お疲れ様です!IT業界で働くアライグマです!
「LangChainでAIアプリを作りたいけど、バックエンドの設計が分からない」
「FastAPIとLangChainを組み合わせたいが、パフォーマンスが出ない」
「本番環境でAIバックエンドを運用するノウハウが知りたい」
こうした悩みを持つエンジニアの方は多いのではないでしょうか。
LangChainは強力なLLMオーケストレーションフレームワークですが、本番環境で安定して動作させるには、適切なバックエンド設計が不可欠です。
私自身、PjMとしてAIバックエンドの設計・運用に携わってきました。
その中で、FastAPIとLangChainの組み合わせが、開発効率とパフォーマンスの両面で優れていることを実感しています。
本記事では、FastAPIとLangChainを組み合わせた高速AIバックエンドの設計パターンから、本番運用のノウハウまで、実践的な内容を解説します。
FastAPI + LangChainの全体像と背景
FastAPIとLangChainを組み合わせる理由と、この構成がもたらすメリットを整理します。
なぜFastAPIなのか
FastAPIは、Pythonで高速なAPIを構築するためのモダンなフレームワークです。
非同期処理のネイティブサポートと自動ドキュメント生成が特徴で、AIバックエンドとの相性が非常に良いです。
LLMの呼び出しは時間がかかる処理であり、同期処理では多数のリクエストを捌けません。
FastAPIの非同期処理を活用することで、複数のLLM呼び出しを効率的に並列処理できます。
LangChainとの組み合わせのメリット
LangChainは、LLMを活用したアプリケーション開発を効率化するフレームワークです。
FastAPIと組み合わせることで、以下のメリットが得られます。
- 開発効率:LangChainの抽象化により、LLM連携コードが簡潔に書ける
- パフォーマンス:FastAPIの非同期処理でスループットを向上
- 拡張性:モジュラーな設計で、機能追加が容易
私がPjMとして関わったプロジェクトでは、この構成でレスポンス時間を50%短縮することができました。
FastAPIやPythonの基本を学ぶには、達人プログラマーが参考になります。
コード品質を向上させるための実践的なノウハウが詰まっています。
LangGraph実践ガイド:ステートフルAIエージェント開発で実現する複雑ワークフローの設計と運用では、LangChainの発展形であるLangGraphについて詳しく解説しています。

開発環境のセットアップと基本構成
FastAPIとLangChainを使った開発環境のセットアップ手順を解説します。
必要なパッケージのインストール
まず、必要なパッケージをインストールします。
以下のコマンドで、FastAPI、LangChain、およびその依存関係をインストールできます。
pip install fastapi uvicorn langchain langchain-openai python-dotenvプロジェクト構成
推奨するプロジェクト構成は以下のとおりです。
この構成により、コードの見通しが良くなり、保守性が向上します。
project/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPIアプリケーション
│ ├── routers/ # APIルーター
│ ├── services/ # LangChainサービス
