
お疲れ様です!IT業界で働くアライグマです!
「仕様書の矛盾が実装フェーズで見つかる」「エッジケースの考慮漏れで手戻りが発生する」。こんな経験、エンジニアなら一度はありますよね。
一人で仕様を詰めていると、どうしても「思い込み」や「正常系バイアス」がかかってしまいます。もし、性格の悪いレビュアーが3人いて、24時間文句を言い合ってくれたら、仕様はもっと完璧になると思いませんか?
今回は、Claude Codeのプラグイン「adversarial-spec」を紹介します。これは、複数のLLMモデル(Claude 3.5 SonnetやGPT-4oなど)に「議論」をさせ、仕様書の矛盾や考慮不足を徹底的に洗い出すツールです。
adversarial-specとは:AI同士の「議論」実装
adversarial-specは、Antropic公式のCLIツール「Claude Code」向けに開発されたサードパーティ製プラグインです。「Adversarial(敵対的)」という名の通り、あるモデルが作成した仕様に対して、別のモデルが批判的な指摘を行い、それを修正するというサイクルを自動化します。
「一人ブレスト」の限界を超える
通常、ChatGPTなどに「この仕様書の欠点を指摘して」と頼んでも、当たり障りのない回答しか返ってこないことがあります。単一のコンテキストでは「空気を読んで」しまうからです。CLIツールの環境構築については、Ghosttyの設定ガイドなども参考にしつつ、快適なターミナル環境を整えておきましょう。
adversarial-specは、以下のような役割分担を強制します。
- Lead Architect: 仕様の初版を作成し、指摘を受けて修正する。
- Critic (Devil’s Advocate): 意地悪なレビュアー。エッジケース、セキュリティリスク、整合性を徹底的に攻撃する。
- Moderator: 議論がループしないように制御し、合意形成(Consensus)を判定する。
 IT女子 アラ美
IT女子 アラ美なぜ「マルチエージェント」が有効なのか
単一のLLM(Single Agent)と、複数のLLM(Multi-Agent)では、生み出される成果物の質が異なります。
多角的な視点の確保
人間がチーム開発をするのと同様に、AIも「異なるプロンプト(人格)」を持つエージェント同士で対話させることで、ハルシネーション(嘘)や論理矛盾を相互監視できます。
特に仕様策定においては、「実装の容易さ」を優先する視点と、「ユーザー体験」を優先する視点、「セキュリティ」を優先する視点がぶつかり合うことが重要です。adversarial-specはこれをシミュレーションします。
議論による精度の向上過程
実際に議論を行うと、仕様書のスコアはどう変化するのでしょうか。以下は、3回の議論ラウンドを経た場合の矛盾件数と具体性スコアの推移イメージです。
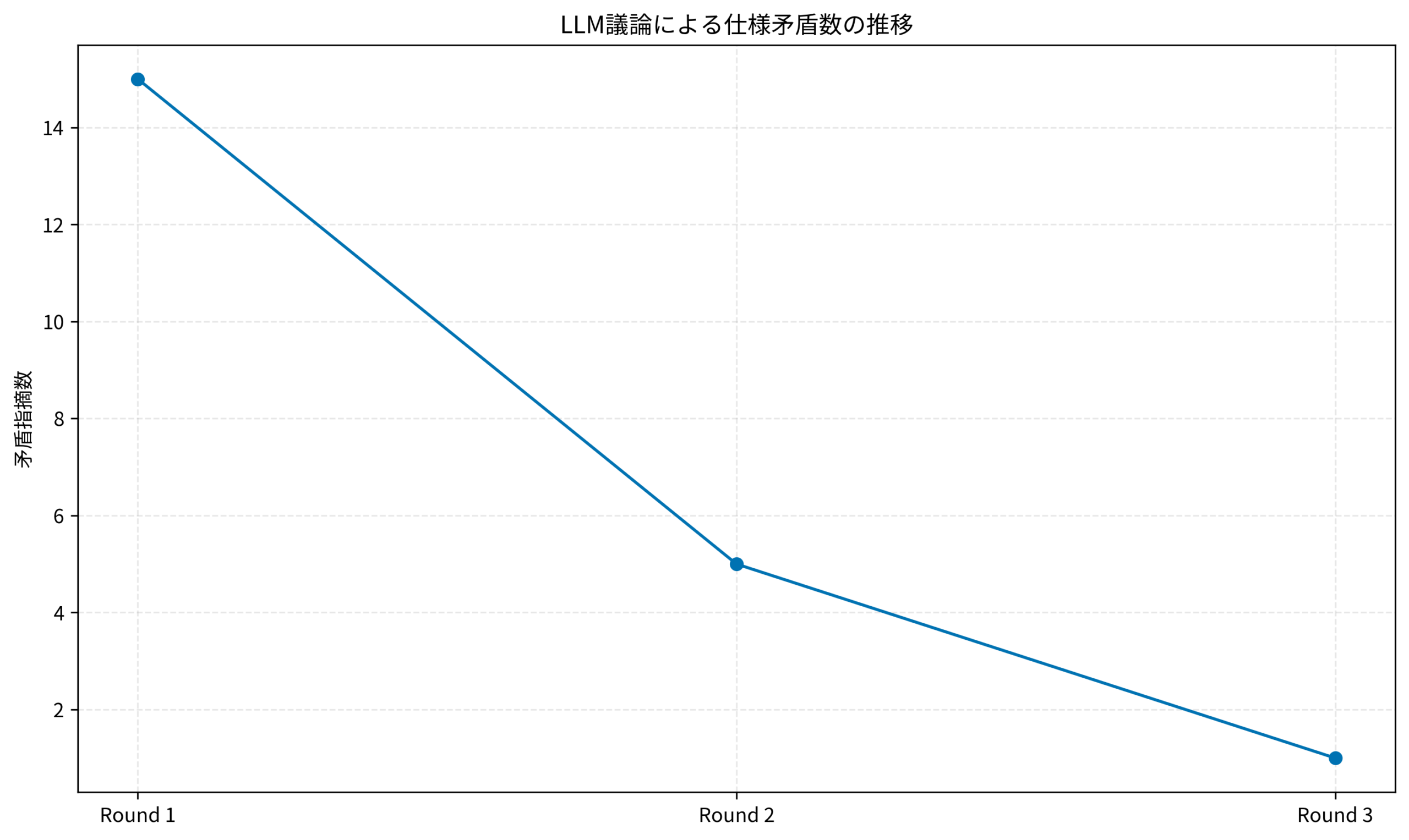
