
 IT女子 アラ美
IT女子 アラ美pip installとPythonコードで即導入できます。
お疲れ様です!IT業界で働くアライグマです!
「ローカル環境でAI音声合成を動かしたいけど、どのモデルを選べばいいか分からない」
「感情表現やボイスクローンまで対応した高品質なTTSを試してみたい」
そんな悩みを持つエンジニアの方、多いのではないでしょうか。
2026年1月、Alibaba CloudのQwenチームからQwen3-TTSがオープンソースとして公開されました。
このモデルは、安定した音声生成に加えて、感情表現(Expressive Speech)、ストリーミング出力、さらにはゼロショットボイスクローンまで対応した本格的なTTSシステムです。
本記事では、Qwen3-TTSをローカル環境にセットアップして実際に音声を生成するまでの手順を、PjM視点での運用上の注意点も交えながら解説していきます。
Qwen3-TTSとは:オープンソースTTSの新たな選択肢
IT女子 アラ美Qwen3-TTSは、Alibaba CloudのQwenチームが開発したオープンソースのText-to-Speech(TTS)モデルシリーズです。
GitHub上で公開されており、Apache 2.0ライセンスで商用利用も可能なため、プロダクト開発にも組み込みやすいのが大きな特徴です。
Qwen3-TTSの主な特徴
Qwen3-TTSが従来のOSS TTSモデルと一線を画すのは、以下の機能を標準でサポートしている点です。
- 安定した高品質音声生成:自然で聞き取りやすい音声を生成
- 感情表現(Expressive Speech):喜び・悲しみ・怒りなどの感情を込めた音声生成が可能
- ストリーミング出力:リアルタイムに音声を生成・再生できる
- ゼロショットボイスクローン:参照音声を与えるだけで、その声質を模倣した音声を生成
- 多言語対応:英語・中国語を中心に、日本語を含む多言語に対応
多くのプロジェクトで、社内向けの音声ガイダンスシステムを検討する際に、クラウドAPIの従量課金がネックになるケースがあります。
Qwen3-TTSのようなローカル実行可能なモデルがあれば、ランニングコストを抑えながら柔軟な音声生成が実現できます。
ローカルLLMの環境構築については、ローカルLLM環境構築ガイドも参考にしてください。
IT女子 アラ美動作環境と前提条件
Qwen3-TTSをローカルで動かすには、ある程度のGPUリソースが必要です。
以下の環境を想定して解説を進めます。
推奨環境
- OS:Ubuntu 22.04 LTS / Windows 11(WSL2推奨)
- GPU:NVIDIA RTX 3080以上(VRAM 10GB以上推奨)
- Python:3.10以上
- CUDA:12.1以上
- メモリ:32GB以上推奨
VRAMが8GB程度でも動作しますが、長文の音声生成やストリーミング出力時にメモリ不足になる可能性があります。
RTX 4090であれば24GBのVRAMがあるため、複数の音声を並列生成するようなユースケースにも対応できます。
CursorとOllamaを組み合わせた開発環境に興味がある方は、CursorでローカルLLMを使う完全ガイドも参考にしてください。
IT女子 アラ美WindowsでQwen3-TTSを動かす(WSL2セットアップ)
「qwen3 tts windows」で検索される方が多いので、Windows環境でのセットアップ手順を重点的に解説します。
Qwen3-TTSはLinux向けに開発されているため、WindowsではWSL2(Windows Subsystem for Linux 2)を経由して実行するのが最も安定した方法です。
Step 1:WSL2の有効化とUbuntuのインストール