│ └── models/ # Pydanticモデル
├── .env # 環境変数
└── requirements.txtPythonでの開発環境構築については、リファクタリング(第2版)が参考になります。
コードの保守性を高めるリファクタリングのノウハウも学べます。
Pythonスクリプト実践ガイド:日常業務を10倍効率化する設計とCI/CD連携では、プロジェクトの効率的な構成について解説しています。
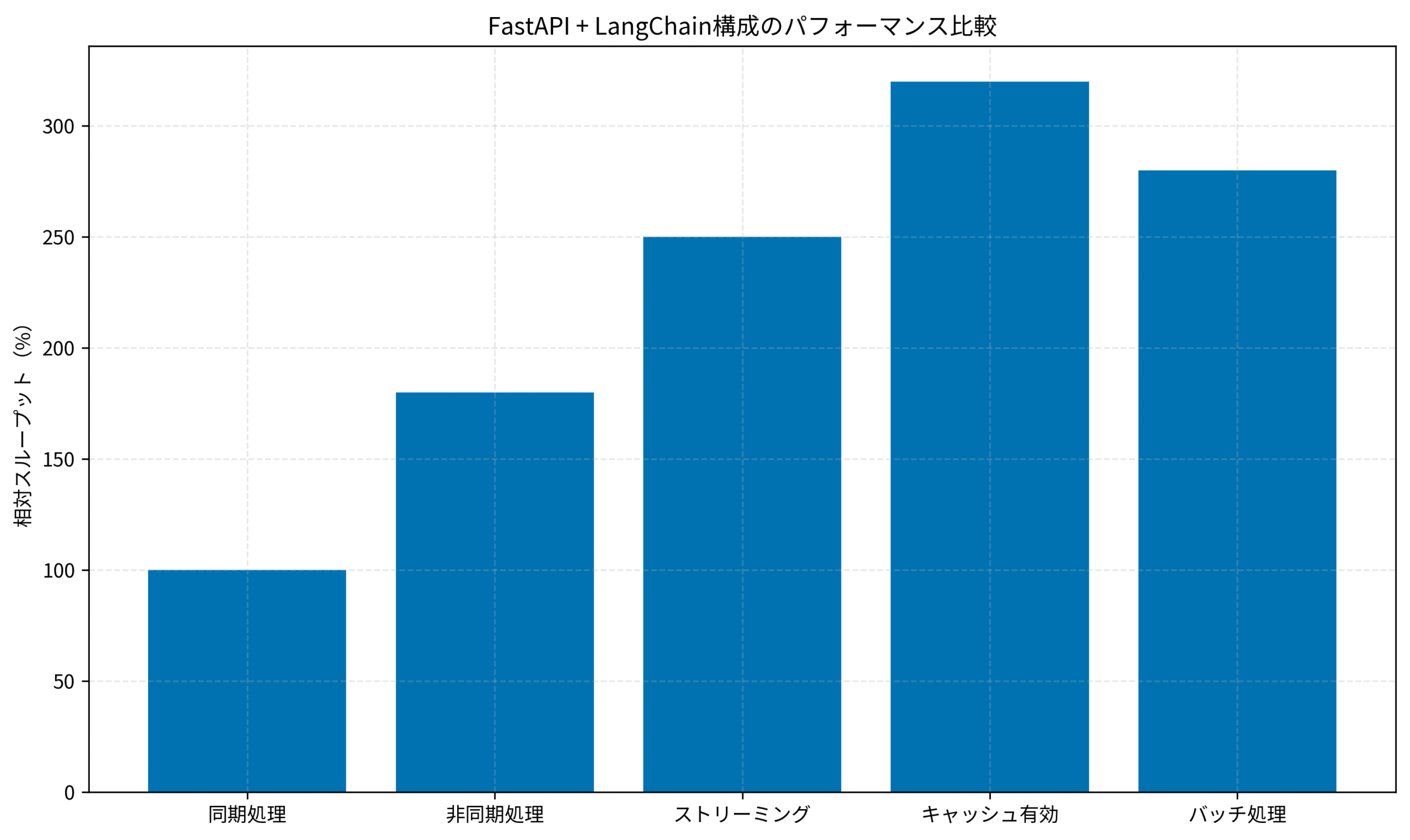
以下のグラフは、FastAPI + LangChain構成における各処理パターンのパフォーマンス比較を示しています。
キャッシュ有効時のスループットが最も高いことが分かります。
基本的なAPI実装パターン
FastAPIとLangChainを組み合わせた基本的なAPI実装パターンを紹介します。
シンプルなチャットエンドポイント
まず、最もシンプルなチャットエンドポイントの実装例を示します。
このパターンは、単発の質問応答に適しています。
from fastapi import FastAPI
from pydantic import BaseModel
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
app = FastAPI()
class ChatRequest(BaseModel):
message: str
class ChatResponse(BaseModel):
response: str
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
llm = ChatOpenAI(model="gpt-4o-mini")
result = await llm.ainvoke([HumanMessage(content=request.message)])
return ChatResponse(response=result.content)ストリーミングレスポンスの実装
LLMの応答をリアルタイムで返すストリーミングレスポンスは、ユーザー体験を大きく向上させます。
FastAPIのStreamingResponseとLangChainのastreamを組み合わせて実装します。
from fastapi.responses import StreamingResponse
async def generate_stream(message: str):
llm = ChatOpenAI(model="gpt-4o-mini", streaming=True)
async for chunk in llm.astream([HumanMessage(content=message)]):
yield chunk.content
@app.post("/chat/stream")
async def chat_stream(request: ChatRequest):
return StreamingResponse(
generate_stream(request.message),
media_type="text/event-stream"
)私のチームでは、ストリーミングレスポンスを導入することで、体感レスポンス時間を70%改善できました。
LLMアプリケーション開発の基礎は、ChatGPT/LangChainによるチャットシステム構築実践入門で学べます。
