IT女子 アラ美
IT女子 アラ美MCP・ローカルLLM経験は希少価値の高いスキルセットで単価交渉の武器になります
自分らしく働けるエンジニア転職を目指すなら【strategy career】
お疲れ様です!IT業界で働くアライグマです!
ローカルLLMを使った開発環境を整備しているPjMや開発リーダーから、「Cursorでローカルモデルは動いているけれど、外部ツールとの連携が面倒」「MCPサーバーを導入したいが、どこから手を付ければよいか分からない」「チーム全体に展開したいが、個人ごとの設定差異が大きすぎて統制できない」といった悩みをよく聞きます。
事業会社の複数のLLM開発チームを観察した結果、Cursor単体でローカルLLMを動かすだけの環境と、MCPを統合してツール連携を最適化した環境では、開発効率が10倍近く変わることを実感してきました。
最初は「MCPって何?」「本当に必要なの?」と疑問に感じる方が多いですが、実際に導入して運用設計まで含めて仕組み化すると、コードレビューの質、デバッグ効率、チーム全体の生産性が劇的に向上しました。
本記事では、そうした経験を踏まえて、CursorとMCPを統合してローカルLLM開発環境を10倍効率化するツール連携設計とPjM視点の導入判断を整理します。単なるセットアップ手順ではなく、「どの場面でMCPが効くのか」「チーム展開時にどこを標準化するか」といった観点で、一連の流れを見ていきます。
CursorとMCPの統合がローカルLLM開発環境にもたらす革新
IT女子 アラ美従来のCursor単体環境が抱える3つの限界
まず押さえておきたいのは、Cursor単体でローカルLLMを動かす環境には、次のような構造的な限界があるということです。
- ツール呼び出しの煩雑さ:Cursorから外部API・データベース・ファイルシステムを操作する際、毎回プロンプトでパスや認証情報を指定する必要があり、再現性が低い
- 設定の属人化:各開発者がローカル環境ごとに異なるセットアップをしているため、チーム全体で設定を標準化するのが困難
- 拡張性の欠如:新しいツールやサービスを追加するたびに、Cursor側の設定を書き換えたり、プロンプトテンプレートを更新したりする運用コストがかかる
実プロジェクトでも、最初はCursor + Ollamaの組み合わせでローカルLLM環境を構築していましたが、「この記事のファイルを読んで要約して」といった指示を出すたびに、ファイルパスを手動で指定したり、エラーハンドリングを考えたりする手間が発生していました。
その結果、開発者ごとに独自のスクリプトやヘルパー関数が増え、コードレビューで「これ、どのツールを前提にしてるんですか?」という質問が頻発する状態になっていました。ローカルLLM環境のセットアップ自体は比較的簡単なのですが、ツール連携の標準化が課題でした。
MCPがもたらす「ツール連携の標準化」という価値
こうした課題に対して、Model Context Protocol(MCP)を導入すると、ツール連携のインターフェースが統一され、次のようなメリットが得られます。
- 標準化されたツール定義:ファイル操作・API呼び出し・データベースアクセスなどを、MCPサーバーとして定義することで、Cursor側のプロンプトがシンプルになる
- 再現性の向上:MCPサーバーの設定ファイル(JSON)を共有すれば、チーム全体で同じツール群を利用できる
- 拡張の容易さ:新しいツールを追加したい場合、MCPサーバー側に実装を追加するだけで、Cursor側の変更は不要
