IT女子 アラ美
IT女子 アラ美AI人材不足の今こそ自分の市場価値と年収相場を把握しておきなさい
ITエンジニアのハイクラス転職なら【TechGo(テックゴー)】
お疲れ様です!IT業界で働くアライグマです!
「MacBookでLLMの学習は遅すぎる」「GPUサーバー代が高い」と諦めていませんか?Unsloth-MLXを使えば、Apple Silicon搭載MacBookで驚くほど快適にファインチューニングができます。環境構築からLlama-3-8Bの学習、GGUF変換までをハンズオン形式で解説します。
Unsloth-MLXとは?:MacでLLM学習を加速させる技術
IT女子 アラ美Unslothと言えば、NVIDIA GPU向けに最適化された高速な学習ライブラリとして有名ですが、そのMac版(Apple Silicon対応版)が Unsloth-MLX です。
Appleの機械学習フレームワーク「MLX」をバックエンドに採用しており、M1/M2/M3チップのUnified Memoryアーキテクチャをフル活用することで、従来のPyTorch(MPS)と比較して圧倒的な高速化と省メモリ化を実現しています。より一般的なローカルLLM構築の完全ガイドも併せて参照すると、全体像が掴みやすくなります。
IT女子 アラ美Unsloth-MLXの環境構築手順
それでは早速、MacBookに環境を構築していきましょう。基本的にはPython環境があればすぐに導入可能です。
Python環境の準備
MLXはPython 3.10以上を推奨しています。ここでは venv を使って仮想環境を作成します。
# 作業用ディレクトリの作成
mkdir unsloth-mlx-demo
cd unsloth-mlx-demo
# 仮想環境の作成と有効化(Python 3.11を想定)
python3 -m venv venv
source venv/bin/activate
# 必須ライブラリのインストール
pip install --upgrade pip
pip install "unsloth[mlx]"これでUnslothのインストールは完了です。必要に応じて huggingface_hub なども入れておくと便利です。開発エディタとの連携については、CursorとローカルLLMの連携セットアップ完全ガイドを参考にしてください。
IT女子 アラ美【実装】Llama-3-8BをMacBookでファインチューニングする
環境が整ったら、実際にLlama-3-8Bモデルを読み込んで、サンプルデータセットで学習させてみましょう。Unsloth-MLXはKerasライクなAPIを提供しているため、非常に直感的に記述できます。
from unsloth import FastLanguageModel
import torch
# 1. モデルとトークナイザーのロード(4bit量子化でロード)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
# 2. LoRAアダプターの設定
model = FastLanguageModel.get_peft_model(
model,
r = 16, # 推奨値: 8, 16, 32...
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
)
# 3. 学習の実行(SFTTrainerラッパーを使用)
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
train_dataset = dataset, # 事前に用意したHuggingFaceデータセット
dataset_text_field = "text",
max_seq_length = 2048,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
