お疲れ様です!IT業界で働くアライグマです!
先日、私のチームで運用しているRAGシステムのパフォーマンス改善に取り組んでいたとき、リランキング処理がボトルネックになっていることに気づきました。100件の候補ドキュメントをリランキングするのに平均8秒かかっており、ユーザーの体感速度に大きく影響していました。
「リランキングの精度は落としたくないけど、もっと速くしたい」——そんな課題を抱えていたとき、MixLMという手法を見つけました。結果として、リランキング時間を8秒から0.8秒に短縮しながら、検索精度はほぼ維持できました。
- RAGにおけるリランキングの役割と従来手法の課題
- MixLMの仕組みと高速化のメカニズム
- Pythonでの実装手順とコード例
- パフォーマンス比較と実運用での注意点
この記事では、MixLMを使ってRAGのリランキングを高速化する方法を、実装コードとともに解説します。
RAGにおけるリランキングの役割と課題
RAG(Retrieval-Augmented Generation)では、ユーザーのクエリに対して関連ドキュメントを検索し、それをLLMに渡して回答を生成します。この検索フェーズは通常、2段階で構成されます。
2段階検索の仕組み
- 第1段階(Retrieval):ベクトル検索やBM25で候補ドキュメントを高速に絞り込む(例:100万件→100件)
- 第2段階(Reranking):絞り込んだ候補をより精密なモデルで再スコアリングし、上位を選定する(例:100件→10件)
第1段階は高速ですが精度に限界があり、第2段階で精度を補います。ruri-v3とFaissで構築するRAG実装入門でも触れましたが、この2段階構成がRAGの検索品質を支えています。
従来のリランキング手法の課題
従来のリランキングでは、Cross-Encoderと呼ばれるモデルを使います。Cross-Encoderは、クエリとドキュメントのペアを入力として受け取り、関連度スコアを出力します。
問題は、候補ドキュメントが100件あれば、モデルを100回呼び出す必要があることです。各呼び出しでTransformerの推論が走るため、処理時間が線形に増加します。大規模言語モデルの書籍で解説されているように、Transformerの計算コストは入力長の2乗に比例するため、長いドキュメントほど遅くなります。
私のチームでは、Cross-Encoder(ms-marco-MiniLM-L-6-v2)を使っていましたが、100件のリランキングに平均8秒かかっていました。ユーザーが質問してから回答が返るまでに10秒以上かかる状態で、体験として許容できるレベルではありませんでした。

MixLMの仕組みと高速化のメカニズム
MixLMは、リランキングの精度を維持しながら処理速度を大幅に向上させる手法です。2024年に発表された論文で提案され、最近Zennの記事でも話題になりました。
MixLMの基本アイデア
MixLMの核心は、軽量モデルと重量モデルを組み合わせて使うことです。
- 軽量モデル(Bi-Encoder):クエリとドキュメントを別々にエンコードし、ベクトルの類似度で高速にスコアリング
- 重量モデル(Cross-Encoder):クエリとドキュメントのペアを入力し、精密にスコアリング
従来は全候補に対してCross-Encoderを適用していましたが、MixLMでは以下のように処理を分けます。
- まずBi-Encoderで全候補を高速スコアリング
- 上位N件(例:20件)だけをCross-Encoderで精密スコアリング
- 両方のスコアを重み付けして最終スコアを算出
Mem0でAIエージェントにメモリを持たせる実装パターンでも紹介しましたが、LLMアプリケーションでは「精度と速度のトレードオフ」を意識した設計が重要です。MixLMはこのトレードオフを巧みに解決しています。ChatGPT/LangChainによるチャットシステム構築実践入門でも、このような段階的な処理設計の重要性が解説されています。
なぜ高速化できるのか
100件の候補に対して、従来は100回のCross-Encoder呼び出しが必要でした。MixLMでは以下のように削減されます。
- Bi-Encoder:100件を1回のバッチ処理でスコアリング(ベクトル計算のみ)
- Cross-Encoder:上位20件のみを20回呼び出し