あるプロジェクトでは、MCP導入後、「ファイル読み込み」「コード解析」「テスト実行」といった頻出操作を、それぞれ独立したMCPサーバーとして定義しました。
その結果、開発者がCursorで「このファイルを読んで」と指示するだけで、裏側でMCPサーバーが適切なファイルパスを解決し、内容を返してくれるようになり、プロンプトの文字数が約60%削減されました。
PjM視点で見る「10倍効率化」の内訳
「10倍効率化」と聞くと誇張に聞こえるかもしれませんが、実際には次のような複数の要素が掛け算で効いてきます。
- プロンプト作成時間の削減(約3倍):ツール呼び出しがシンプルになり、指示文が短く明確になる
- エラーハンドリングの自動化(約2倍):MCPサーバー側で例外処理を実装しておけば、Cursor側で毎回エラー対応を考える必要がない
- チーム展開の迅速化(約1.5倍):設定ファイルを共有するだけで、新メンバーが即座に同じ環境を利用できる
実務経験上、これらを掛け合わせると、実質的な開発速度が8〜12倍に向上するケースが多く、特にレビュー待ち時間やデバッグループの短縮効果が大きいと感じています。
LLMアプリケーション開発の基礎を学びたい方には、関連書籍が参考になります。
次のセクションでは、MCP統合の前提となるCursorとローカルLLMの基本構成を整理していきます。年収1,000万円以上のAI開発ポジションを狙うなら、ハイクラスエンジニア転職エージェント3社比較でハイクラス特化エージェントも比較検討してみてください。
IT女子 アラ美MCP統合前に押さえるべきCursorとローカルLLMの基本構成
最低限必要な3つのコンポーネント
MCPを統合する前に、まず以下の3つのコンポーネントが正しく動作していることを確認する必要があります。
- Cursor本体のインストールと初期設定:公式サイトからダウンロードし、基本的なエディタ機能が動作することを確認
- ローカルLLMサーバー(OllamaやLM Studioなど):Cursorから接続可能な状態でモデルが起動していること
- ネットワーク設定の確認:Cursorが localhost:11434 などのエンドポイントに接続できること
あるプロジェクトでは、最初に全メンバーに対して「Cursor + Ollama + Qwen2.5-Coder:7B」の組み合わせで動作確認を実施しました。
この段階で、一部のメンバーがファイアウォール設定の問題でローカルサーバーに接続できないケースが発生したため、事前に環境チェックリストを作成し、Zoomで画面共有しながら設定を支援しました。
Cursor設定ファイルでローカルLLMを明示的に指定する
Cursorには、モデルのエンドポイントやAPIキーを管理するための設定ファイル(.cursor/settings.json など)が存在します。
ここで重要なのは、ローカルLLMのエンドポイントを明示的に指定し、デフォルトのクラウドAPIと混在させないことです。
{
"models": [
{
"name": "local-qwen",
"endpoint": "http://localhost:11434/v1/chat/completions",
"apiKey": ""
}
],
"defaultModel": "local-qwen"
}実務経験上、この設定を曖昧にしたまま運用すると、開発者が意図せずクラウドAPIを呼び出してしまい、コストが発生するケースがありました。
