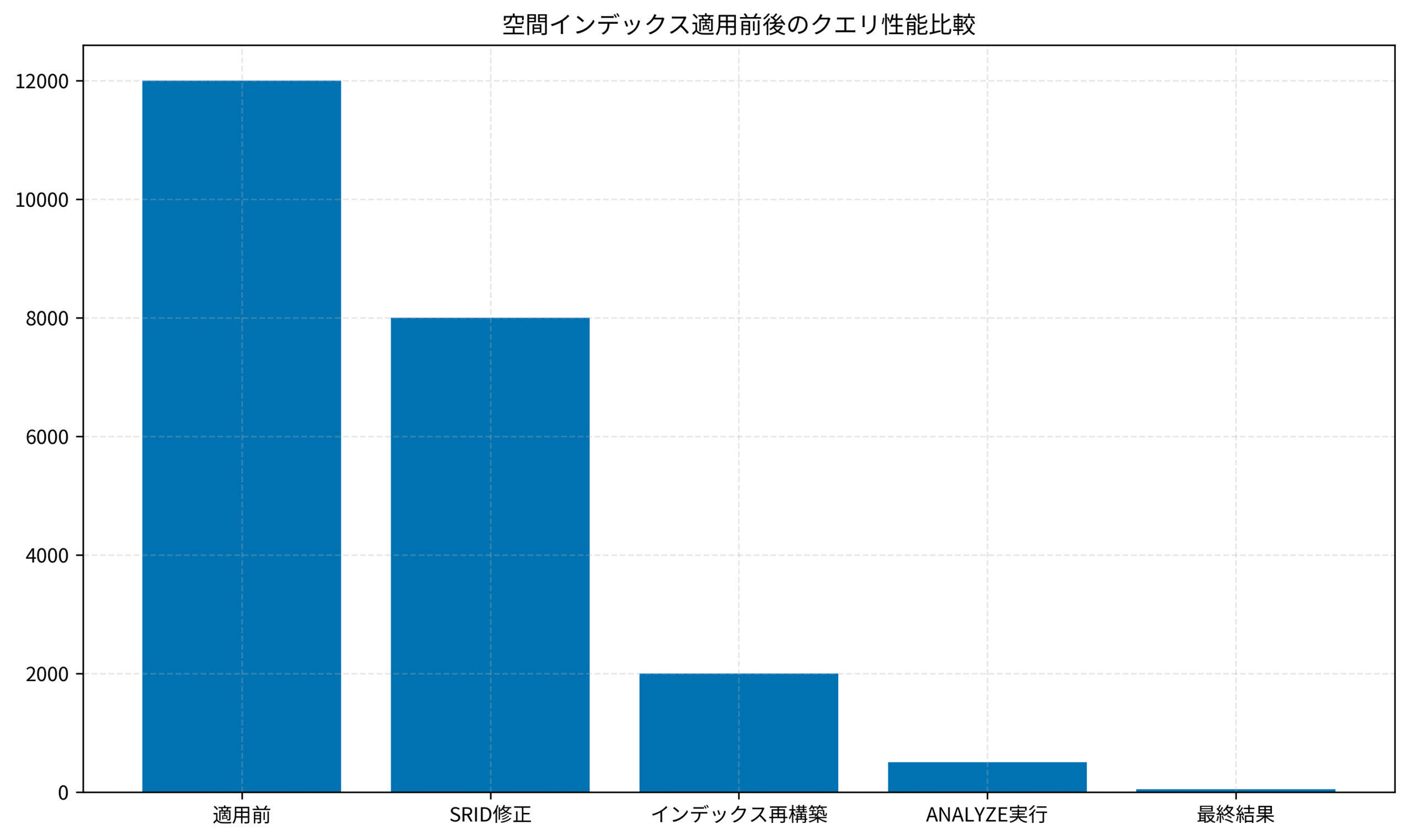
ECサイトの店舗検索機能を担当していた時の事例です。ユーザーが現在地から半径5km以内の店舗を検索する機能で、レスポンスが10秒以上かかるという問題が発生していました。
- 環境:PostgreSQL 15 + PostGIS 3.3、AWS RDS(db.r5.large)
- データ量:店舗テーブル約350万件、ジオメトリカラム付き
- 問題のクエリ:ST_DWithinを使った半径検索
- レスポンス時間:平均12秒(ピーク時は20秒超)
- インデックス:GiSTインデックス作成済み(のはず)
行動(Action)
まずEXPLAIN ANALYZEで実行計画を確認しました。
EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT)
SELECT id, name, ST_AsText(geom)
FROM shops
WHERE ST_DWithin(
geom,
ST_SetSRID(ST_MakePoint(139.7454, 35.6586), 4326)::geography,
5000
);出力を確認すると、Seq Scan(フルスキャン)になっていました。インデックスがあるのに使われていない。原因を調査したところ、以下の問題が判明しました。
- SRID不一致:テーブルのジオメトリはSRID 4326だが、一部データがSRID 0で投入されていた
- ANALYZEの未実行:大量データ投入後にANALYZEを実行していなかった
- geography型でのインデックス:geometry型にインデックスを張っていたが、クエリはgeography型にキャストしていた
修正内容は以下の通りです。
-- 1. SRID不一致データの修正
UPDATE shops SET geom = ST_SetSRID(geom, 4326) WHERE ST_SRID(geom) = 0;
-- 2. geography型でインデックスを再作成
DROP INDEX IF EXISTS idx_shops_geom;
CREATE INDEX idx_shops_geom_geog ON shops USING gist((geom::geography));
-- 3. ANALYZE実行
ANALYZE shops;結果(After)
修正後、同じクエリを実行すると劇的に改善しました。
- レスポンス時間:12秒 → 45ミリ秒(約99.6%改善)
- 実行計画:Index Scan using idx_shops_geom_geog に変更
- Buffer使用量:45,000ページ → 120ページに削減
「データベースの内部動作理解」がこうしたパフォーマンス問題の解決に役立ちます。mongobleedで発覚したMongoDB脆弱性記事も参考にしてください。
IT女子 アラ美空間インデックス設計のベストプラクティス
ケーススタディで学んだ内容を一般化し、空間インデックス設計のベストプラクティスを整理します。
