
 IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
「Claude CodeのAPI費用が毎月かさんで厳しい…」「社内コードをクラウドに送るのはセキュリティ的に不安…」。こうした悩みを抱える開発者は少なくありません。実はClaude Codeは、環境変数を変更するだけでOllamaのローカルLLMに接続でき、コスト削減とプライバシー保護を同時に実現できます。
本記事では、Claude CodeとOllamaの連携設定から、推奨モデル、実際のコスト削減効果、セキュリティ面でのメリットまで、実践的な内容をお伝えしていきます。
Claude CodeでローカルLLMを使うべき3つの理由
IT女子 アラ美まず、なぜClaude CodeでローカルLLMを検討すべきなのか、明確な理由を整理しておきましょう。
これらの理由を理解することで、導入の判断基準が明確になります。
劇的なコスト削減効果
Claude CodeはAnthropicのAPIを従量課金で利用するため、使い込むほどコストが膨らみます。
特にClaude Opus 4.6を頻繁に使用する場合、月額コストが50〜100ドルを超えることも珍しくありません。
一方、ローカルLLMは初期設定のコストはかかりますが、ランニングコストは電気代程度です。
日常的なコード補完やリファクタリングをローカルLLMに任せ、難しい設計判断だけクラウドのClaudeを使う「ハイブリッド運用」で、API費用を80%以上削減できます。
例えば、5人の開発チームでClaude Codeを使っているケースでは、月額合計で約400ドルかかっていたAPI費用が、ローカルLLM導入後は電気代を含めても月額80ドル程度に抑えられ、年間3,800ドル以上の削減に成功した事例があります。
企業コードのプライバシー保護
Claude Codeを通常利用する場合、コードがAnthropicのAPIサーバーに送信されます。
機密性の高いプロジェクトや、企業のセキュリティポリシーが厳しい環境では、この点が大きな懸念となります。
ローカルLLMであれば、すべての処理が自社内で完結するため、コードが外部に流出するリスクを完全に排除できます。
特に金融機関や医療関連のシステム開発では、この安心感は非常に重要です。
以前、金融系プロジェクトで「クラウドAI利用禁止」というセキュリティ要件に直面しました。
PjMとして判断を迫られた結果、ローカルLLM環境を構築し、セキュリティ監査を通過しつつ開発効率も維持できました。
カスタマイズとコントロールの自由度
ローカルLLMでは、モデルの選択から細かなパラメータ調整まで、すべて自分でコントロールできます。
Claude Codeは --model オプションでモデルを自由に切り替えられるため、タスクに応じた最適なモデルを選択できます。
また、インターネット接続が不安定な環境でも、安定してAIアシスタント機能を利用できる点も大きなメリットです。
他のAIコーディングアシスタントとの比較については、AIコーディングアシスタント徹底比較の記事で詳しく解説していますので、ご参照ください。
IT女子 アラ美Ollamaを使ったローカルLLM環境の構築
Claude CodeでローカルLLMを活用するための最も簡単な方法は、Ollamaを使用することです。
ここでは、Ollamaのインストールから初期設定までの手順を詳しく解説します。
Ollamaのインストールと基本設定
まず、Ollamaの公式サイトからインストーラーをダウンロードします。
Windows、Mac、Linuxすべてに対応しており、インストール手順は非常にシンプルです。
インストール後、ターミナルで「ollama –version」を実行し、正常にインストールされていることを確認しましょう。
次に、「ollama serve」コマンドでOllamaサーバーを起動します。