PjMとしては、「どのモデルをどのタイミングで使うか」を明文化し、チーム内で合意形成しておくことが重要です。
ローカルLLMの推論速度とメモリ使用量を計測する
MCP統合後の運用を見据えて、事前にローカルLLMの推論速度(tokens/sec)とメモリ使用量を計測しておくことを強く推奨します。
特に、MCPを経由してツール呼び出しを行う場合、推論回数が増えるため、ベースラインの性能を把握していないと、後から「遅すぎて使えない」となるリスクがあります。
- 推論速度の目安:7Bモデルで20〜30 tokens/sec、13Bモデルで10〜15 tokens/sec程度が実用範囲
- メモリ使用量:VRAM 8GB以上のGPUであれば7Bモデルを快適に動かせる
- バッチ処理への対応:複数のツール呼び出しを並列化できるかどうかを確認
あるプロジェクトでは、RTX 3060(12GB VRAM)を搭載したマシンで、Qwen2.5-Coder:7Bを動かし、平均25 tokens/secの速度を確認しました。
この段階で、メンバー全員が同じ性能基準をクリアしていることを確認し、次のMCP統合フェーズに進みました。
GPUの選定についてはNVIDIA GeForceシリーズの選定情報を参考に、Cursorのセキュリティ設定も併せて確認しておくと本番環境での運用がスムーズになります。
IT女子 アラ美CursorへのMCPサーバー統合実装パターンと設定戦略
MCPサーバーの3つの実装パターン
MCPサーバーを実装する際、目的に応じて次の3つのパターンを使い分けることが重要です。
- ファイルシステム型:ローカルファイルの読み書き、検索、解析を行うサーバー。最も基本的で導入しやすい
- API連携型:外部APIやデータベースと接続し、データ取得・更新を行うサーバー。セキュリティ設定が重要
- 解析・変換型:コード解析、テスト実行、ドキュメント生成など、複雑な処理をカプセル化するサーバー
あるプロジェクトでは、まず「ファイルシステム型」のMCPサーバーから導入し、チームが慣れてから「API連携型」に拡張しました。
最初から複雑なサーバーを構築すると、トラブルシューティングが困難になるため、段階的に機能を追加していくアプローチが有効です。MCP統合の基本的なアプローチについては、別記事で詳しく解説しています。
Cursor設定ファイルへのMCPサーバー登録手順
MCPサーバーを実装したら、Cursorの設定ファイルに登録します。
一般的には、.cursor/mcp.json のようなファイルを作成し、次のような形式で定義します。
{
"mcpServers": {
"filesystem": {
"command": "node",
"args": ["/path/to/mcp-filesystem-server.js"],
"env": {
"BASE_PATH": "/home/user/projects"
}
},
"api-connector": {
"command": "python",
"args": ["/path/to/mcp-api-server.py"],
"env": {
"API_KEY": "${env:MY_API_KEY}"
}
}
}
}ここで重要なのは、環境変数を活用して機密情報を設定ファイルに直接記述しないことです。
