IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
ミニPCを買って Ollama を入れたまでは良いものの、HuggingFace や Ollama Library を眺めても「どのモデルをどの量子化レベルで動かせばいいのか」がわからず止まっているエンジニアが増えています。70B級を選んでメモリ枯渇でクラッシュしたり、逆に3B級を選んで使い物にならず結局クラウドAPIに戻ったという声をよく聞きます。本記事では、メモリ16〜32GBのミニPCで実用に耐えるローカルLLM選定を、コーディング・翻訳・要約の用途別に整理して解説します。
読者の悩みと背景の整理:ローカルLLMモデルが多すぎて選べない3つの理由
IT女子 アラ美自宅運用+クラウドPC併用で月額3,300円から、業務環境を独立できます
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
ローカルLLMをミニPCで動かしたいエンジニアやPjMが最初に詰まるのが、「どのモデルをどの量子化レベルでダウンロードするか」という選定問題です。HuggingFace や Ollama Library を眺めても、Llama 3・Mistral・Qwen・DeepSeek-Coder など派閥が多すぎて、自分の用途に合う1本を即決できません。ミニPCで実用に耐える構成を組むには、まずこの選定で詰まる構造的な原因を整理することが近道です。
- モデル数の爆発的増加:Llama・Mistral・Qwen・DeepSeek・Gemma・Phi など主要ファミリーだけで毎月のように新バージョンが出ています。Ollama Library 公式に登録されているモデルだけで100種類超、HuggingFace を含めると数千件あり、コーディング特化・日本語特化・長文対応など強みを比較するだけで疲弊します
- 量子化レベルの選択肢が多い:同じモデルでも Q2_K・Q3_K_M・Q4_0・Q4_K_M・Q5_K_M・Q6_K・Q8_0・FP16 と、品質とサイズのトレードオフを表す量子化レベルが5〜8段階用意されています。ファイルサイズが2倍違えば必要RAMも2倍違うため、選定ミスが即クラッシュにつながります
- ベンチマーク数値と実用感の乖離:MMLU・HumanEval・MT-Bench などの公開ベンチマーク数値は参考にはなりますが、ミニPCのメモリ制約下で「コーディング・翻訳・要約」に使ったときの実用感は別物です。スコアが高くてもミニPCでは遅すぎたり、逆にスコアが低くても用途次第で十分使えるケースが多々あります
GPUを持たないミニPC環境でローカルLLMを実用速度に乗せる選択肢としては、量子化以外に「1bit化」というアプローチもあります。このあたりは 1ビットLLM Bonsai-8B完全ガイド:GPU不要で実用レベルの推論を実現する仕組みと導入手順 で詳しく整理しているので、量子化との比較材料として併読することをおすすめします。
IT女子 アラ美ケーススタディ1:オーバースペックモデルを選んでミニPCが固まった失敗パターン
IT女子 アラ美PjMとして関わっている開発チームで、メンバーの林田さん(仮名)がメモリ16GBのミニPCを購入し、Ollama を導入したときの失敗ケースを紹介します。「せっかく買ったんだから一番性能の高いモデルを動かしたい」という発想で Llama 3 70B(Q4_K_M、約40GB)をダウンロードしようとし、最終的に環境ごと作り直す羽目になった事例です。
