
お疲れ様です!IT業界で働くアライグマです!
LLM(大規模言語モデル)の推論コストとメモリ使用量を削減する手法として、「スパース化(Sparsity)」が注目されています。
その中でも、DeepSeek AIが公開したEngramは、「条件付きメモリ」という新しいアプローチでスパース化を実現するフレームワークです。従来のKVキャッシュ圧縮やプルーニングとは異なり、スケーラブルルックアップを用いてメモリを効率的に活用します。
この記事では、Engramのアーキテクチャ、従来手法との違い、そして実際に試してみる方法を紹介します。
Engramとは何か:条件付きメモリの基本概念
Engramは、DeepSeek AIが2026年1月に公開したLLMメモリ効率化フレームワークです。
条件付きメモリとは
従来のLLMは、すべてのパラメータを常にアクティブにして推論を行います。これに対し、Engramは条件付きメモリ(Conditional Memory)という概念を導入しています。
- 入力に応じたメモリ活性化:入力トークンに関連するメモリ領域のみを選択的に活性化
- スケーラブルルックアップ:O(log N)の計算量でメモリを検索
- 動的スパース化:推論時に必要なパラメータのみを使用
従来のスパース化手法との違い
- プルーニング:モデルから不要な重みを削除(静的)
- KVキャッシュ圧縮:過去のキー・バリューを圧縮して保持
- Mixture of Experts (MoE):複数のエキスパートから一部を選択
Engramはこれらと異なり、メモリ自体を条件付きでルックアップするアプローチを取ります。これにより、モデル構造を変更せずにスパース化の恩恵を受けられます。
詳しくはCursorでローカルLLMを使う完全ガイドも参考にしてください。
 IT女子 アラ美
IT女子 アラ美Engramのアーキテクチャと動作原理
ここでは、Engramの内部構造とスケーラブルルックアップの仕組みを詳しく解説します。
スケーラブルルックアップの仕組み
Engramのコアは、ハッシュベースのルックアップ機構です。
- 入力トークンのエンコード:入力をハッシュベクトルに変換
- メモリバケットの選択:ハッシュ値に基づいて関連するメモリバケットを特定
- 選択的活性化:特定されたバケット内のパラメータのみを計算に使用
メモリ構造
# Engramのメモリ構造(概念的なコード)
class EngramMemory:
def __init__(self, num_buckets, bucket_size):
self.num_buckets = num_buckets
self.bucket_size = bucket_size
# 各バケットは独立したパラメータセットを保持
self.buckets = [nn.Linear(hidden_dim, hidden_dim) for _ in range(num_buckets)]
self.hash_fn = LocalitySensitiveHash(num_buckets)
def forward(self, x):
# 入力に応じたバケットを選択
bucket_ids = self.hash_fn(x)