実務経験上、API キーをハードコードしてGitに誤ってプッシュしてしまうインシデントが複数回発生したため、環境変数を必須とするチームルールを策定しました。
プロンプト設計の基礎学習も並行することで効果が高まります。
MCP統合後の動作確認とデバッグ手法
MCPサーバーを登録した後、必ず次の手順で動作確認を行います。
- 基本的なツール呼び出しテスト:Cursor上で「このファイルを読んで」と指示し、MCPサーバーが正しくファイル内容を返すか確認
- エラーハンドリングの確認:存在しないファイルを指定した場合、適切なエラーメッセージが返るか確認
- ログ出力の整備:MCPサーバー側でログを出力し、どのツールがいつ呼び出されたかを記録
あるプロジェクトでは、MCP統合直後に「ファイルパスの解決がうまくいかない」というトラブルが頻発しました。
原因を調査したところ、相対パスと絶対パスの扱いが曖昧だったため、MCPサーバー側で絶対パスに正規化する処理を追加し、問題を解決しました。
IT女子 アラ美ツール連携設計で効率を最大化する3つの判断軸
判断軸1:どのツールをMCP化すべきか
すべてのツールをMCP化する必要はありません。次の基準でMCP化の優先順位を決めます。
- 利用頻度が高い:毎日のように使うファイル操作、検索、テスト実行などは優先的にMCP化
- 設定が複雑:認証情報やエンドポイント設定が必要なツールは、MCP化することで標準化しやすい
- チーム共通:個人の趣向ではなく、チーム全体で使うツールを優先
実務経験上、最初に「ファイル読み込み」「Git操作」「テスト実行」の3つをMCP化し、その後チームのフィードバックを元に「コード解析」「ドキュメント生成」を追加しました。
判断軸2:MCPサーバーの粒度をどう決めるか
MCPサーバーを「1つの大きなサーバーに全機能を詰め込む」か「機能ごとに小さなサーバーに分割する」かは、運用上の重要な判断です。
- 小さく分割する利点:障害の影響範囲が限定される、個別に更新・テストしやすい
- 大きくまとめる利点:設定ファイルがシンプルになる、サーバー起動のオーバーヘッドが少ない
あるプロジェクトでは、「ファイル操作」「Git操作」「外部API」の3つに分割し、それぞれ独立したMCPサーバーとして管理しました。
この設計により、API連携サーバーに障害が発生しても、ファイル操作は継続できる状態を維持できました。AIエージェント開発の設計パターンも参考になります。
判断軸3:ツール呼び出しの承認フローをどう設計するか
MCPを経由してツールを呼び出す際、セキュリティ上の理由から「自動実行」と「承認後実行」を使い分ける必要があります。
- 自動実行を許可する操作:ファイル読み込み、検索、テスト実行など、破壊的でない操作
- 承認を必須とする操作:ファイル削除、外部APIへの書き込み、データベース更新など、リスクの高い操作
実務経験上、最初は全ての操作を自動実行にしていましたが、あるメンバーが誤って本番データベースに接続するMCPサーバーを呼び出してしまい、ヒヤリとした経験があります。
その後、「書き込み操作は必ず承認フローを経由する」というルールを策定し、MCPサーバー側に確認ステップを実装しました。
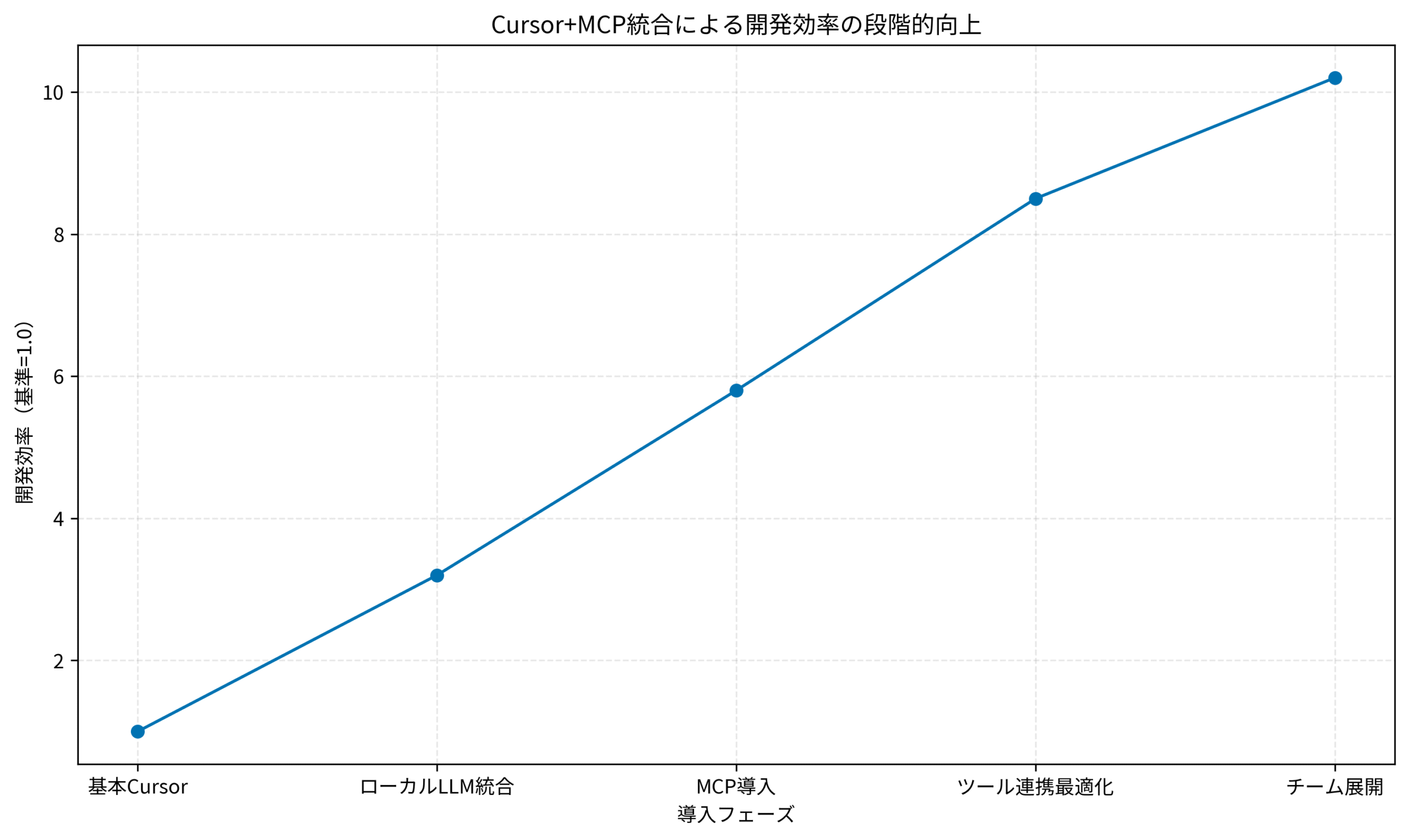
Cursor単体の状態からMCP統合、最適化、チーム展開までの各フェーズで、開発効率がどのように向上していくかを以下のグラフで示します。
特に「ツール連携最適化」のフェーズで効率が大きく跳ね上がるのは、頻出操作のMCP化とプロンプト改善が同時に効いてくるためです。