PowerShellを管理者権限で開き、以下のコマンドを実行します。
# WSL2を有効化してUbuntuをインストール
wsl --install -d Ubuntu-22.04
# インストール後、再起動が必要な場合があります
再起動後、Ubuntuのターミナルが自動的に起動します。ユーザー名とパスワードを設定してください。
Step 2:WSL2でのCUDA環境構築
WSL2ではWindows側のNVIDIAドライバを共有するため、WSL内部にCUDA Toolkitだけをインストールすれば動作します。
# NVIDIA CUDA Toolkit for WSL2をインストール
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-1
# GPUが認識されているか確認
nvidia-smi
nvidia-smiでGPU情報が表示されれば、WSL2からGPUへの接続は成功です。
Step 3:Python環境の準備
WSL2のUbuntuにはPythonが含まれていますが、バージョン管理のためにpyenvの利用を推奨します。
# 必要なパッケージをインストール
sudo apt-get install -y build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev libffi-dev
# Python 3.10をインストール(pyenv不使用の場合)
sudo apt-get install -y python3.10 python3.10-venv python3-pip
ここまで完了したら、以降のインストール手順はLinuxと共通です。
IT女子 アラ美Qwen3-TTSのインストール手順
それでは、実際にQwen3-TTSをセットアップしていきましょう。
公式リポジトリをクローンし、必要な依存関係をインストールする流れです。
Step 1:リポジトリのクローン
まずはGitHubからリポジトリをクローンします。
# リポジトリをクローン
git clone https://github.com/QwenLM/Qwen3-TTS.git
cd Qwen3-TTS
# 仮想環境を作成(推奨)
python -m venv venv
source venv/bin/activate # Windowsの場合: venv\Scripts\activate
Step 2:依存関係のインストール
次に、必要なPythonパッケージをインストールします。
# 依存関係をインストール
pip install -r requirements.txt
# PyTorch(CUDA 12.1対応版)のインストール
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121
Step 3:モデルのダウンロード
Qwen3-TTSのモデルはHugging Face Hubから自動ダウンロードされますが、事前にダウンロードしておくこともできます。
from transformers import AutoModel, AutoTokenizer
# モデルとトークナイザーをダウンロード
model_name = "Qwen/Qwen3-TTS"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
Hugging Faceからモデルをダウンロードする手順は他のローカルAIツールでも共通です。詳細はOpen NotebookでローカルNotebookLMを構築するガイドも参考にしてください。
IT女子 アラ美基本的な音声生成と感情表現の実装
インストールが完了したら、実際に音声を生成してみましょう。
