お疲れ様です!IT業界で働くアライグマです!
ここ1〜2年で、MCP(Model Context Protocol)やツールコール対応のLLM基盤が一気に増え、開発チームの現場でも「LLMから外部ツールや社内APIをどう安全に呼び出すか」が日常的なテーマになりました。
一方で、現場のPjMやTech Leadの立場から見ると、次のようなモヤモヤをよく耳にします。
「強いエージェント基盤を作りたいけれど、ツールコールの責務分担や失敗時のふるまいが属人化していて怖い」
「MCPやCode Executionのデモは理解できるが、自社システムにどう組み込めばセキュアに運用できるのかイメージしづらい」
「PoCでは便利だったのに、本番運用を考えると監査ログやロールバック設計で手が止まってしまう」
私自身、事業会社のPjMとしてLLMエージェント基盤の刷新プロジェクトを複数担当し、「従来のツールコール設計」から「Code Execution with MCPを前提にした設計」に切り替える過程をチームと一緒に経験してきました。最初は私も「ツールを直接叩くか、MCP経由にするか」の議論から抜け出せずにいましたが、アーキテクチャと運用設計の前提を整理すると、一気に判断がしやすくなりました。
本記事では、こうした経験を踏まえて、Code Execution with MCPを前提にしたLLM開発チームのツール連携設計と、安全な実行基盤の組み立て方を整理します。単なるAPI仕様の紹介ではなく、「PjMとしてどこをレビューし、どのようにリスクをコントロールするか」という視点を中心に解説していきます。
Code Execution with MCPとは何か:LLMツール連携の前提がどう変わるのか
従来のツールコール設計が抱えていた3つの限界
Code Execution with MCPを理解するうえで、まずは従来のツールコール設計がどこで限界にぶつかっていたかを整理しておくことが大切です。
私が関わった案件でも、LLMが外部APIや社内システムを呼び出す仕組みは、最初は次のような構成になっていました。
- アプリケーションコード側で「どのツールをどの順番で呼ぶか」をハードコードしている
- LLMは「説明文の生成」だけを担当し、ツールの実行ロジックは人間が手で組み込んでいる
- ツール呼び出しの失敗時ふるまいやリトライ戦略が、プロジェクトごとにバラバラ
この状態だと、エージェントの振る舞いを変えたいたびにアプリケーション側のコードを修正する必要があり、PjMとしても「どこまでをLLMの責任にしてよいか」が非常に分かりづらくなります。障害調査のたびに「このリクエストはどのツールをどの順番で呼んだのか」をログから追いかける必要があり、運用コストも高止まりしていました。
Code Execution with MCPがもたらす設計上のメリット
Anthropicが提案しているCode Execution with MCPの考え方を採用すると、設計の前提が次のように変わります。
- LLMが「コード」を生成し、そのコードの中からMCP経由でツールを呼び出す
- ツールはMCPサーバ側で一元的に定義され、権限やスコープを明示的に管理できる
- ツール呼び出しのシーケンスや分岐ロジックをコードとして残せるため、レビューと再現性が高まる
特にPjM視点で大きいのは、「エージェントが何をどの順番で実行するのか」を、自然言語プロンプトだけでなくコードレベルでもレビューできるようになる点です。これにより、従来は属人的だったツール連携フローを、テスト可能なユースケースとして扱えるようになります。
PjMとして体感した「レビュー観点」が変わる瞬間
実務では、Code Execution with MCPを導入したタイミングで、私のレビュー観点も大きく変わりました。それまでは、