ラウンド1で大幅に矛盾が減り、ラウンド2以降で細かいエッジケースが詰められていく様子がわかります。こうした可視化は、claude-hudによるモニタリングと同様に、AIの作業プロセスを透明化する上で重要です。
IT女子 アラ美実践:Claude Codeによるストライキ型仕様策定
では、実際にadversarial-specを使って、簡単なTODOアプリの仕様書を策定してみましょう。「認証機能」という曖昧な要件からスタートします。
インストールとセットアップ
Claude Codeがインストールされている前提で、プラグインを追加します(※現在はPoC実装のため、リポジトリからスクリプトを実行する形式が一般的です)。
# リポジトリのクローン
git clone https://github.com/zscole/adversarial-spec.git
cd adversarial-spec
# 依存関係のインストール(Python環境)
pip install -r requirements.txt
# 設定ファイル(config.example.yaml)の準備
cp config.example.yaml config.yaml議論の実行
以下のコマンドで、トピックを指定して議論を開始します。こうした自動化スクリプトの活用は、ローカルLLM環境の構築など、他のAI開発でも応用できる考え方です。
python main.py --topic "セキュアで見やすいTODOアプリの認証機能" --rounds 3コンソールには、ArchitectとCriticの激しいやり取りが表示されます。
Critic: パスワードリマインダー機能についての記述がありません。攻撃者が列挙攻撃を行える可能性があります。
Architect: 指摘を受け、レートリミット機能とCAPTCHAの導入を追記しました。
Critic: CAPTCHAはUXを損ないます。Turnstileなどの代替手段を検討すべきです。
このように、自動で仕様がブラッシュアップされていきます。
設定ファイルのカスタマイズ
config.yaml で、各Agentの「性格(Prompt)」を調整できます。
models:
architect:
model: "claude-3-5-sonnet-20241022"
temperature: 0.7
critic:
model: "gpt-4o" # 批判役には論理性重視のモデルを
temperature: 0.2
system_prompt: "あなたは非常に厳格なセキュリティ監査員です。些細な脆弱性も見逃しません。"このように、Critic役に「意地悪な設定」を詰め込むのがコツです。
IT女子 アラ美実践ケーススタディ:曖昧な要件定義書をブラッシュアップする
ここでは、あるスタートアップ企業で実際にこの手法を導入した事例を紹介します。
状況(Before)
- 状況: 新規サービスの開発現場。PMが非エンジニア出身で、仕様書が「ふわっと」しがちだった。
- 課題: 実装者が独自解釈でコードを書き、リリース直前に「これじゃない」と差し戻しが発生。レビュー工数が開発工数を圧迫していた。