デフォルトでは、localhost:11434でAPIサーバーが起動し、Claude CodeからHTTP経由でアクセスできるようになります。
推奨モデルのダウンロードと比較
Ollamaでは様々なモデルが利用可能ですが、Claude Codeとの連携でコーディング用途に適したモデルは以下の通りです。
Qwen3-Coder 30B:MoEアーキテクチャで省VRAM。日本語対応、256Kコンテキスト、エージェント特化訓練済み。Claude Codeとの相性が最も良い
Qwen2.5-Coder 7B:軽量で高速。8GB VRAM でも動作し、日常的なコード補完に最適
DeepSeek-V3:高精度で複雑な設計判断にも対応可能。VRAM 24GB以上推奨
「ollama pull qwen3-coder:30b」のようなコマンドでモデルをダウンロードできます。
初回ダウンロードには時間がかかりますが、一度ダウンロードすればオフラインで使用可能です。
最新のローカルLLMモデルについては、DeepSeek-V3.2実務検証レポートでモデル選定の参考にしてください。
メモリとGPU要件の最適化
ローカルLLMの性能は、使用するハードウェアに大きく依存します。
Qwen2.5-Coder 7Bであれば8GB VRAM、Qwen3-Coder 30B(MoE)であれば16GB VRAM、DeepSeek-V3であれば24GB VRAM以上が推奨です。
NVIDIA GPUがある場合は、CUDA加速により処理速度が大幅に向上します。
特にRTX 4070以上のGPUを搭載している場合は、CPU処理と比較して5〜10倍の高速化が期待できます。
IT女子 アラ美Claude CodeとOllamaの連携設定手順
Ollama環境が整ったら、次はClaude Codeとの連携設定を行います。
この設定により、Claude Codeからローカルで動作するLLMを直接利用できるようになります。
環境変数の設定
Claude CodeとOllamaの連携は、環境変数を2つ設定するだけで完了します。
ターミナルで以下のコマンドを実行してください。
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
この設定により、Claude CodeのAPI通信先がAnthropicのクラウドからローカルのOllamaサーバーに切り替わります。
モデル指定と起動
環境変数を設定したら、--model オプションで使用するモデルを指定してClaude Codeを起動します。
claude --model qwen3-coder:30b
シェルエイリアスを設定しておくと、クラウドとローカルの切り替えがワンコマンドで可能になります。
.bashrc や .zshrc に以下を追加しておくと便利です。
alias cc-local='ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_BASE_URL=http://localhost:11434 claude --model qwen3-coder:30b'
alias cc-opus='claude' # 通常のクラウド版
動作テストとトラブルシューティング
設定完了後、実際にClaude Codeでコード生成を試してみましょう。
cc-local でClaude Codeを起動し、簡単なコード生成リクエストを送信します。
正常に動作しない場合は、以下の点を確認してください。
- Ollamaサーバーが正常に起動しているか(
curl http://localhost:11434/api/tagsで確認) - ポート11434がファイアウォールでブロックされていないか
- 使用するモデルが正しくダウンロードされているか(
ollama listで確認)