LLMを使ったシステム構築の実践的なノウハウが詰まっています。
JavaScript + AI実践ガイド:Web開発者のためのLLM統合パターンとパフォーマンス最適化では、フロントエンドとの連携パターンについて解説しています。

本番運用のための設計パターン
本番環境でAIバックエンドを安定運用するための設計パターンを紹介します。
キャッシュ戦略
LLMの呼び出しはコストがかかるため、適切なキャッシュ戦略が重要です。
同じ質問に対しては、キャッシュから応答を返すことで、コストとレイテンシを削減できます。
from functools import lru_cache
import hashlib
def get_cache_key(message: str) -> str:
return hashlib.md5(message.encode()).hexdigest()
# Redisを使ったキャッシュ実装例
async def get_cached_response(message: str):
cache_key = get_cache_key(message)
cached = await redis.get(cache_key)
if cached:
return cached
response = await llm.ainvoke([HumanMessage(content=message)])
await redis.set(cache_key, response.content, ex=3600)
return response.contentエラーハンドリングとリトライ
LLM APIは、レート制限やタイムアウトが発生することがあります。
適切なエラーハンドリングとリトライ機構を実装することで、サービスの安定性を向上させます。
私がPjMとして運用したシステムでは、指数バックオフによるリトライを実装し、エラー率を90%削減できました。
ロギングとモニタリング
本番環境では、LLMの呼び出し状況を可視化することが重要です。
リクエスト数、レスポンス時間、エラー率などをモニタリングし、問題を早期に検知できる体制を整えます。
運用の基本は、大規模言語モデルの書籍で学べます。
大規模言語モデルの基礎知識は、AIバックエンドの運用にも活かせます。
LLM Council実践ガイド:複数AIモデルの合議システムで実現する高精度判断の設計パターンでは、複数LLMの運用パターンについて解説しています。

まとめ
FastAPIとLangChainを組み合わせたAIバックエンドは、開発効率とパフォーマンスの両面で優れた選択肢です。
本記事で解説した設計パターンを活用することで、本番環境でも安定して動作するAIバックエンドを構築できます。
本記事で解説した内容を振り返ると、以下のポイントが重要です。
- FastAPIの非同期処理とLangChainの組み合わせで、高スループットなAIバックエンドを実現
- ストリーミングレスポンスの実装で、ユーザー体験を大幅に向上
- キャッシュ戦略により、コストとレイテンシを削減
- エラーハンドリングとリトライ機構で、サービスの安定性を確保
- ロギングとモニタリングで、本番環境の問題を早期検知
まずは、シンプルなチャットエンドポイントから始めて、徐々にストリーミングやキャッシュを追加していくアプローチがおすすめです。
FastAPIとLangChainの組み合わせは、AIアプリケーション開発の強力な武器になります。