基本的なテキスト読み上げから、感情を込めた音声生成まで順を追って解説します。
基本的なテキスト読み上げ
最もシンプルな音声生成のコード例です。
import torch
from qwen3_tts import Qwen3TTS
# モデルの初期化
tts = Qwen3TTS(device="cuda")
# テキストから音声を生成
text = "こんにちは、Qwen3-TTSによる音声合成のデモです。"
audio = tts.synthesize(text, language="ja")
# WAVファイルとして保存
tts.save_audio(audio, "output.wav")
print("音声ファイルを保存しました: output.wav")
感情表現を付加した音声生成
Qwen3-TTSの強みである感情表現を活用してみましょう。
# 感情パラメータを指定して音声生成
emotions = ["happy", "sad", "angry", "neutral"]
for emotion in emotions:
audio = tts.synthesize(
text="本日はお越しいただきありがとうございます。",
language="ja",
emotion=emotion
)
tts.save_audio(audio, f"output_{emotion}.wav")
print(f"{emotion}の音声を保存しました")
社内向けのナレーション動画を制作する場合、従来はナレーターの手配や録音スタジオの確保に時間がかかるのが課題でした。
Qwen3-TTSであれば、原稿が確定した時点ですぐに音声を生成でき、修正対応も即座に行えます。
特に感情表現が使えることで、単調になりがちな説明動画にメリハリをつけられるのが実務上のメリットです。
AI動画生成ツールとの組み合わせについては、LTX-2でAI動画生成をローカルで動かすガイドも参考にしてください。
IT女子 アラ美実装後の効果検証(ケーススタディ)
IT女子 アラ美クラウドPCなら高性能GPU環境をいつでもどこからでも使えるのよ
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
山口さん(仮名・35歳・社内SE・経験8年)の事例を紹介します。
状況(Before)
- 社内向けeラーニング動画のナレーション作成に、外部ナレーターへの発注で1動画あたり3〜5営業日を要していた
- 原稿修正のたびに追加費用と再録音のリードタイムが発生
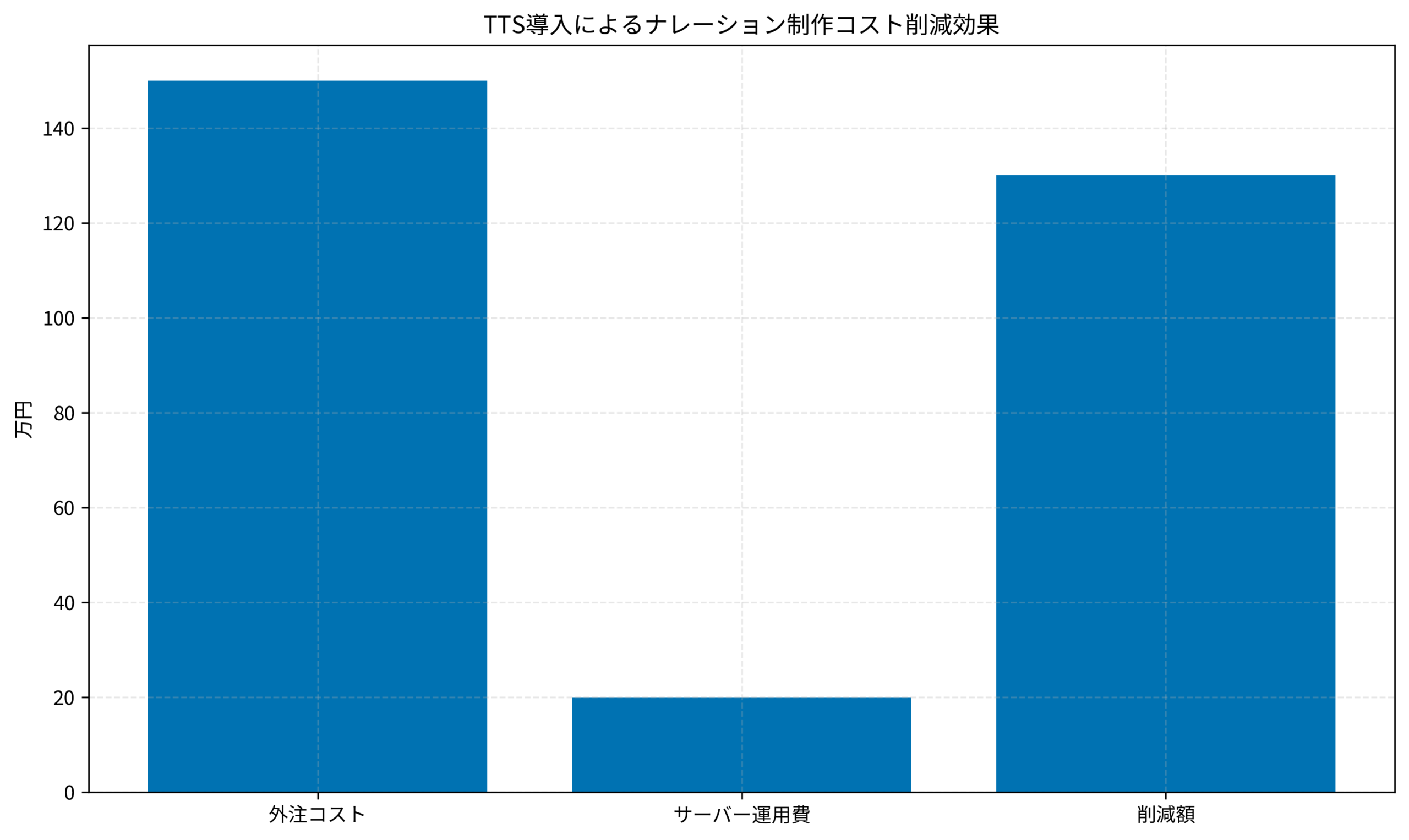
- 年間のナレーション制作費用が約150万円
行動(Action)
- Qwen3-TTSをオンプレミス環境(RTX 4090搭載サーバー)にデプロイ
- 社内の動画制作チームがセルフサービスで音声生成できるWebインターフェースを開発
- 原稿入力→感情選択→音声生成→ダウンロードのワークフローを構築
結果(After)
- ナレーション生成のリードタイムが3〜5営業日→数分に短縮(約99%削減)
- 年間のナレーション関連費用が約150万円→約20万円(サーバー運用費のみ)に削減
- 原稿修正時の追加コストがゼロに
- 動画制作チームの自律性が向上し、企画から公開までのサイクルが高速化
3Dキャラクターとの連携を検討する場合は、HY-Motionで3Dキャラクターアニメーションを生成するガイドも参考にしてください。
IT女子 アラ美さらなる実践・活用に向けて
Qwen3-TTSを導入した後は、以下のような発展的な活用も検討できます。
ボイスクローンの活用
ゼロショットボイスクローン機能を使えば、特定の話者の声質を模倣した音声を生成できます。