- 状況:メモリ16GB・SSD 512GBのミニPCに Ollama をインストール。最初に Llama 3 70B Q4_K_M(約40GB)を
ollama pullで取得しようとしたところ、SSD空きが先に枯渇してダウンロードがエラー終了。次に Llama 3 70B のさらに小さい量子化版(Q3_K_M)に切り替え、ダウンロードは完了したものの起動時にメモリスワップが発生し、ミニPCが数十秒間応答しない状態になった - なぜうまくいかなかったのか:モデルファイルサイズだけを見て「OSのページングで何とかなる」と判断していました。実際には、Ollama は推論時にモデル本体のほぼ全量をメモリに展開する必要があり、メモリ16GBのマシンで30GB級のモデルを起動すれば破綻するのが当然です。また、推論レスポンスが毎秒0.3トークン程度しか出ず、コード補完用途では完全に実用範囲外でした
- 当時の認識ギャップ:「量子化したから小さくなった=動く」「パラメータ数が大きい=必ず賢い」という2つの誤解が重なっていました。実際のミニPC運用では、利用可能RAMから OS・常駐アプリ用に4GB程度を引いた残りが「動かせるモデルサイズ上限」になります。16GB ミニPCなら8〜9GB級のモデル、つまり 8B Q4_K_M〜Q5_K_M クラスが現実解です
このケースで最終的に落ち着いたのは、Llama 3 8B Q4_K_M(約4.7GB)と DeepSeek-Coder 6.7B Q4_K_M(約3.8GB)の2モデル併用構成でした。Cursor などのエディタからローカルLLMを呼び出す具体的な接続方法は Claude Code・CursorでローカルLLMを使う完全ガイド:Ollama連携でコスト削減とプライバシー保護を両立する設定術 にまとめているので、モデル選定後の実装フェーズで参考にしてください。
IT女子 アラ美ケーススタディ2:用途別に量子化レベルを使い分けて運用が回った成功パターン
同じチームの別メンバー、久保さん(仮名)はメモリ32GBのミニPCで Ollama を運用しており、用途別に3モデルを使い分けることで日常業務にローカルLLMを組み込んでいます。林田さんの失敗ケースを踏まえ、「全部を1モデルで賄わない」を徹底した結果、安定運用とコスト削減を両立できた成功パターンです。
- 用途別の構成:コーディング補完には DeepSeek-Coder 6.7B Q4_K_M(約3.8GB)を Ollama で常駐させ、Cursor から呼び出し。翻訳・要約(日↔英・英↔日)には日本語精度が高い Qwen2.5 7B Q4_K_M(約4.4GB)を都度起動。長文要約や設計レビュー用のレポートだけ Qwen2.5 14B Q4_K_M(約8.5GB)を週次で起動する三段運用にしました
- 整えた前提環境:32GBメモリのうち常駐枠は1モデル(最大8.5GB)に限定し、残り20GB以上をOS・ブラウザ・IDE・Docker用に確保。SSDは1TB NVMe を選定し、3モデル分のキャッシュ(合計約17GB)を常時保持。Ollama の