),
)
trainer.train()上記のコードを実行すると、MacBookのGPUコアを使って学習が始まります。MPS(Metal Performance Shaders)に最適化されているため、少し前のMacBookでも驚くような速度が出ます。本格的なNVIDIA DGXとSparkによるローカルAI環境構築と比較しても、個人開発レベルでは十分すぎる性能です。
IT女子 アラ美推論とGGUF変換:学習済みモデルをローカルで動かす
学習が終わったら、作成したLoRAアダプターを使って推論を行います。また、Ollamaなどで使いやすいようにGGUF形式に変換することも可能です。
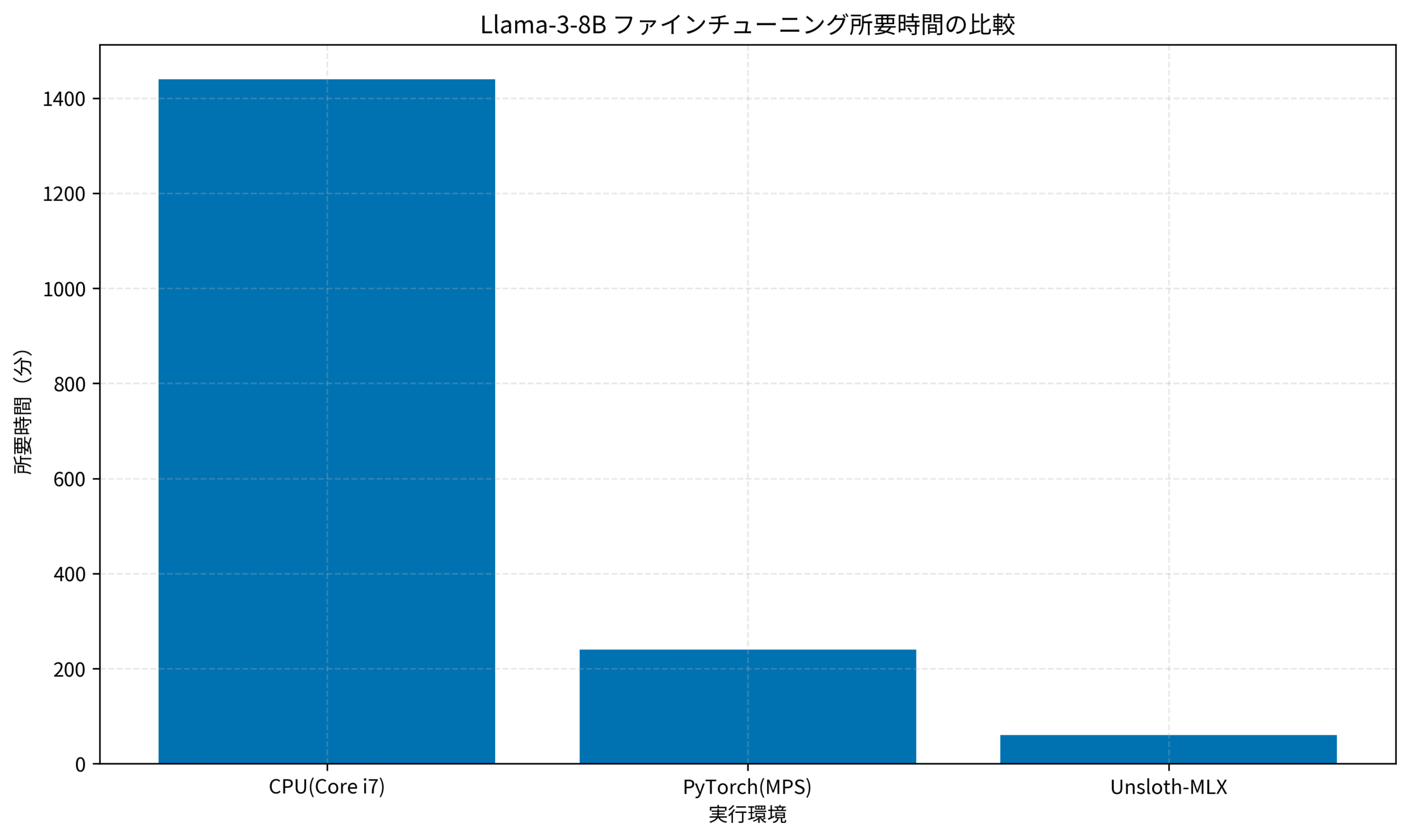
上のグラフは、Llama-3-8Bのファインチューニングにかかった時間を環境別に比較したものです。Unsloth-MLXを使うことで、PyTorch(MPS)と比較しても 4倍以上の高速化 が実現できています。CPU学習とは比較になりません。
GGUFへの変換
UnslothにはGGUF変換機能も組み込まれています。
# GGUF形式(q4_k_m)で保存
model.save_pretrained_gguf("model_contents", tokenizer, quantization_method = "q4_k_m")これで出力された .gguf ファイルを ollama create コマンドで読み込めば、自作の学習モデルをOllama経由でCursorやVSCodeの拡張機能から使えるようになります。具体的な連携方法は、CursorでローカルLLMを活用する方法で解説しています。
IT女子 アラ美MacBookでのLLM開発を加速させるためのヒント(ケーススタディ)
IT女子 アラ美実装経験を年収アップに直結させるなら社内SE特化エージェントに相談しなさい
社内SEを目指す方必見!IT・Webエンジニアの転職なら【社内SE転職ナビ】
松本さん(仮名・30歳・MLエンジニア・経験6年)がM2 Max搭載のMacBook Proでローカル学習環境を整備した事例を紹介します。
状況(Before)
- 環境:M2 Max (メモリ96GB)
- 課題:以前はクラウドGPU(A100)の時間課金が月額3万円を超えていた
- ストレス:ちょっとした実験コードを動かすのにもインスタンス起動待ちが発生
行動(Action)
Unsloth-MLXとOllamaを組み合わせた完全ローカル開発環境へ移行しました。
- 学習:Unsloth-MLXで小規模な検証(PoC)をローカル完結
- 推論:Ollamaサーバーを常駐させ、コーディング支援に自作モデルを活用
- 放熱対策:ノートPCクーラーを導入し、サーマルスロットリングを回避
結果(After)
- コスト削減:クラウド費用が月額3万円→ほぼ0円に
- 開発スピード:思いついた瞬間に学習を回せるようになり、試行錯誤の回数が倍増
- スキル向上:ローカルで深層までデバッグできるため、モデルの挙動への理解が深まった
松本さんは振り返ります。「最初からローカル環境を整備するのが正解だった。クラウドGPUに半年分の費用をかけずに済んだはずだし、手元で完結できる環境の価値を見くびっていたのが最大の反省です」。
こうしたAI開発スキルを活かしたキャリアアップについては、社内SE転職エージェント3社比較ガイドも参考にしてください。年収900万円以上を狙うならハイクラスエンジニア転職エージェント3社比較ガイド、フリーランスとして高単価案件を狙うならフリーランスエージェント5社比較ガイドもチェックしてみてください。
IT女子 アラ美Unsloth-MLXでつまずきやすいトラブルと対処法
ローカル学習ならではの詰まりポイントが3つあります。あらかじめ対処法を知っておけば、手戻りなく学習まで走り切れます。