- このエージェントはどのAPIをどの順番で呼びそうか
- 障害が起きたときに、どのレイヤーから調査を始めればよいか
といった抽象的な質問に終始していましたが、Code Execution with MCP導入後は、
- どのツールをMCPとして外出しし、どこまでをアプリケーション側の責務に残すか
- ツール呼び出しコードのどこにガードレール(バリデーションやタイムアウト)が入っているか
- 失敗ケースをどの程度テストコードや検証シナリオでカバーできているか
といった、より具体的なチェックリストを持てるようになりました。
この変化によって、「LLM任せでブラックボックスになりがちだったエージェント挙動」が、チーム全体でレビュー・改善しやすい対象に変わっていきます。以降のセクションでは、この前提を踏まえて、具体的なアーキテクチャパターンや運用設計の進め方を掘り下げていきます。
LLMエージェント全体の設計方針については、AIエージェント開発の実践ガイド:自律型タスク処理で業務効率を3倍にする設計手法で整理している考え方が土台になります。ChatGPT/LangChainによるチャットシステム構築実践入門を手元に置きながら、「どのレイヤーまでをエージェントに任せるか」「どこから先を従来のアプリケーションコードに戻すか」をチームで言語化しておくと、Code Execution with MCP導入後の議論がスムーズになります。

Code Execution with MCPを組み込むアーキテクチャパターン
バックエンド・エージェント・MCPの三層構造で考える
Code Execution with MCPを前提にするとき、最初に決めるべきなのは「どのレイヤーが何を担当するか」です。
私がPjMとしてレビューしたプロジェクトでは、次のような三層構造に整理しました。
- バックエンド層:ビジネスルールと永続化、監査ログの管理
- エージェント層:ユーザーの自然文要求を分解し、どのツールをどの順番で呼ぶかを決定
- MCPサーバ層:外部API・バッチ・社内サービスへの安全なゲートウェイ
この三層を分けておくことで、「LLMが直接DBを書き換えてしまう」といった危険な構成を避けつつ、エージェント側の柔軟性を確保できます。国交省MCPサーバのような公共系ツールを扱う場合も、国交省MCPサーバ実務活用ガイド:対話APIで地理データを安全に引き出す開発パターンで紹介した考え方を応用し、「どのデータを誰が見るか」を明確に線引きすることが重要です。ソフトウェアアーキテクチャの基礎のようなアーキテクチャ本を参照しながら、システム全体の責務分担を図に落としていくと、関係者間の合意形成が進みやすくなります。
既存システムとの共存パターンをあらかじめ決めておく
次に重要になるのが、「既存のバッチ処理やREST APIと共存する期間をどう設計するか」です。
私のチームでは、いきなりすべての処理をCode Execution with MCP経由に切り替えるのではなく、次の3ステップで段階的に移行しました。
- PoC段階:読み取り専用のツールだけをMCP化し、エージェントからの参照を限定的に許可する
- 限定運用:既存バッチやAPIと並行稼働させつつ、一部ユースケースだけをCode Execution with MCPに切り替える
- 本番運用:モニタリングと障害対応フローが整った段階で、書き込み系ツールも含めて本番トラフィックを移行する
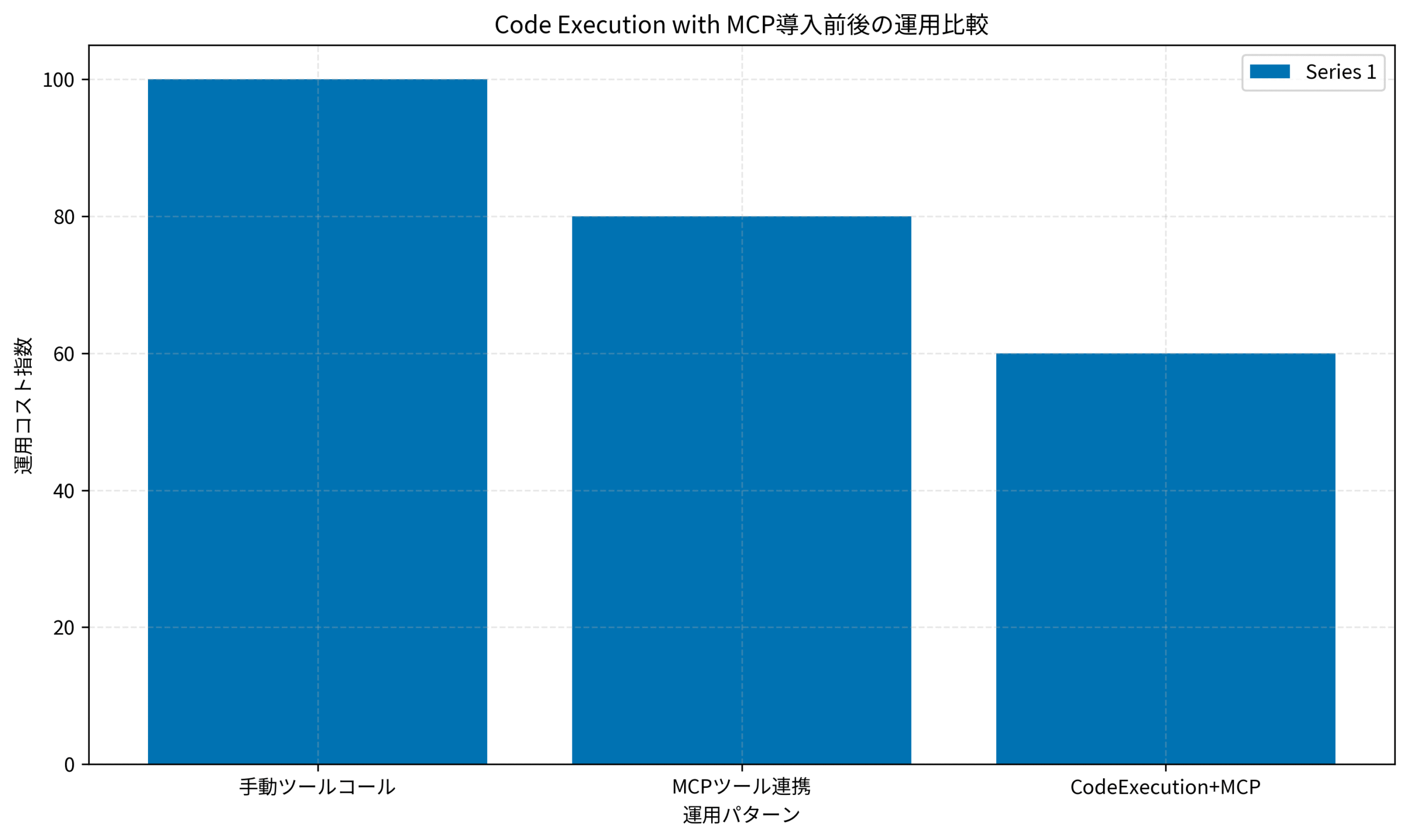
このとき、「どの時点でどの指標を見て次のステップに進むか」をあらかじめ合意しておくと、経営層や関係部門とのコミュニケーションも安定します。グラフで示したように、Code Execution with MCPの導入により、運用コストや障害調査工数を段階的に削減しつつ、リリース速度を維持できる状態を目指していきます。