SRID(空間参照系)の統一
SRID(Spatial Reference System Identifier)は、座標系を識別する番号です。日本でよく使われるのは以下の通りです。
- SRID 4326:WGS 84(GPS座標系)。緯度・経度で表現
- SRID 6668:JGD2011(日本測地系2011)
- SRID 32654:UTM Zone 54N(東京周辺でメートル単位の計算に便利)
-- SRIDの確認
SELECT DISTINCT ST_SRID(geom) FROM shops;
-- SRIDの統一
ALTER TABLE shops
ALTER COLUMN geom TYPE geometry(Point, 4326)
USING ST_SetSRID(geom, 4326);geometry型とgeography型の使い分け
PostGISには2つの空間データ型があります。プロジェクトの要件に応じて選択しましょう。
- geometry型:平面座標系。計算が高速だが、地球の丸みを考慮しない
- geography型:地球楕円体上の座標。距離計算が正確だが、やや遅い
要件に応じた型選択が重要で、jotaiでReact状態管理を効率化する記事で触れた「適材適所の設計」の考え方も参考になります。
さらなる年収アップやキャリアアップを目指すなら、ハイクラス向けの求人に特化した以下のサービスがおすすめです。
| 比較項目 | TechGo | レバテックダイレクト | ビズリーチ |
|---|---|---|---|
| 年収レンジ | 800万〜1,500万円ハイクラス特化 | 600万〜1,000万円IT専門スカウト | 700万〜2,000万円全業界・管理職含む |
| 技術スタック | モダン環境中心 | Web系に強い | 企業によりバラバラ |
| リモート率 | フルリモート前提多数 | 条件検索可能 | 原則出社も多い |
| おすすめ度 | 技術で稼ぐならここ | A受身で探すなら | Bマネジメント層向け |
| 公式サイト | 無料登録する | - | - |
IT女子 アラ美まとめ
PostGISの空間インデックスとANALYZE統計情報について、実践的な視点から解説しました。本記事のポイントを振り返ります。
- GiSTインデックス:空間データはR-Tree構造のGiSTインデックスで高速化
- ANALYZEの重要性:統計情報が古いとプランナーが最適な実行計画を選べない
- SRIDの統一:混在するとインデックスが効かないケースがある
- geometry vs geography:要件に応じて適切な型を選択
- EXPLAIN ANALYZE:問題発生時は必ず実行計画を確認
地理空間データベースのパフォーマンス問題は、表面的な対処ではなく、インデックスとプランナーの動作を理解することで根本解決できます。まずはEXPLAIN ANALYZEで現状を把握することから始めてみてください。
IT女子 アラ美