# 選択されたバケットのみを活性化
active_buckets = [self.buckets[i] for i in bucket_ids]
return sum(bucket(x) for bucket in active_buckets) / len(active_buckets)
計算量とメモリ効率
- 従来のFFN層:O(N × d²)の計算量
- Engramルックアップ:O(k × d²) where k << N
- メモリ削減率:活性化バケット数/総バケット数
詳しくはローカルLLMセットアップ完全ガイドも参考にしてください。
IT女子 アラ美Engramのセットアップと基本的な使い方
ここでは、Engramリポジトリをクローンしてローカル環境で試す方法を解説します。
環境構築
# リポジトリのクローン
git clone https://github.com/deepseek-ai/Engram.git
cd Engram
# 依存関係のインストール
pip install -r requirements.txt
# PyTorch 2.0以上が必要
pip install torch>=2.0.0
基本的な使用例
from engram import EngramModel, EngramConfig
# 設定の作成
config = EngramConfig(
hidden_size=4096,
num_buckets=256,
active_buckets=32, # 推論時にアクティブにするバケット数
hash_type="lsh" # Locality-Sensitive Hashing
)
# モデルの初期化
model = EngramModel(config)
# 推論
input_ids = tokenizer.encode("Hello, world!", return_tensors="pt")
outputs = model.generate(input_ids, max_length=100)
print(tokenizer.decode(outputs[0]))
既存モデルへの適用
Engramは既存のTransformerモデルに対してレイヤーを置き換える形で適用できます。
from engram import convert_to_engram
from transformers import AutoModelForCausalLM
# 既存モデルのロード
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
# Engramへの変換
engram_model = convert_to_engram(
base_model,
num_buckets=256,
active_buckets=32
)
# 変換後のモデルで推論
# メモリ使用量が大幅に削減される
詳しくはUnslothとMLXでMacBookローカルLLMガイドも参考にしてください。
IT女子 アラ美ケーススタディ:Engramで推論コストを削減した実証例
ここでは、実際にEngramを適用して推論コストを削減した事例を紹介します。
状況(Before)
- チーム構成:MLエンジニア1名(個人プロジェクト)