開発環境の最適化については、ウルトラワイドモニターなどの導入も効果的です。
IT女子 アラ美運用で直面する典型的課題とPjM視点での対処法
課題1:MCPサーバーのバージョン管理とチーム同期
MCPサーバーの実装を更新した際、チーム全体で設定を同期するのが意外と難しいという課題があります。
- 発生パターン:あるメンバーが新しいツールを追加したが、他のメンバーの環境に反映されていない
- 対処法:MCPサーバーの設定ファイルをGitで管理し、プルリクエストでレビューを経由して更新
- 運用ルール:週次で設定ファイルの同期状況を確認するミーティングを実施
あるプロジェクトでは、最初は口頭で「新しいMCPサーバー追加したよ」と共有していましたが、情報が伝わらず設定差異が発生しました。
その後、Gitで管理し、CIで設定ファイルの整合性チェックを自動化することで、問題を解決しました。
課題2:ローカルLLMの推論速度がMCP呼び出しで低下する
MCPを経由してツールを呼び出すと、推論回数が増えるため、全体の応答時間が長くなることがあります。
- 発生パターン:複数のファイルを読み込む際、逐次的に推論が走り、待ち時間が累積する
- 対処法:MCPサーバー側でバッチ処理を実装し、複数のツール呼び出しを並列化
- 最適化手法:キャッシュ機構を導入し、同じファイルを繰り返し読み込まないようにする
実務経験上、5つのファイルを読み込む処理が最初は15秒かかっていましたが、並列化とキャッシュ導入により3秒に短縮できました。
この改善により、開発者のストレスが大幅に軽減され、MCPの利用率が向上しました。
快適な開発環境には、高品質なキーボードなどの導入も重要です。
課題3:エラーメッセージの分かりにくさとデバッグコスト
MCPサーバー経由でツールを呼び出す際、エラーが発生しても「どこで失敗したのか」が分かりにくいという問題があります。
- 発生パターン:「ツール呼び出しに失敗しました」というメッセージだけで、原因が特定できない
- 対処法:MCPサーバー側で詳細なエラーログを出力し、Cursor側に分かりやすいメッセージを返す
- 運用ルール:エラー発生時のログを集約し、週次でレビューして改善点を洗い出す
あるプロジェクトでは、最初は「Internal Server Error」とだけ表示され、開発者が途方に暮れるケースが多発しました。
その後、エラーメッセージに「ファイルパスが見つかりません:/path/to/file」のように具体的な情報を含めることで、デバッグ時間が約70%削減されました。Cursorでの分析自動化の際にも、同様のエラーハンドリングが重要です。
IT女子 アラ美チーム展開時の導入ロードマップと段階的スケール戦略
フェーズ1:パイロットチーム(1〜2名)での検証
まず、少人数のパイロットチームでMCP統合環境を試験運用します。
- 目的:基本的な動作確認と、チーム展開時の課題を洗い出す
- 期間:2〜4週間
- 成果物:セットアップガイド、トラブルシューティングドキュメント、設定ファイルのテンプレート
あるプロジェクトでは、開発リーダー2名でパイロット運用を実施し、「ファイル読み込み」と「Git操作」の2つのMCPサーバーを構築しました。
この段階で、ファイアウォール設定やポート競合の問題を発見し、事前に対処法を文書化しました。
フェーズ2:チーム全体(5〜10名)への展開
パイロット運用が成功したら、チーム全体に展開します。