Claude Codeの高度な活用方法については、Claude Code Antigravity Awesome Skills 完全ガイドで詳しく解説していますので、併せてご覧ください。
IT女子 アラ美パフォーマンス最適化と実用的な活用方法
ローカルLLM環境が構築できたら、実際の開発業務での活用方法とパフォーマンス最適化について解説します。
適切な設定により、クラウドLLMに匹敵する体験を得ることができます。
コンテキストウィンドウの最適化
Claude Codeはシステムプロンプトとツール定義だけで約11,000トークンを使用します。
ローカルLLMの性能を最大化するためには、コンテキストウィンドウが十分に大きいモデルを選ぶことが重要です。
Qwen3-Coder 30Bは256Kトークンのコンテキストに対応しており、Claude Codeの長大なプロンプトでも余裕を持って処理できます。
8B以下の小型モデルではコンテキスト不足でツール呼び出しが失敗することがあるため注意してください。
タスク別のモデル使い分け
すべてのタスクをローカルLLMで処理する必要はありません。
タスクの複雑さに応じて、ローカルとクラウドを使い分けることで最大の効果が得られます。
- ローカル向き:コード補完、簡単なリファクタリング、テストコード生成、ドキュメント作成
- クラウド向き:複雑なアーキテクチャ設計、大規模なコードレビュー、マルチファイルの横断的な変更
先述のシェルエイリアスで cc-local と cc-opus を切り替えるだけなので、運用コストはほぼゼロです。
特定言語・フレームワーク向けの微調整
Claude Codeの CLAUDE.md ファイルにプロジェクト固有のコーディング規約を記載しておくと、ローカルLLMでもそのルールに従ったコード生成が可能になります。
また、よく使用するプログラミング言語やフレームワークがある場合は、それに特化したモデルを選択することも有効です。
例えば、Python中心のプロジェクトであればQwen3-Coder、TypeScript中心であればDeepSeek-Coderが適しています。
ローカルLLMのパフォーマンスチューニングについては、CursorでローカルLLMを使いこなす完全ガイドの設定例も参考になります。
IT女子 アラ美コスト分析と投資回収期間の計算(ケーススタディ)
IT女子 アラ美ローカルLLM環境の導入を検討する際には、具体的なコスト分析と投資回収期間を把握することが重要です。
ここでは、佐藤さん(仮名・35歳・バックエンドエンジニア・経験10年)のチームでの導入事例をもとに、実際の数値を用いて詳細な分析を行います。
初期投資コストの内訳
ローカルLLM環境の初期投資として、以下のコストが必要になります。
- 高性能GPU(RTX 4070 Super):約90,000円
- 追加RAM(32GB DDR5):約20,000円
- 高速SSD(1TB NVMe):約12,000円
- 電力供給強化:約10,000円
合計で約132,000円の初期投資が必要ですが、これは一度限りのコストです。
月額コストの比較
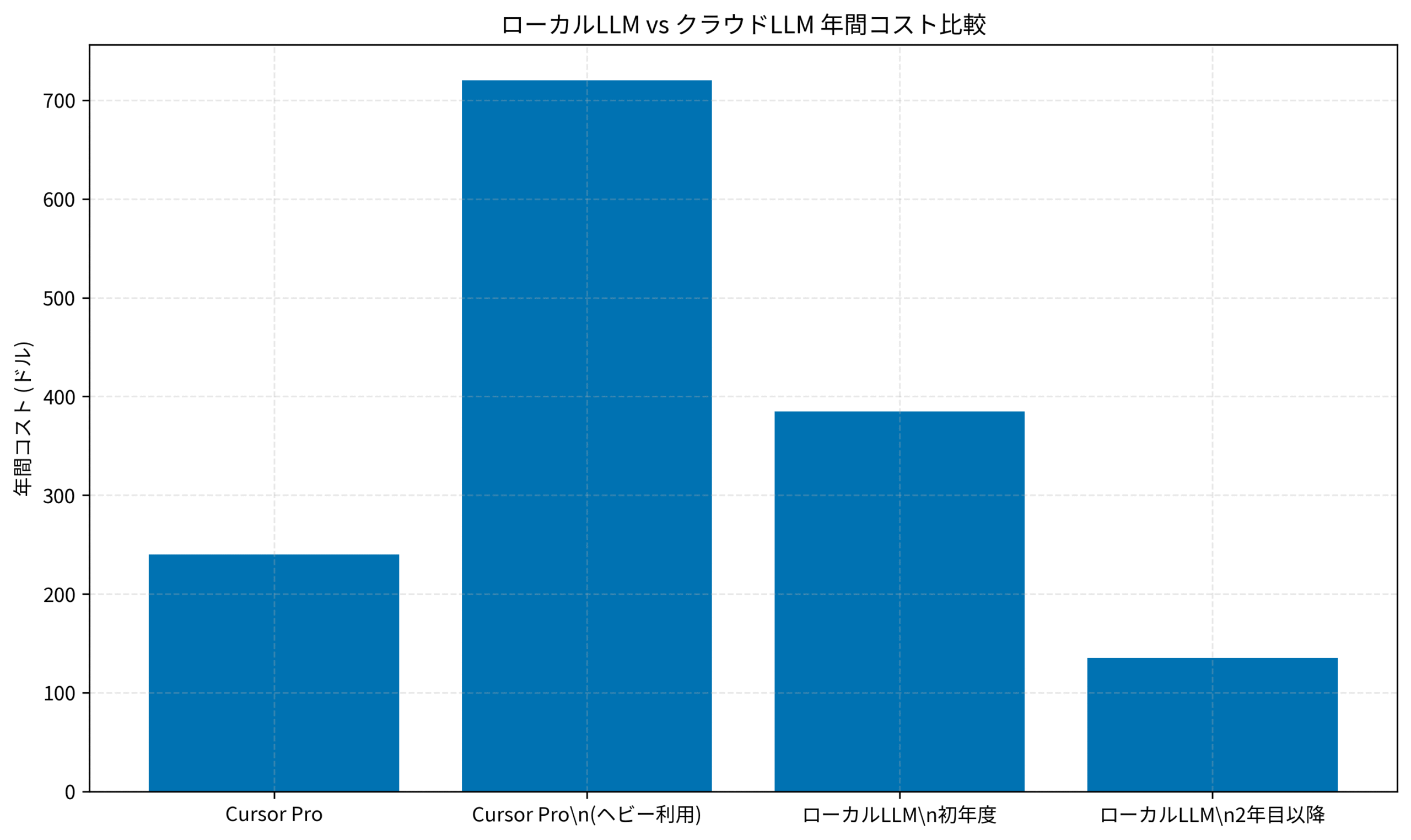
Claude CodeのAPI費用を月額80ドル使用している場合と、ローカルLLMの月額電気代15ドル+クラウド利用(難しいタスクのみ)20ドルを比較すると、月額45ドル(約6,750円)の削減効果があります。
年間では540ドル(約81,000円)の削減となり、初期投資の回収期間は約1.6年となります。
2年目以降は純粋な節約効果として、年間8万円前後の削減が期待できます。
生産性向上による付加価値
単純なコスト削減だけでなく、オフライン環境での利用可能性や、カスタマイズによる生産性向上も考慮すべきです。
適切に調整されたローカルLLMは、プロジェクト固有の要件により適合したコード生成が可能になります。