たとえば、会社の代表者の声で自動音声ガイダンスを作成したり、キャラクターボイスを一貫させたりといった用途が考えられます。
# ボイスクローンの例
reference_audio = "reference_speaker.wav" # 参照音声ファイル
audio = tts.synthesize(
text="この声は参照音声を元に生成されています。",
language="ja",
reference_audio=reference_audio
)
tts.save_audio(audio, "cloned_voice.wav")
ストリーミング出力でリアルタイム応答
チャットボットや対話システムと組み合わせる場合、ストリーミング出力が有効です。
テキスト生成と並行して音声を生成・再生することで、ユーザーの待ち時間を大幅に短縮できます。
今後の学習ステップ
- Hugging Face Transformersの基礎を学び、モデルのカスタマイズ方法を理解する
- 音声処理の基礎(サンプリングレート、ビット深度など)を押さえる
- FastAPIやGradioを使って、チーム向けのWebインターフェースを構築する
音声認識と組み合わせた対話システムの構築については、FunASRでローカル音声認識を動かすガイドも参考にしてください。こうしたAI・音声技術のスキルをフリーランス案件で活かしたい方はフリーランスエンジニア向けエージェント5社比較、AI導入をリードする社内SEのキャリアを目指す方は社内SE転職エージェント3社比較ガイド、年収アップを狙うならハイクラスエンジニア転職エージェント3社比較もご覧ください。
IT女子 アラ美よくある質問(FAQ)
Q. Qwen3-TTSはWindowsで直接動かせますか?
Qwen3-TTSはLinux向けに開発されているため、Windowsでの直接実行は推奨されていません。WSL2(Windows Subsystem for Linux 2)を経由してUbuntu環境で動かすのが最も安定した方法です。本記事のWSL2セットアップ手順を参考にしてください。
Q. 日本語の音声品質はどの程度ですか?
Qwen3-TTSは英語・中国語がメインの学習データですが、日本語にも対応しています。イントネーションに若干の不自然さが出る場合がありますが、社内向けナレーションや通知音声としては実用レベルです。
Q. 商用利用は可能ですか?
はい。Qwen3-TTSはApache 2.0ライセンスで公開されており、商用利用が可能です。ただしボイスクローン機能を使う場合は、参照音声の権利者から許諾を得る必要があります。
サーバー環境の選定や本番運用時のインフラ構成については、エンジニア向けXServer用途別比較ガイドも参考になります。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
本記事では、Qwen3-TTSをローカル環境にセットアップし、基本的な音声生成から感情表現・ボイスクローンまでの活用方法を解説しました。
- Qwen3-TTSはApache 2.0ライセンスで商用利用可能なオープンソースTTSモデル
- 感情表現・ストリーミング・ボイスクローンなど高度な機能を標準搭載
- RTX 3080以上のGPUがあれば、ローカル環境で快適に動作
- 社内向けナレーションやチャットボットの音声応答など、実務での活用シーンは幅広い
まずは基本的なテキスト読み上げから試してみて、感情表現やボイスクローンへとステップアップしていくのがおすすめです。
ローカル実行によるコスト削減と、即時生成による業務効率化の両方を実現できる強力なツールですので、ぜひ活用してみてください。
IT女子 アラ美