トラブル1:メモリ不足(OOM)で学習が落ちる
Llama-3-8Bを4bit量子化でロードしても、入力系列長(max_seq_length)とバッチサイズの組み合わせ次第でメモリ不足が発生します。特にメモリ16GBのMacBook Airでは、デフォルトの設定では落ちるケースが多いです。
対処法は以下の通りです。
max_seq_lengthを 2048 → 1024 or 512 に削減per_device_train_batch_sizeを 1 に固定し、gradient_accumulation_stepsで実効バッチサイズを確保- バックグラウンドで動いている他のアプリ(Chrome、Slack、Docker Desktop等)を終了してメモリを開放する
トラブル2:サーマルスロットリングで学習が急減速する
MacBookはGPUコアを長時間フル稼働させると筐体温度が上昇し、サーマルスロットリングで学習速度が一気に半分以下に落ちることがあります。特にMacBook Air(ファンレス)では顕著です。
対処法は以下の通りです。
- ノートPCクーラー(外付けファン)を導入し、筐体下部を強制冷却する
max_stepsを細かく分割(例: 60→20×3回)し、間に冷却時間を挟む- 学習中はmacOSの「低電力モード」をオフにして、GPUコアを優先的に使用する
トラブル3:pip依存関係の衝突で環境が壊れる
pip install "unsloth[mlx]" を既存のPython環境に入れると、既にインストールされている torch や transformers とバージョンが衝突して既存プロジェクトが動かなくなることがあります。
対処法は以下の通りです。
- 必ず
venvで仮想環境を隔離し、本記事の環境構築手順通りに新規環境で作業する - 複数のLLM実験を並行する場合は、プロジェクトごとに別venvを切る
- conda派の方は
conda create -n unsloth python=3.11で隔離しても可
環境構築でつまずいた場合は、ローカルLLM構築の完全ガイドの基礎編から読み直すと解決のヒントが見つかります。手元のMacBookではどうしてもメモリや熱の壁を超えられない場合は、エンジニア向けXServer用途別比較ガイドでリモート開発向けのクラウドPCやGPU VPSを比較検討するのも有効な選択肢です。
IT女子 アラ美よくある質問
MacBook Airでも学習できますか?
メモリ16GB以上のM1/M2/M3搭載MacBook Airなら、4bit量子化を使えば小規模な学習は可能です。ただし発熱が大きいため、ノートPCクーラーの使用を推奨します。
Unsloth-MLXとNVIDIA版Unslothの違いは何ですか?
バックエンドが異なります。NVIDIA版はCUDA、MLX版はAppleのMLXフレームワークを使用します。APIはほぼ同じなので、コードの移植は容易です。
学習済みモデルをチームで共有するにはどうすればいいですか?
GGUFに変換してHugging Face Hubにアップロードするか、社内のファイルサーバーで共有するのが一般的です。Ollama経由で読み込めば、どのOSでも利用可能です。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
Unsloth-MLXの登場により、MacBookは単なる「開発機」から「学習ステーション」へと進化しました。
- 環境構築が簡単:
pip installだけでMLX最適化環境が手に入る - 圧倒的な高速化:PyTorch(MPS)比で数倍の速度向上
- コストゼロ:手持ちのMacで動くのでクラウド破産の心配なし
まずは今日紹介した手順で、手元のMacBookで小さなモデルの学習から始めてみてください。AI開発の景色がガラリと変わるはずです。
IT女子 アラ美