 IT女子 アラ美
IT女子 アラ美OpenTinkerでFoundation Models向けRL環境を効率的に構築する方法を解説
24万社が導入!法人向けレンタルサーバー【XServerビジネス】
お疲れ様です!IT業界で働くアライグマです!
OpenTinkerは、Foundation Models(LLM・VLM)向けの強化学習基盤をサービスとして提供するオープンソースプロジェクトです。従来、LLMに強化学習を適用するには複雑なインフラ構築が必要でしたが、OpenTinkerを使えば、クライアント・サーバー分離のアーキテクチャで効率的にRLワークフローを実行できます。
「LLMのファインチューニングでRLを使いたいけど、環境構築が大変そう」「マルチターンの対話エージェントにRLを適用する方法がわからない」——こうした悩みを抱えているエンジニアは多いのではないでしょうか。AIエージェントプロジェクトでRL適用を検討する際、インフラ構築の複雑さが大きな壁となるケースは珍しくありません。
この記事では、OpenTinkerの基本概念から実際のセットアップ手順、LLM/VLMへの適用パターンまで、実践的な内容を解説します。
OpenTinkerの基本概念とアーキテクチャ
IT女子 アラ美クライアント・サーバー分離で計算リソースを最大限活用できる
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
OpenTinkerは「RL-as-a-Service」というコンセプトで設計されており、強化学習のトレーニングインフラをサービスとして提供します。従来のRLフレームワークと異なり、クライアント・サーバーを分離したアーキテクチャを採用しているため、計算リソースの効率的な配分が可能です。
クライアント・サーバー分離のメリット
OpenTinkerでは、クライアント(推論・インタラクション担当)とサーバー(トレーニング担当)を分離しています。これにより、以下のメリットが得られます。
- GPUリソースをトレーニングに集中させ、推論は軽量なクライアントで実行可能
- 複数のクライアントから同一のトレーニングサーバーを共有できるスケーラビリティ
- クライアント側のコード変更がサーバー側に影響しない疎結合な設計
対応するFoundation Modelsの種類
OpenTinkerは、LLM(大規模言語モデル)とVLM(視覚言語モデル)の両方に対応しています。具体的には、Qwen系モデルをベースとした実装例が公式に提供されており、wandbによるトレーニングログの可視化もサポートされています。
Foundation Modelsへの強化学習適用については、コンテキストエンジニアリング入門でも関連する設計パターンを解説しています。
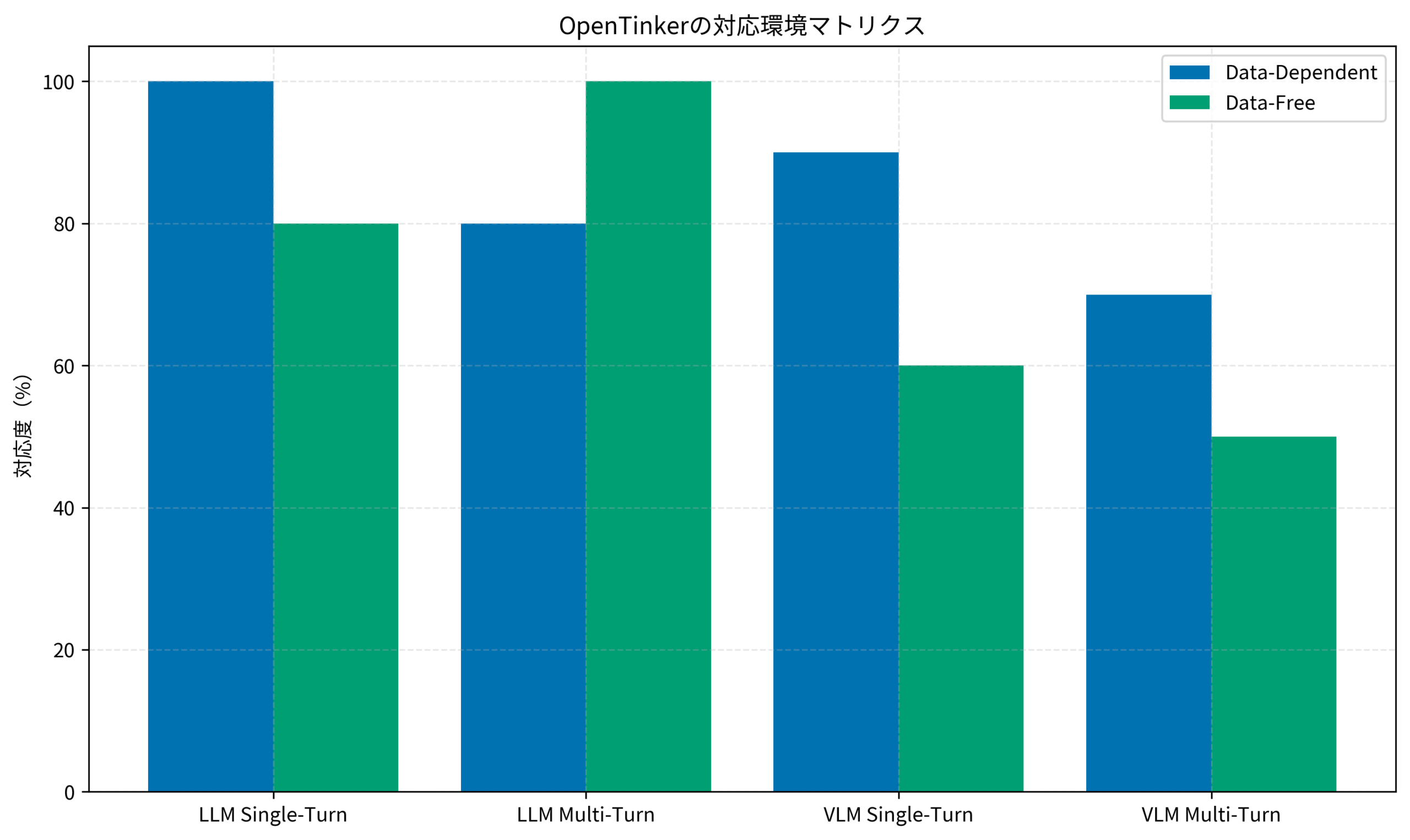
IT女子 アラ美環境設計のフレームワーク:4つのパラダイム
OpenTinkerの環境設計は、2つの軸で分類される4つのパラダイムをサポートしています。これを理解することで、自分のユースケースに最適な環境を選択できます。
Data Source軸:Data-Dependent vs Data-Free
Data-Dependent環境は、Parquetファイルなどの構造化データセットからプロンプトをロードします。例えば、数学の問題集や質問応答データセットを使ったトレーニングがこれに該当します。
一方、Data-Free環境は、シミュレーターやゲームエンジンからプロンプトを動的に生成します。五目並べやチェスなどのゲームAI訓練がこのパターンに該当します。