安全な実行基盤を支えるガードレール設計
権限スコープとネットワーク境界を明示する
Code Execution with MCPを利用すると、エージェントが実行するコードの自由度が高まる一方で、「うっかり危険な操作を許してしまう」リスクも増えます。そのため、権限スコープとネットワーク境界を明示したガードレール設計が欠かせません。
具体的には、次のような設計を行いました。
- MCPサーバ側でツールごとに許可するエンドポイントとHTTPメソッドをホワイトリスト化する
- 書き込み系ツールは必ずバックエンド経由にし、直接DBにアクセスするツールは登録しない
- 監査ログには「どのコードスニペットが、どのツールを、どの引数で呼んだか」を記録する
外部向けのエッジでは、Cloudflare WAFのセキュリティ効果で紹介したようなWAFやレートリミットも組み合わせ、LLM経由のリクエストが予期せぬ攻撃パターンにならないよう多層防御を敷いています。実践サイバーセキュリティ入門講座を読み込みながら、「従来のWebアプリケーションと同じく、LLMまわりにも基本的なセキュリティ原則を適用する」という前提をチームに浸透させていくことが重要です。
失敗時ふるまいとロールバックを「仕様」として定義する
もう1つの大きなポイントは、「ツール呼び出しが失敗したときに、どのレイヤーがどのように振る舞うか」を仕様として定義しておくことです。
私のプロジェクトでは、Code Execution with MCPを導入する際に、次のようなルールを用意しました。
- 1回目の失敗はエージェント内でリトライするが、2回目以降はバックエンド側にエラーを返す
- 一部の重要ツールは「サーキットブレーカー」状態を設け、連続失敗時は自動停止する
- 書き込み系処理は必ず「検証 → 実行 → 検証」の3ステップで設計し、途中で失敗した場合はロールバック関数を呼び出す
こうしたルールを先に決めておくことで、障害発生時の意思決定がブレにくくなります。PjMとしても、「どこまでが自動復旧の範囲で、どこから先は人間が判断すべきか」を説明しやすくなりました。
LLM開発チームの運用プロセスとモニタリング
メトリクス設計でエージェントの健康状態を可視化する
Code Execution with MCP導入後は、「どのツールがどの頻度で呼ばれ、どの程度失敗しているか」を継続的に観測する仕組みが欠かせません。
私たちのチームでは、次のようなメトリクスをダッシュボード化しました。
- ツール呼び出し成功率(ツール別・ユースケース別)
- ツール呼び出しの平均レイテンシとP95
- コード実行エラー種別(バリデーションエラー・ネットワークエラー・タイムアウトなど)の件数
これらをOpenTelemetryベースのトレースと組み合わせることで、「どのリクエストがどのコード経由でどのツールを呼んだのか」を1本のタイムラインとして追えるようになりました。詳細な実装方法は、OpenTelemetry実装ガイド:分散トレーシングでマイクロサービスの可視化を実現するで紹介している考え方を流用し、LLMエージェントやMCPサーバにも同じ観測基盤を適用しています。チームトポロジーで整理されている「プラットフォームチーム」の役割を意識しつつ、エージェント基盤を継続的に改善していく体制を整えました。
PjMとしての定例レビューと改善サイクル
メトリクスを整備しただけでは、現場の運用は変わりません。PjMとしては、ダッシュボードを前提にした「定例レビューと改善サイクル」を設計する必要があります。
私の案件では、月次のレビューで次のような観点を必ず確認するようにしました。
