IT女子 アラ美
IT女子 アラ美法人向け高速サーバーでAI開発環境を本格的に構築する方法があるわよ
24万社が導入!法人向けレンタルサーバー【XServerビジネス】
お疲れ様です!IT業界で働くアライグマです!
「ChatGPTやClaudeは便利だけど、プロプライエタリなデータを送るのは怖い…」
「ローカルLLMを試したいけど、環境構築が難しそう…」
そんな悩みを解決する決定版がついに登場しました。DeepSeek-R1です。
OpenAI o1に匹敵する推論性能を持ちながら、商用利用可能なオープンウェイトモデルとして公開され、世界中に衝撃を与えています。
今回は、このDeepSeek-R1を自宅のPC(Mac/Windows/Linux)で動かし、誰にも覗かれない完全プライベートなAI環境を構築する方法を解説します。
DeepSeek-R1とは:OpenAI o1に匹敵する「蒸留モデル」の衝撃
IT女子 アラ美クラウドPCならGPU搭載環境を月額定額で使えるわよ!
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
DeepSeek-R1は、中国のAI企業DeepSeekが開発した最新の推論モデルです。
従来のLLMと異なり、「思考の連鎖(Chain of Thought)」を強化した強化学習プロセスを経ており、数学やプログラミング、論理的推論において圧倒的な性能を発揮します。
特に注目すべきは、巨大な671Bモデルから知識を蒸留(Distillation)して作られた小型モデルの性能です。例えば、わずか8Bパラメータのモデルでも、Llama 3.1 8Bを大きく上回るスコアを叩き出しています。
この「蒸留」というプロセスにより、本来ならスーパーコンピュータが必要な高度な推論能力を、一般的なコンシューマー向けのGPUで再現できるようになったのが最大の革命点と言えるでしょう。(参考:AIエージェント開発の記事でも触れましたが、推論モデルは設計フェーズで威力を発揮します)
特に「コーディング中にローカルでAIに相談したい」というニーズには、応答速度と精度のバランスが取れた8B〜14Bモデルが最適解となります。
IT女子 アラ美構築ステップ1:Ollamaでモデルを動かす
実際に構築を始める前に、その性能を確認しておきましょう。
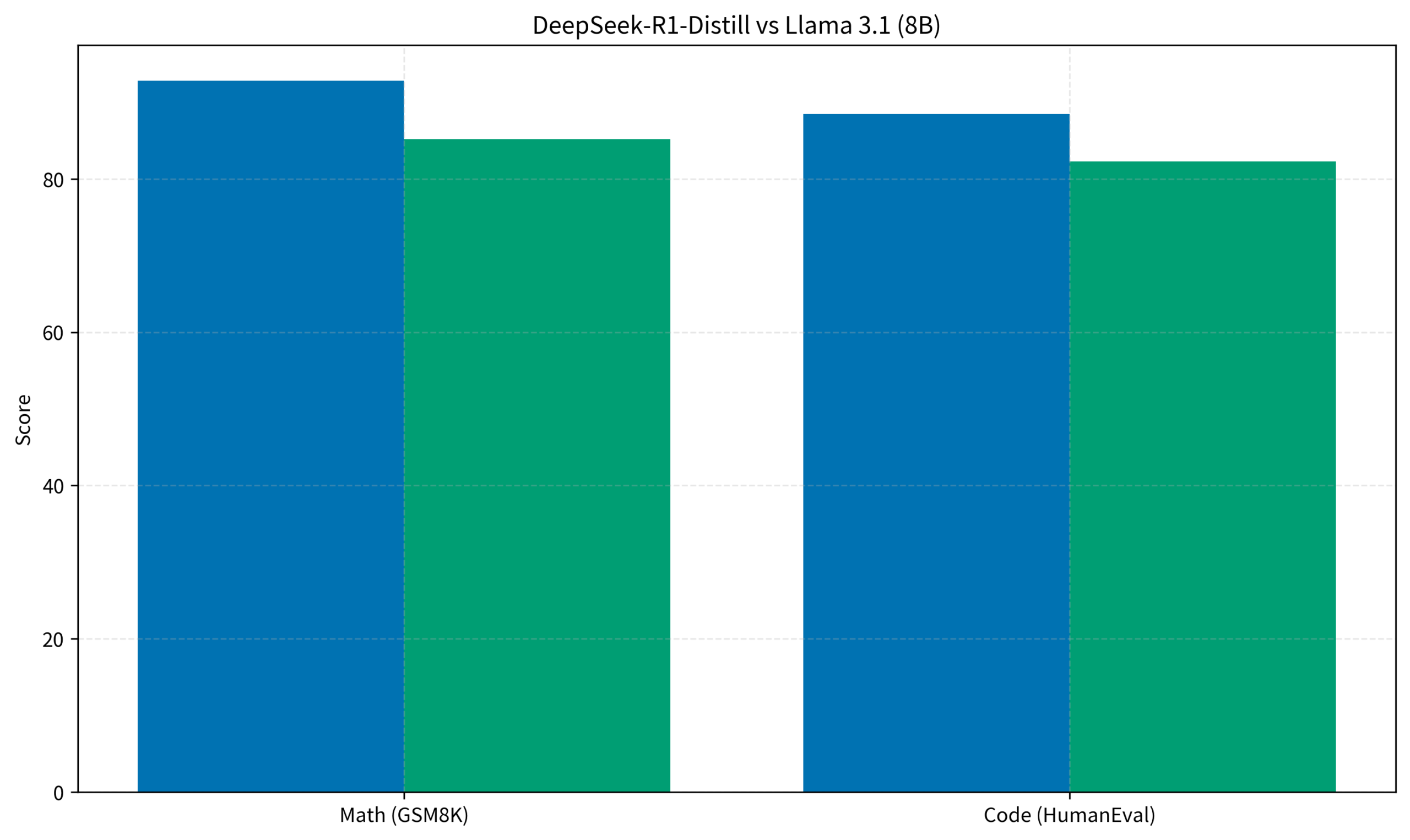
グラフの通り、数学(GSM8K)とコード生成(HumanEval)の両方で、同サイズのLlama 3.1を凌駕しています。これが、一般的なPCでサクサク動くのですから、試さない手はありません。
まずは、ローカルLLMランナーのデファクトスタンダードである「Ollama」をインストールします。
公式サイト(ollama.com)からインストーラーをダウンロードするか、Linux/WSLの場合は以下のコマンドで一発です。
curl -fsSL https://ollama.com/install.sh | shインストールが完了したら、DeepSeek-R1モデルをプルして実行します。
PCのスペックに合わせてサイズを選んでください(VRAM 8GBなら8b、16GBなら14bや32bが目安です)。