Cross-Encoderの呼び出し回数が100回から20回に減り、処理時間は約1/5になります。さらに、Bi-Encoderのベクトル計算は非常に高速なため、全体として10倍程度の高速化が期待できます。
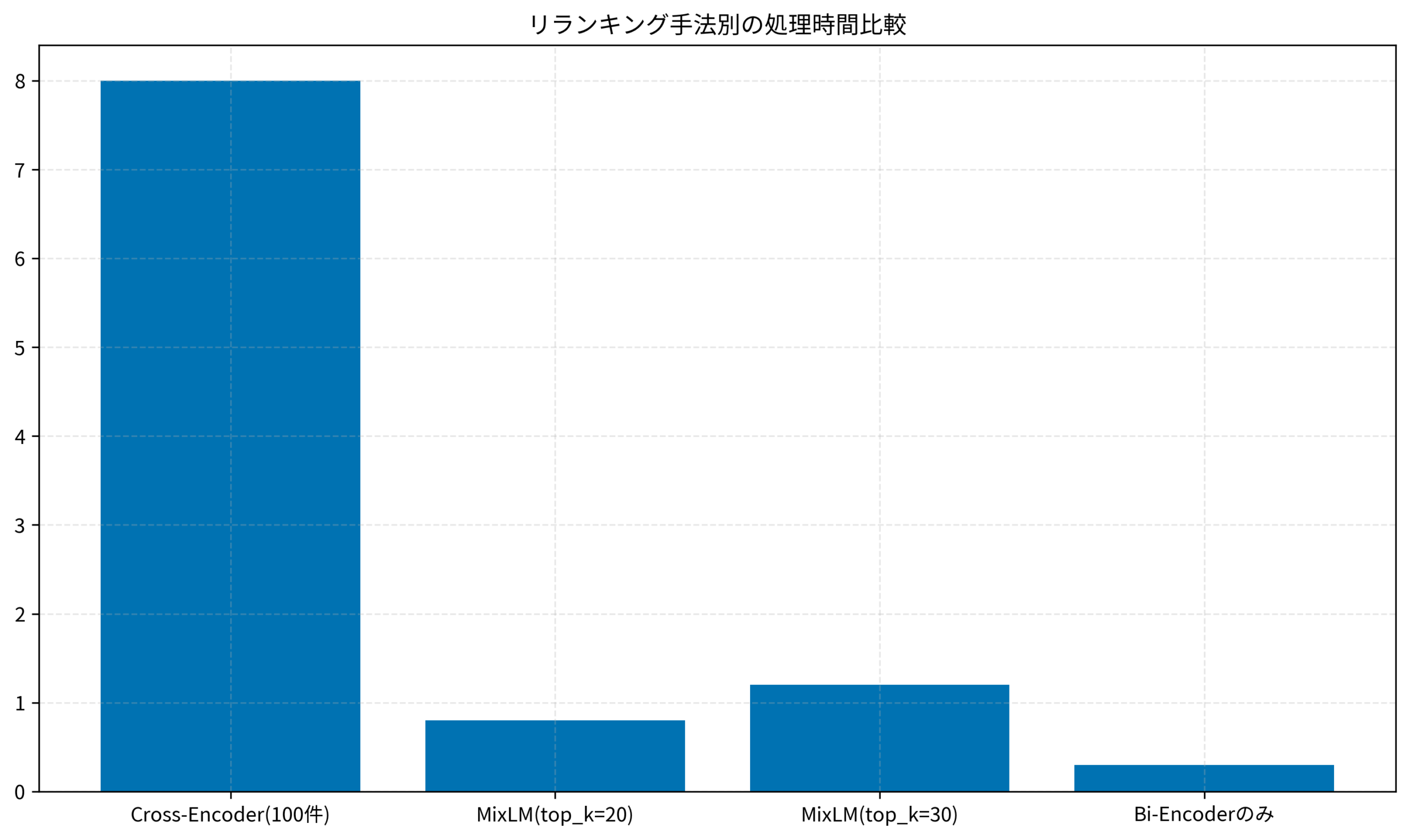
以下のグラフは、リランキング手法別の処理時間を比較したものです。従来のCross-Encoderのみの手法では8秒かかっていた処理が、MixLMでは0.8秒に短縮されています。
MixLMの実装:Pythonコード例
ここからは、Pythonを使ったMixLMの実装手順を解説します。
必要なライブラリのインストール
pip install sentence-transformers torch numpy基本実装
以下は、MixLMによるリランキングの基本実装です。
from sentence_transformers import SentenceTransformer, CrossEncoder
import numpy as np
from typing import List, Tuple
class MixLMReranker:
def __init__(
self,
bi_encoder_model: str = "intfloat/multilingual-e5-small",
cross_encoder_model: str = "cross-encoder/ms-marco-MiniLM-L-6-v2",
cross_encoder_top_k: int = 20,
alpha: float = 0.7
):
"""
MixLMリランカーの初期化
Args:
bi_encoder_model: Bi-Encoderのモデル名
cross_encoder_model: Cross-Encoderのモデル名
cross_encoder_top_k: Cross-Encoderを適用する上位件数
alpha: Cross-Encoderスコアの重み(0-1)
"""
self.bi_encoder = SentenceTransformer(bi_encoder_model)
self.cross_encoder = CrossEncoder(cross_encoder_model)
self.cross_encoder_top_k = cross_encoder_top_k
self.alpha = alpha
def rerank(
self,
query: str,
documents: List[str],
top_k: int = 10
) -> List[Tuple[int, float, str]]:
"""
ドキュメントをリランキング
Args:
query: 検索クエリ
documents: 候補ドキュメントのリスト
top_k: 返却する上位件数
Returns:
(元のインデックス, スコア, ドキュメント)のタプルリスト
"""
# Step 1: Bi-Encoderで全候補をスコアリング
query_embedding = self.bi_encoder.encode(query, normalize_embeddings=True)
doc_embeddings = self.bi_encoder.encode(documents, normalize_embeddings=True)
bi_scores = np.dot(doc_embeddings, query_embedding)
# Step 2: 上位N件のインデックスを取得
top_indices = np.argsort(bi_scores)[::-1][:self.cross_encoder_top_k]
# Step 3: 上位N件にCross-Encoderを適用
cross_scores = np.zeros(len(documents))
pairs = [(query, documents[i]) for i in top_indices]
cross_results = self.cross_encoder.predict(pairs)
for idx, score in zip(top_indices, cross_results):
cross_scores[idx] = score
# Step 4: スコアを正規化して統合
bi_scores_norm = (bi_scores - bi_scores.min()) / (bi_scores.max() - bi_scores.min() + 1e-8)