- ツール別の失敗率が閾値を超えていないか
- コード実行エラーが特定ユースケースに偏っていないか
- 新しく追加したツールが、想定していたユースケースで十分に使われているか
このレビューの場で、開発チーム・運用チーム・ビジネス側が同じグラフを見ながら議論することで、「どの改善を次のスプリントで優先するか」を合意しやすくなりました。OKR的な指標設計を取り入れると、Code Execution with MCP導入の効果を定量的に語りやすくなります。

導入プロジェクトの進め方:PjMのチェックリスト
スモールスタートとステークホルダー調整
最後に、PjMの視点から「Code Execution with MCP導入プロジェクトをどう進めるか」を整理します。
私がおすすめしているのは、次のようなスモールスタートの進め方です。
- 最初は影響範囲の小さいユースケースを1〜2個だけ選び、読み取り専用ツールから試す
- 成功事例が得られたら、関係部署向けにデモと結果報告を行い、次の対象ユースケースを一緒に決める
- 書き込み系ユースケースに着手するのは、メトリクスとロールバック手順が整ってからにする
このとき、開発チームの技術選定プロセスで紹介しているように、「なぜこの技術を選んだのか」「どの指標で成功とみなすのか」を事前に文章化しておくと、ステークホルダー間の期待値を揃えやすくなります。アジャイルサムライに出てくるようなインセプションデッキを軽量な形で作成し、Code Execution with MCP導入のゴールイメージを共有してから着手するのがおすすめです。
成功事例をテンプレート化して次の案件につなげる
1つ目の案件で得られた知見は、そのまま次の案件のテンプレートになります。
私が実務で意識しているのは、次の3点です。
- ツール定義・コード実行パターン・メトリクス設計を「再利用可能なテンプレート」として残す
- 障害対応やヒヤリハット事例を必ず振り返り資料にまとめる
- 成功したユースケースを定期的に社内勉強会で共有し、チーム全体の心理的ハードルを下げる
こうした取り組みを続けることで、「Code Execution with MCPを使ったプロジェクト」が単発のチャレンジで終わらず、組織としての標準パターンに育っていきます。PjMとしては、個々の案件を成功させるだけでなく、「次の案件が楽になる仕組み」を残していくことが、長期的な価値につながります。

まとめ
Code Execution with MCPは、LLMエージェントから外部ツールや社内システムを呼び出す設計を、一段階引き上げてくれる仕組みです。一方で、設計や運用を誤ると、権限管理や監査ログ、ロールバック設計などの観点でリスクが増大する側面もあります。
本記事では、まず従来のツールコール設計が抱えていた限界を整理し、Code Execution with MCP導入によって「コードとしてツール連携を定義できる」メリットを確認しました。そのうえで、バックエンド・エージェント・MCPサーバの三層構造や、権限スコープとネットワーク境界を明示するガードレール設計、メトリクスとモニタリングを組み合わせた運用プロセスの作り方を紹介しました。
最後に、PjMとしての進め方として、スモールスタートとステークホルダー調整、成功事例のテンプレート化という3つのポイントを取り上げました。これらを意識しておけば、Code Execution with MCPを単なる「新機能」ではなく、チーム全体の生産性と安全性を高める基盤として育てていくことができます。
あなたのチームでも、まずは影響範囲の小さいユースケースからで構いません。小さく始めて学びを積み上げながら、Code Execution with MCPを活用した安全な実行基盤を、一緒に育てていきましょう。