# 8Bモデル(軽快・一般的)
ollama run deepseek-r1:8b
# より高性能なモデルを試す場合
# ollama run deepseek-r1:14b
# ollama run deepseek-r1:32bこれだけで、コンソール上で対話が可能になります。「<think>」というタグで囲まれた部分が、AIの思考プロセスです。この思考プロセスこそがR1の特徴であり、どのように答えを導き出したかを透明性高く確認できるため、デバッグや学習用途にも非常に有用です(参考:WSL2環境の構築も確認してください)。
IT女子 アラ美構築ステップ2:Open WebUIでチャット画面を作る
コンソール画面(黒い画面)だけでは使いにくいので、ChatGPTライクなUIを追加しましょう。「Open WebUI」がおすすめです。
Dockerを使って簡単に立ち上げられます。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main起動後、ブラウザで http://localhost:3000 にアクセスし、アカウント作成(ローカル保存のみ)を行えば、Ollamaでダウンロードしたモデルを選択してチャットできます。
ドキュメント読み込み機能(RAG)やWeb検索機能も標準搭載されており、実用性はChatGPT Plusに匹敵します(参考:Docker管理ツールも併せると便利です)。特に「Web Search」機能をオンにすれば、DuckDuckGoなどを経由して最新情報を参照させることも可能になります。
IT女子 アラ美【ケーススタディ】ローカルRAGで社内規定QAボットを作る
IT女子 アラ美社内システムの技術選定に裁量を持てる環境で力を発揮しなさい
社内SEを目指す方必見!IT・Webエンジニアの転職なら【社内SE転職ナビ】
実際に、DeepSeek-R1とOpen WebUIを使って業務改善に成功した事例を紹介します。
状況 (Before)
石川さん(仮名・28歳・インフラエンジニア)が所属する従業員50名のIT企業。就業規則や経費精算のルールが、更新頻度の低い社内WikiやPDFファイルに散在していました。バックオフィス担当者の元には、毎日「交通費の申請方法は?」「慶弔休暇は何日?」といった同じような質問がSlackで飛び交っていました。検索機能も貧弱で、欲しい情報にたどり着くのに平均10分以上かかっていました。
行動 (Action)
社内サーバー(余っていたGPU搭載PC)にOllamaとOpen WebUIを構築しました。そこに社内規定のPDFファイルを「Documents」としてアップロードし、コレクション機能で「社内規定ボット」を作成。モデルには日本語性能と推論能力のバランスが良い deepseek-r1:14b を採用しました。導入コストはハードウェア代のみでゼロ円です(参考:自前サーバー構築も参照)。
結果 (After)
社員がボットに質問するだけで、「就業規則 第X条に基づき、慶弔休暇は〜日です」と正確に回答が返ってくるようになりました。Ollamaのエンドポイントを社内VPN内のみに公開することでセキュリティも確保。バックオフィスへの問い合わせ件数は約70%減少し、担当者は本来の業務に集中できるようになりました。社員からも「即座に回答が得られる」と大好評です。