- 現場の声: 「仕様が決まっていないのにコードを書かされるのが辛い」「後出しジャンケンで修正させられる」
行動(Action)
テックリード主導で、GitHub Actionsにadversarial-specを組み込みました。
- 仕様書のCode化: UI仕様やAPI仕様をMarkdownで記述し、リポジトリ管理を開始。
- 自動レビューの導入: PR作成時にadversarial-specが走り、Architect役のLLMが仕様書を自動修正。Critic役のLLMが承認しない限りマージできないルールを設定。
- 人間の役割変更: 人間は「AI同士の議論ログ」を確認し、最終的なビジネス判断(コストvs品質のバランスなど)のみを行うフローに変更。
こうしたコーディング以外のスキルセット向上は、コーディングテストなしで内定を勝ち取る戦略と同様に、エンジニアとしての生存戦略において非常に重要です。
IT女子 アラ美導入後の成果:手戻り削減とチームの変化
adversarial-specの導入により、現場には大きな変化が生まれました。
結果(After)
- 手戻り減少: 実装着手前の「仕様バグ」検知率が70%向上。開発の手戻りによるロスが激減した。
- 心理的安全性: 指摘が「AIから」来るため、PMとエンジニアの感情的な対立が消滅。「敵はAI、我々はチーム」という構造ができた。
- ドキュメント品質: 常に最新かつ詳細な仕様書が維持されるようになった。
こうしたキャリア設計については、エンジニアからEMへのロードマップを参考に、チーム全体のスループット向上を意識すると良いでしょう。
自分のスキルを活かしてフリーランスとして独立したい、あるいは副業で収入を得たいと考えている方は、以下のエージェントを活用するのが近道です。
| 比較項目 | Midworks | レバテックフリーランス | PE-BANK |
|---|---|---|---|
| 保障・安心感 | 正社員並みの手厚さ給与保障・福利厚生あり | 一般的案件数は業界最多 | 共済制度あり確定申告サポート等 |
| 単価・マージン | 低マージン・公開 | 非公開 | 明朗会計(公開) |
| 案件獲得の手間 | リモート・週3など柔軟 | 高単価案件が豊富 | 地方案件に強い |
| おすすめ度 | 独立直後〜中級者 | Aガッツリ稼ぐなら | Bベテラン・地方 |
| 公式サイト | 案件を探す | - | - |
IT女子 アラ美まとめ
adversarial-specは、単なる自動化ツールではなく、「議論」というプロセスそのものをエンジニアリングする新しいアプローチです。
一人で悩む時間はもう終わりです。優秀なAIアシスタントたちに、徹底的に議論してもらいましょう。
- 「敵対的」な関係を作る: 肯定的な意見だけでは品質は上がらない。
- 異種モデルを組み合わせる: 異なる視点で死角をなくす。
- 人間は「審判」になる: 詳細なチェック作業から解放され、意思決定に集中する。
このフローを取り入れて、あなたのチームの開発プロセスを一段階進化させてみてください。
IT女子 アラ美