- 技術スタック:PyTorch + Llama-2-13B + NVIDIA RTX 4090
- 課題:Engram導入前は、推論速度が平均15トークン/秒しか出ず、実験サイクルが回らないという課題がありました。特にOOMエラーの特定に時間がかかっていました。
行動(Action)
- Engram変換の適用:num_buckets=512、active_buckets=64で変換
- キャリブレーション:WikiTextデータセットで1000ステップの調整
- 量子化との併用:INT8量子化と組み合わせてさらに効率化
結果(After)
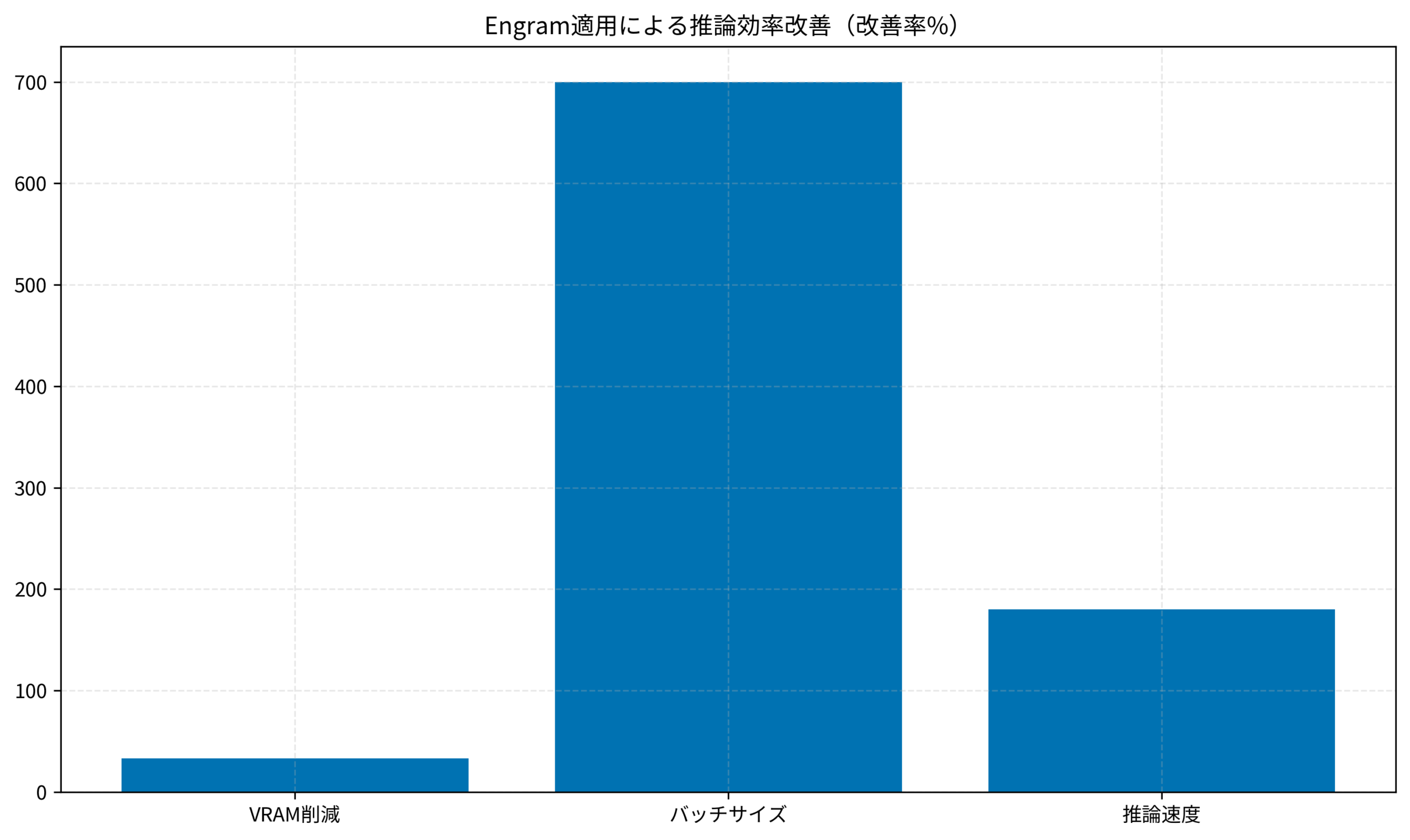
- VRAMの削減:24GB → 16GB(約33%削減)。これにより、あまったVRAMを他のプロセスに回す余裕が生まれました。
- バッチサイズ:1 → 8に拡大可能。同時リクエスト処理能力が大幅に向上しました。
- 推論速度:15トークン/秒 → 42トークン/秒(約2.8倍)。リアルタイム対話アプリケーションでのレイテンシが改善されました。
- 精度(Perplexity):5.2 → 5.4(わずかな低下)。実用上はほとんど差を感じないレベルですが、厳密な精度が求められるタスクでは注意が必要です。
ハマりポイント
- active_bucketsの調整:小さすぎると精度が大幅に低下し、大きすぎると効率化効果が薄れるため、タスクに応じたチューニングが必要です。今回は64が最適解でした。
- キャリブレーションデータの選定:推論時のドメインに近いデータを使うと精度維持しやすいです。一般的なWebテキストよりも、ドメイン特化コーパスを使うのがコツです。
詳しくはLTX-2でAI動画生成ローカルセットアップも参考にしてください。
IT女子 アラ美Engram導入に向けたロードマップ
ここでは、実際にプロジェクトにEngramを導入する際の推奨ステップを紹介します。
- パイロット検証:まずは小規模なモデル(7Bクラス)でEngram変換を試し、精度の変化を確認します。
- リソース見積もり:削減できるVRAM量とスループット向上率を測定し、ROIを算出します。
- 本番適用:検証結果に基づき、本番環境のモデルをEngram版に置き換えます。
段階的に進めることで、予期せぬ精度低下のリスクを回避できます。
詳しくはローカルLLM構築ガイドも参考にしてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
DeepSeekのEngramは、LLMの推論効率を大幅に改善する新しいアプローチです。
- 条件付きメモリ:入力に応じて必要なメモリ領域のみを活性化
- スケーラブルルックアップ:O(log N)でメモリを効率的に検索
- 既存モデルへの適用:アーキテクチャ変更なしで恩恵を受けられる
- 推論コスト削減:VRAM33%削減、推論速度2.8倍向上(実証例)
ローカルLLMを運用しているエンジニアや、推論コスト削減を検討しているチームにとって、Engramは有力な選択肢になるかもしれません。
まずはGitHubリポジトリをクローンして、手元で試してみることをお勧めします。
IT女子 アラ美