OLLAMA_KEEP_ALIVE=5mを設定し、5分使われなければモデルがメモリから解放される構成にしています - 結果として変わったこと:Claude API・GPT-4o API の月額消費が約12,000円から約3,000円へ75%削減。コード補完のレスポンスは平均0.4秒で、クラウドAPIに体感差なし。さらに、社外秘のコードや顧客名を含むメモを翻訳する際の心理的ハードルが消え、データを手元から出さずに済むという副次効果が大きかったといいます
「常駐は軽量モデル1つ・重いタスクだけ大型を都度起動」という割り切りが、ミニPC×ローカルLLM運用を成立させる中核ルールです。なお、ミニPC本体の選び方そのもの(メモリ・SSD・冷却設計)については 自宅AI開発機の選び方ガイド:ローカルAIが動くミニPC4社比較(GMKtec/MINISFORUM/MDL.make/Acer) で4社の実機比較をまとめているので、購入前に確認してみてください。
IT女子 アラ美具体的な行動ステップ:用途別おすすめモデルと量子化レベルのチェックリスト
ミニPCでローカルLLM運用を始めるなら、メモリ容量という制約を起点に「動かせるモデルサイズ→用途別に常駐モデル→2モデル目以降」の順で段階的に決めるのが最も失敗の少ないルートです。下のグラフは、Q4_K_M量子化での主要モデル別ファイルサイズです。動かせるモデルサイズの目安は「利用可能RAM − 4GB」で、16GBミニPCなら約12GBが上限になります。
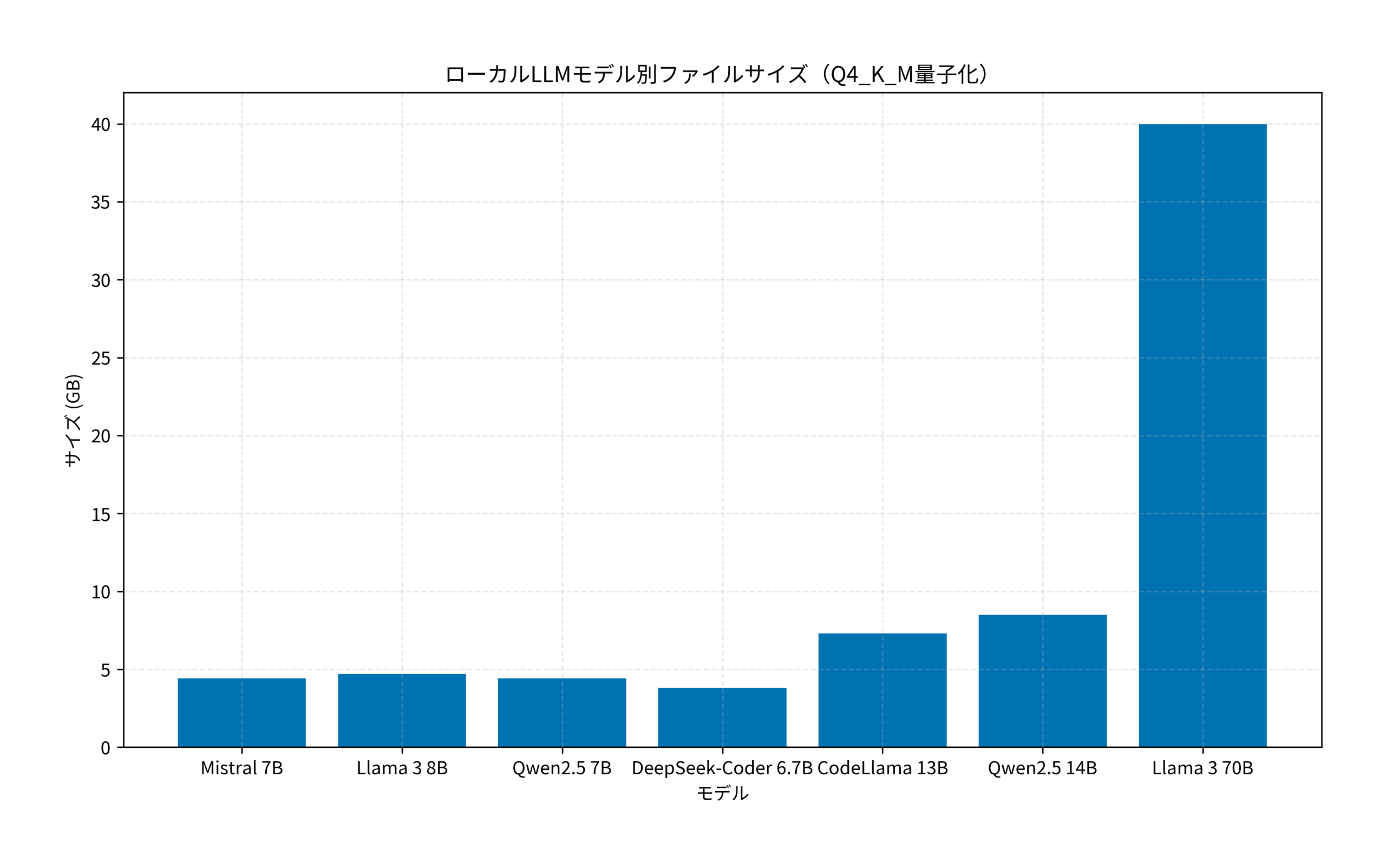
- メモリ容量と上限モデルを確認する:16GBなら 8B Q4_K_M クラス(約4.7GB)まで、32GBなら 14B Q4_K_M クラス(約8.5GB)まで、64GB以上なら 30B Q4_K_M クラス(約20GB)までが現実解。70Bは64GBでもギリギリで、推論速度を求めるなら手を出さない方が無難です
- メイン用途を1つ決めて常駐モデルを選ぶ:コーディング補完なら DeepSeek-Coder 6.7B Q4_K_M、翻訳・要約(特に日本語)なら Qwen2.5 7B Q4_K_M、汎用チャット・分析なら Llama 3 8B Q4_K_M を初手に選ぶと外しません
ollama pullで取得→ollama psで実RAM消費を確認:ダウンロード後に1〜2件プロンプトを投げて、メモリ消費が想定内か検証します。ここでOLLAMA_KEEP_ALIVEを5〜10分に設定し、未使用時は自動解放させる構成にしておくと安全です- EditorやAPIクライアントから接続する:Cursor・Continue.dev・Open WebUI などは
http://localhost:11434を Ollama API として登録するだけで接続できます。ここまでで日常業務に組み込める状態になります - 2週間運用してから2モデル目を追加する:最初から3モデル入れない。1モデルで業務が回ることを確認してから、不足を感じた領域だけ別モデルを追加するのが、容量と運用コストの両面で最も無駄が出ません
ローカルLLMを自分で組める力は、開発環境を会社に依存しない働き方やAI寄りのポジション(フルスタック・SRE・MLOpsなど)への転身でも武器になります。キャリア選択肢の整理は フルスタックエンジニアはやめとけ?現役PjMが解説するキャリアの現実と生存戦略 も併せて読むと、技術投資の方向性が見えやすくなります。