Interaction Mode軸:Single-Turn vs Multi-Turn
Single-Turnはモデルが一度だけ応答を返すケースで、数学の問題に対する解答生成などが典型例です。
Multi-Turnは、ツールコールやフィードバックループを含む反復的なインタラクションを扱います。AIエージェントが外部ツールを呼び出しながら複雑なタスクを解決するシナリオがこれに該当します。
AIエージェントの設計パターンについては、Anthropic SkillsとTool Useの違いも参考になります。
IT女子 アラ美ケーススタディ:LLM Math Single-Turnトレーニングの実装
IT女子 アラ美河野さん(仮名・31歳・MLエンジニア)のチームがOpenTinkerを使ってLLMの数学問題解答能力を強化学習で向上させた事例を紹介します。
状況(Before)
プロジェクトの初期段階では、Qwen2.5ベースのモデルを使用していましたが、複雑な数学問題に対する正答率が低い状態でした。
- モデル:Qwen2.5-7B-Instruct
- GPU:A100 80GB × 2
- 初期正答率:GSM8Kベンチマークで約45%
- 課題:推論ステップが不完全で、計算ミスが多い
行動(Action)
OpenTinkerを導入し、Math Single-Turn環境でPPO(Proximal Policy Optimization)を適用しました。
1ヶ月目は環境構築とデータ準備です。公式DockerイメージをベースにOpenTinkerをセットアップし、GSM8KとMATHデータセットをParquet形式に変換してData-Dependent環境を構築しました。具体的には、verlai/verl Dockerイメージを使用し、サーバー側のセットアップを完了させました。GPUリソースの配分を最適化し、A100 2枚でのトレーニング環境を整備しました。
2ヶ月目は報酬関数の設計と調整です。正答判定だけでなく、推論ステップの論理的整合性も報酬に反映させる設計を採用しました。wandbでトレーニングログを可視化しながら、ハイパーパラメータを調整しました。
3ヶ月目は本番適用とモニタリングです。トレーニング済みモデルを本番環境にデプロイし、実際のユースケースでの性能を検証しました。
結果(After)
3週間のトレーニング後、GSM8Kベンチマークでの正答率が大幅に向上しました。
- 正答率:45% → 72%(約27ポイント改善)
- 推論ステップの完全性:68% → 89%
- トレーニング期間:3週間(A100 × 2)
特に、複数ステップの計算問題での改善が顕著で、以前は途中で計算を放棄していたケースが大幅に減少しました。
LLMトレーニングの効率化については、lightronによる軽量Megatron実装も参考になります。
IT女子 アラ美セットアップ手順:DockerベースのQuick Start
OpenTinkerのセットアップは、DockerベースとManual Installationの2通りがあります。安定性と再現性の観点から、公式はDockerベースを推奨しています。
共通セットアップ(クライアント・サーバー共通)
まず、リポジトリをクローンし、OpenTinkerとverlをインストールします。
git clone --recurse-submodules https://github.com/open-tinker/OpenTinker.git
cd OpenTinker
pip install -e .