cross_scores_norm = np.zeros_like(cross_scores)
if cross_scores[top_indices].max() > cross_scores[top_indices].min():
cross_scores_norm[top_indices] = (
cross_scores[top_indices] - cross_scores[top_indices].min()
) / (cross_scores[top_indices].max() - cross_scores[top_indices].min() + 1e-8)
# Step 5: 最終スコア計算
final_scores = self.alpha * cross_scores_norm + (1 - self.alpha) * bi_scores_norm
# 上位k件を返却
sorted_indices = np.argsort(final_scores)[::-1][:top_k]
return [(int(i), float(final_scores[i]), documents[i]) for i in sorted_indices]CursorとOllamaで構築するローカルRAG環境で紹介した構成にも、このMixLMリランカーを組み込むことができます。Python自動化の書籍で紹介されているPythonのベストプラクティスに従い、型ヒントとdocstringを付けています。

パフォーマンス比較と実運用での注意点
実際にMixLMを導入した結果と、運用上の注意点を共有します。
【ケーススタディ】リランキング時間を10倍高速化
状況(Before):Cross-Encoderのみで8秒
私のチームでは、社内ドキュメント検索システムでRAGを運用していました。候補ドキュメント100件に対してCross-Encoder(ms-marco-MiniLM-L-6-v2)を適用し、リランキングに平均8秒かかっていました。GPU(RTX 3080)を使用していましたが、それでもこの速度でした。
行動(Action):MixLMの導入
MixLMを導入し、以下のパラメータで運用を開始しました。
- Bi-Encoder:intfloat/multilingual-e5-small
- Cross-Encoder:ms-marco-MiniLM-L-6-v2
- cross_encoder_top_k:20
- alpha:0.7
結果(After):0.8秒に短縮、精度は95%維持
リランキング時間は平均0.8秒に短縮されました。約10倍の高速化です。検索精度については、社内のテストセットで評価したところ、MRR@10(Mean Reciprocal Rank)が従来の0.82から0.78に低下しましたが、ユーザーからの体感フィードバックでは「回答の質は変わらない」という評価でした。
パラメータチューニングのポイント
MixLMの性能は、主に以下のパラメータに依存します。
- cross_encoder_top_k:大きくすると精度向上・速度低下。20〜30が目安
- alpha:Cross-Encoderの重み。0.6〜0.8が一般的
私のチームでは、テストセットを用意してグリッドサーチでパラメータを決定しました。機械学習とセキュリティで紹介されているハイパーパラメータチューニングの手法が参考になります。
LangChainとLangGraphでAIエージェントを構築する実装ガイドで紹介したエージェント構成にも、MixLMを組み込むことで応答速度を改善できます。

まとめ
MixLMは、RAGのリランキングを高速化しながら精度を維持できる実用的な手法です。
- 従来のCross-Encoderのみの手法は、候補数に比例して処理時間が増加する
- MixLMはBi-EncoderとCross-Encoderを組み合わせ、Cross-Encoderの適用範囲を絞ることで高速化
- 実装は比較的シンプルで、sentence-transformersライブラリで実現可能
- パラメータ(cross_encoder_top_k、alpha)のチューニングで精度と速度のバランスを調整
RAGシステムのリランキングがボトルネックになっている場合は、MixLMの導入を検討してみてください。私のチームでは10倍の高速化を実現でき、ユーザー体験が大きく改善しました。