IT女子 アラ美ローカルAI運用の注意点
DeepSeek-R1は強力ですが、運用にはいくつかの注意点があります。
自分の環境に合わせて適切な設定を行うことが、快適なAIライフの鍵となります(参考:WSL2環境の構築)。
VRAM容量の壁
モデルサイズが大きくなると、必要なVRAMも増えます。8bモデルなら8GBで足りますが、32bモデル以上を動かすなら、VRAM 24GBクラスのGPU(RTX 3090/4090)やMac Studioが欲しくなります。VRAMが不足するとシステムRAMを使用することになり、動作が極端に遅くなるので注意が必要です。
量子化による劣化
Ollamaで配布されているモデルは基本的に4bit量子化されています。オリジナル(FP16)に比べるとわずかに精度が落ちる場合があるので、厳密な精度が必要な場合は注意が必要です。ただし、DeepSeek-R1のような推論特化モデルの場合、量子化による影響は比較的少ないと言われています。
日本語の違和感
DeepSeekは中国語と英語に最適化されており、日本語も話せますが、たまに不自然な表現になることがあります。Open WebUIの「System Prompt」設定で「あなたは日本語のアシスタントです。常に自然な日本語で回答してください」と明示することで、品質を大きく改善できます。
IT女子 アラ美よくある質問
DeepSeek-R1はMacでも動きますか?
はい、Apple Silicon���Mac(M1/M2/M3/M4)で動作します。Unified MemoryをVRAMとして使用するため、16GB以上のメモリがあれば8b〜14bモデルを快適に実行できます。
DeepSeek-R1とClaude/GPT-4oはどう使い分けるべきですか?
機密データの処理やオフライン環境ではDeepSeek-R1、複雑な長文生成や最新情報が必要な場合はクラウドLLMと使い分けるのがベストです。ハイブリッド運用で費用対効果を最大化できます。
Open WebUIは社内ネットワークで安全に運用できますか?
VPN内限定のアクセスにすればセキュリティは万全です。Open WebUIはローカルサーバーとして動作するため、外部への通信は一切発生しません。
こうしたAI環境構築スキルを活かしたキャリアアップについてはハイクラスエンジニア転職エージェント3社比較も参考にしてください。
IT女子 アラ美おすすめのAI学習・キャリアサービスを比較
ローカルLLMの構築スキルをさらに深めたい方や、AIスキルを活かしたキャリアアップを検討中の方は、以下のサービスを比較してみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
DeepSeek-R1の登場により、高性能なAIを手元のPCで動かせる時代が到来しました。
OllamaとOpen WebUIを組み合わせれば、わずか数コマンドで最強のプライベートAI環境が手に入ります。
外部へのデータ流出を気にせず、思う存分AIを活用できる環境は、エンジニアにとって強力な武器になります。
ぜひこの週末に、自分だけの「AI相棒」を構築してみてください。
IT女子 アラ美