cd verl
pip install -e .
cd ..サーバーセットアップ(Dockerベース推奨)
サーバー側は、GPUを使用したトレーニングを担当するため、Dockerイメージの使用が推奨されます。
docker pull verlai/verl@sha256:3ce56ff018516b28ab9c4f4fc09d3aa67589074495ace75e2674b720aa4d0e5d
docker run -dit \
--gpus all \
--restart=no \
--entrypoint /bin/bash \
--net=host \
--shm-size=10g \
--cap-add=SYS_ADMIN \
-v .:/workspace/dev \
--name tinker \
verlai/verl@sha256:3ce56ff018516b28ab9c4f4fc09d3aa67589074495ace75e2674b720aa4d0e5d認証とスケジューラー設定
OpenTinkerにはユーザー認証機能があり、scheduler_users.dbでユーザー管理を行います。Webダッシュボードからトレーニングジョブのモニタリングが可能で、各ジョブのステータス、GPU使用率、損失曲線などをリアルタイムで確認できます。これにより、トレーニングの進捗を常に把握し、問題が発生した場合にも迅速に対応できます。
AIエージェントの本番運用については、Amazon Bedrock AgentCoreの実装ガイドも参照してください。
IT女子 アラ美よくある質問(FAQ)
Q. OpenTinkerを動かすにはどのくらいのGPUが必要ですか?
最低でもA100 40GB×1が必要です。7Bパラメータのモデルであればこの構成で動作しますが、より大きなモデルや効率的なトレーニングにはA100×2以上を推奨します。クラウドGPUサービスを利用すれば、初期投資なしで試すことができます。
Q. 強化学習のスキルはキャリアアップに有効ですか?
非常に有効です。LLMへのRL適用は最先端の技術であり、実装経験があるエンジニアは市場で高く評価されます。ハイクラスエンジニア転職エージェント3社比較で紹介しているエージェントに相談すると、AI/ML関連の高条件ポジションに出会いやすくなります。
Q. OpenTinkerはLLM以外のモデルにも使えますか?
はい、VLM(Vision-Language Model)にも対応しています。画像認識と言語理解を組み合わせたマルチモーダルモデルのRL適用も可能です。環境パラダイムはLLMと同じ4パターンをサポートしているため、VLMでも同様のワークフローで強化学習を適用できます。
IT女子 アラ美おすすめ学習リソース・サービス
強化学習やLLMファインチューニングのスキルを体系的に学びたい方には、以下のサービスがおすすめです。実践的なカリキュラムで効率よくスキルアップできます。
サーバー環境の選定や本番運用時のインフラ構成については、エンジニア向けXServer用途別比較ガイドも参考になります。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
OpenTinkerは、Foundation Models向けの強化学習基盤を民主化するオープンソースプロジェクトです。クライアント・サーバー分離のアーキテクチャにより、計算リソースを効率的に活用しながら、LLM・VLMへのRL適用を実現できます。
この記事で紹介したポイントをまとめると、OpenTinkerは4つの環境パラダイム(Data-Dependent/Data-Free × Single-Turn/Multi-Turn)をサポートしており、ユースケースに応じた柔軟な設計が可能です。Dockerベースのセットアップが推奨されており、verlをコアパッケージとして使用します。wandbとの統合により、トレーニングログの可視化とモニタリングが容易です。
強化学習をLLMに適用したいが環境構築のハードルが高いと感じているエンジニアにとって、OpenTinkerは有力な選択肢となるでしょう。まずは公式ドキュメントのQuick Startを試し、Math Single-Turnの例から始めてみることをおすすめします。Docker環境さえ用意できれば、数時間でトレーニングを開始できるため、RLを試したいがインフラ構築で挫折した経験があるエンジニアには特に価値があります。
IT女子 アラ美