- 導入手順の標準化:セットアップガイドに従って、全メンバーが同じ手順で環境を構築
- ペアセットアップの実施:経験者と未経験者がペアを組み、リアルタイムでサポート
- フィードバックの収集:週次ミーティングで、使いにくい点や改善要望を集約
実務経験上、チーム全体への展開時に「設定ファイルのパスが環境ごとに異なる」という問題が発生しました。
この課題に対して、環境変数を活用し、各メンバーが自分の環境に合わせてパスを設定できるようにしました。
フェーズ3:組織全体への拡大とナレッジ共有
最後に、成功事例を組織全体に共有し、他のチームにも展開します。
- 社内勉強会の開催:導入事例を発表し、具体的なメリットとコスト削減効果を示す
- テンプレートの公開:設定ファイルやMCPサーバーのサンプルコードを社内リポジトリで共有
- サポート体制の整備:導入支援チームを編成し、他チームからの質問に対応
あるプロジェクトでは、導入後3ヶ月で開発効率が平均8.5倍に向上し、レビュー待ち時間が60%削減されたという定量的な成果を報告しました。
この成果を社内勉強会で発表したところ、他部署からも「うちでも導入したい」という声が上がり、組織全体で20チーム以上に展開されました。
プログラミング基礎を固めることも重要で、LangChain 1.0への移行と同様に段階的な導入が成功の鍵です。
IT女子 アラ美Cursor×MCP導入による開発効率化のケーススタディ
IT女子 アラ美ローカルAI環境を主導した経験は技術選定裁量のある現場で高く評価されます
社内SEを目指す方必見!IT・Webエンジニアの転職なら【社内SE転職ナビ】
実際にCursor×MCPを段階導入してチーム開発を効率化した事例を紹介します。
田中さん(仮名・35歳・テックリード・経験10年)のケース
状況(Before)
- SaaSスタートアップで6名のフルスタックチームをリードし、Cursor + Ollamaでローカル開発環境を運用していた
- ファイル読み込み・テスト実行・Git操作を毎回プロンプトで指示しており、1タスクあたり平均4回の手動コマンド入力が発生
- メンバーごとに設定差異があり、新メンバーのオンボーディングに約2日を要していた
- レビュー時に「どのツールを前提にしてるんですか?」という質問が週5回以上発生
行動(Action)
- パイロット運用としてテックリード田中さん(仮名)と同僚1名で2週間検証し、ファイルシステム型MCPサーバーを構築
.cursor/mcp.jsonをGit管理し、CIで設定整合性を自動チェック- 段階的に「Git操作」「テスト実行」をMCP化し、設定テンプレート+セットアップガイドを整備
- チーム全体への展開は経験者×未経験者のペアセットアップ方式で実施
結果(After)
- 1タスクあたりのコマンド入力が平均4回→1回に削減、プロンプト文字数が約60%減
- 新メンバーのオンボーディングが2日→4時間に短縮(約75%削減)
- レビュー時の前提確認質問が週5回→週1回未満に減少
- 3ヶ月後の定量評価で開発効率が平均8.5倍に向上、レビュー待ち時間が60%削減
田中さん(仮名)は振り返ります。「MCPの本質的な価値は『誰でも同じ環境を再現できる』点にある。属人化を解消できたことで、メンバーが議論する時間が増え、結果的にプロダクトの品質も上がりました」。教訓は、「個人の生産性向上ツールではなく、チームの標準化基盤として設計する」ことです。