IT女子 アラ美よくある質問
Q. メモリ8GBのミニPCでもローカルLLMは動かせますか?
A. 動かせるのは Phi-3 Mini(3.8B Q4_K_M、約2.3GB)や Gemma 2B Q4_K_M(約1.5GB)クラスまでです。コード補完用途では精度が物足りない場面も多いため、本格運用したいなら最低でもメモリ16GBのミニPCを選び直すことをおすすめします。8GB環境はあくまで「動作確認・遊び」用と割り切るのが現実的です。
Q. GPUのないミニPCでも実用速度が出ますか?
A. CPU推論でも、8B Q4_K_Mクラスなら毎秒5〜10トークン程度は出ます。コーディング補完・翻訳・要約など「短い応答」を主とする用途なら体感的に問題ありません。逆に、長文の生成や設計レビューなど「数千トークン出力」を求める用途では、GPU内蔵モデル(AMD Ryzen 7000シリーズの内蔵Radeonなど)か外付けeGPUの検討余地があります。
Q. 量子化レベルは Q4_K_M 以外を選んだ方が良いケースはありますか?
A. 精度を最優先したい場合は Q5_K_M・Q6_K を、サイズを最優先したい場合は Q3_K_M を選びます。ただし、ミニPC前提では Q4_K_M が「品質・サイズ・速度」の3点でバランス最適というのが2026年時点のコミュニティ標準的な見解です。最初は Q4_K_M から入り、不足を感じた次元だけ調整するのが効率的です。
Q. 法人利用ではローカルLLMだけで運用できますか?
A. 機密情報を扱う場面ではローカルLLMが最有力ですが、最新モデル比較や大量バッチ処理ではクラウドAPIが優位です。実務では「機密データはローカル、公開データはクラウド」のハイブリッド運用が主流です。クラウドPCやレンタルサーバーを業務専用に切り出す場合の選び方は エンジニア向けXServer用途別比較ガイド に詳しい比較がまとまっているので、ローカル+クラウドのいいとこ取り構成を組む際の参考にしてください。
ローカルLLMを自分で構築・運用できるエンジニアは、社内SE・AIエンジニア・ハイクラス転職のいずれでも市場価値が高まります。下記の比較表でフェーズに合うキャリアサービスを確認してみてください。
エンジニアとしての技術力を武器に、ITコンサルタントやマネジメント職へキャリアアップしたい方は、以下の特化型エージェントがおすすめです。
| 比較項目 | strategy career | MyVision | テックゲートエキスパート |
|---|---|---|---|
| ポジション | CTO・テックリードDevOps・海外リモートも | 戦略・IT・総合コンサルBig4含む | PM・PMO・DX推進上流ポジション |
| 年収レンジ | 高年収+自由な働き方 | コンサル水準 | 20〜30代向け |
| 選考対策 | キャリア戦略の棚卸し | ケース面接対策充実 | 面接対策・条件交渉 |
| おすすめ度 | 技術力×高年収 | Aコンサル特化なら | B20代のPM志望 |
| 公式サイト | 無料相談する | - | - |
IT女子 アラ美まとめ
ミニPCでローカルLLMを実用速度で動かす鍵は、「メモリ容量−4GB」を上限としてモデルサイズを決め、用途別に常駐1個+切替2〜3個の三段運用に持ち込むことです。70B級を最初に狙ってクラッシュさせるよりも、8B Q4_K_Mから入って業務に組み込み、必要なときだけ14B級に上げる進め方の方が、結果的にコストも運用負荷も抑えられます。
- 動かせるモデル上限は「利用可能RAM−4GB」:16GBミニPCなら約12GBが上限、70B級は最初から候補から外して問題ない
- 用途別に常駐1個+切替2〜3個:コーディング DeepSeek-Coder 6.7B、翻訳・要約 Qwen2.5 7B、重い分析 Qwen2.5 14B が2026年時点のバランス解
- クラウドAPI月額を75%削減した実例も:月12,000円→3,000円の削減+社外秘データを手元に置ける副次効果が大きい
完璧な構成を最初から目指さず、まずは1モデルだけ ollama pull で取得し、2週間日常業務で使ってみるところから始めてみてください。「クラウドAPIに毎月いくら払っているか」を1度棚卸しするだけでも、ミニPC投資の回収期間が現実的に見えてきます。最初の選定で迷ったら、本記事の「メモリ容量別チェックリスト」に立ち戻れば外しません。
厳しめIT女子 アラ美による解説ショート動画はこちら
IT女子 アラ美