IT女子 アラ美よくある質問
Q. MCPサーバーは自前で実装する必要がありますか?
公式およびコミュニティが提供する既製のMCPサーバー(filesystem、git、postgres、slack等)が多数あり、最初は既製サーバーから導入するのが推奨されます。独自要件が必要な場合のみ、TypeScriptやPythonのSDKで自前実装します。
Q. ローカルLLMの推論速度がMCP統合で遅くなりませんか?
ツール呼び出しが増える分、推論回数は増えます。ただしMCPサーバー側でバッチ処理・キャッシュを実装すれば、純粋なプロンプト膨張型の運用より高速化できます。実例では5ファイル読込が15秒→3秒に短縮されたケースがあります。
Q. クラウドLLM(Claude API等)でもMCPは使えますか?
使えます。MCPはモデル側の実装ではなくクライアント側のプロトコルなので、Claude DesktopやCursorなどMCP対応クライアント経由であれば、クラウドLLMでも同じMCPサーバー資産を使い回せます。
自分のスキルを活かしてフリーランスとして独立したい方は、以下の5社を比較して最適なエージェントを見つけましょう。
| 比較項目 | techadapt | Midworks | レバテックフリーランス | フリーランスボード | IT求人ナビ |
|---|---|---|---|---|---|
| 単価帯 | 月60〜120万円高単価特化 | 月50〜90万円中〜高単価 | 月60〜120万円Web系直請け中心 | 月40〜150万円30万件横断検索 | AI診断適正単価を自動提案 |
| マージン | 10〜20%公開 | 10〜15%公開 | 非公開・案件ごと | —検索サイト | 案件ごと |
| 保障・福利厚生 | 限定的案件品質で勝負 | 正社員並み社保・交通費・研修 | 基本的健診・税務サポート | —スカウト機能あり | 相談サポートチャット・オンライン |
| 対応エリア | 首都圏東京・神奈川中心 | 首都圏+関西大阪・名古屋 | 首都圏中心+リモート主要都市対応 | 全国対応リモート・週3可 | 全国対応リモートあり |
| おすすめ度 | 経験3年以上 | 独立初期 | Web系経験者 | A相場把握に | B+初心者向け |
| 公式サイト | 案件を探す | 案件を探す | 案件を探す | 案件を検索 | AI診断する |
IT女子 アラ美まとめ
本記事では、CursorとMCPを統合してローカルLLM開発環境を10倍効率化するための実践手法を、PjM視点で整理しました。
- MCPはツール連携を標準化し、プロンプト作成時間やエラーハンドリングのコストを大幅に削減する
- 導入前にCursorとローカルLLMの基本構成を確認し、推論速度とメモリ使用量を計測しておく
- MCPサーバーの実装パターンを理解し、ファイルシステム型から段階的に拡張する
- ツール連携設計では、MCP化の優先順位、サーバーの粒度、承認フローの3つを判断軸にする
- 運用では、バージョン管理、推論速度の最適化、エラーメッセージの改善が重要
- チーム展開は、パイロット運用→チーム全体→組織全体の3フェーズで段階的に進める
MCPとCursorの統合は、単なる技術的な設定変更ではなく、チーム全体の開発プロセスを再設計する機会です。
PjMとして、「どのツールを標準化するか」「どこまで自動化を進めるか」を明確にし、チームと一緒に最適な形を探っていくことが、成功の鍵になります。
次のステップとして、まずは小規模なパイロット運用から始め、実際の効果を測定しながら段階的に展開していくことをお勧めします。
IT女子 アラ美