また、企業での利用を考えると、セキュリティ面での価値は金銭的な計算以上に重要な要素となります。
以下のグラフは、Claude Code API従量課金とローカルLLMハイブリッド運用の年間コストを比較したものです。
初年度は初期投資が含まれますが、2年目以降は大幅なコスト削減効果が明確に表れます。
AIツールのコスト最適化については、Open NotebookでローカルNotebookLMを構築する方法もコスト削減の参考になります。
IT女子 アラ美実践的トラブルシューティング事例
ローカルLLM環境を運用していると、様々な問題に直面することがあります。
ここでは、実際によく発生するトラブルと解決方法を紹介します。
レスポンス速度が遅い場合の対処法
Ollamaのレスポンスが遅い場合、まず確認すべきはVRAMの使用状況です。
nvidia-smi コマンドでGPUメモリが逼迫していないかチェックしましょう。
メモリが不足している場合は、以下の対策が有効です。
- より軽量なモデル(Qwen2.5-Coder 7B)に切り替える
- 他のGPU使用アプリケーションを終了してVRAMを確保
- Ollama の
OLLAMA_NUM_PARALLELを1に設定して並列処理を抑制
また、GPUを使用している場合は、NVIDIAのドライバが最新バージョンに更新されているか確認してください。
古いドライバを使用していると、CUDA加速が正常に動作せず、処理速度が大幅に低下することがあります。
接続エラーが頻発する場合
「Connection refused」や「Timeout」エラーが発生する場合は、以下を確認してください。
まず、Ollamaサーバーが正常に起動しているかを確認します。
ターミナルで「curl http://localhost:11434/api/tags」を実行し、モデル一覧が表示されるかテストしましょう。
次に、ファイアウォール設定を確認します。
Windows Defenderやサードパーティのセキュリティソフトが、ローカルホストの通信をブロックしている可能性があります。
企業環境の場合、プロキシサーバー経由での接続が必要な場合もあります。
システム管理者に相談し、適切なプロキシ設定を確認してください。
モデル切り替えがうまくいかない場合
Claude Code側で --model オプションを変更しても期待通りの応答が得られない場合は、Ollama側の状態を確認してください。
まず ollama list コマンドで、指定したモデルが正しくダウンロードされているか確認しましょう。
モデルのダウンロードが途中で失敗している場合は、ollama pull <model_name> で再ダウンロードを実行してください。
また、Claude Codeのツール呼び出し(function calling)に対応していないモデルでは、ファイル編集やコマンド実行が正常に動作しません。
Qwen3-CoderやDeepSeek-V3など、function callingをサポートするモデルを選択してください。
ローカル開発環境の構築については、nanobotで軽量AIボットをローカル構築する方法も併せてご覧ください。
IT女子 アラ美セキュリティとプライバシーの考慮事項
企業環境でローカルLLMを導入する際は、セキュリティとプライバシーの観点から追加的な考慮が必要です。
適切なセキュリティ対策により、安心してローカルLLMを活用できます。
データ流出防止策
Claude CodeをローカルLLMで使用する最大の利点は、コードがAnthropicのサーバーに一切送信されないことです。
完全にセキュアな環境を構築するためには、ネットワーク分離、アクセス制限、ログ監視などの多層防御を実装しましょう。
特に機密性の高いプロジェクトでは、専用のオフライン環境でローカルLLMを運用することを推奨します。
アクセス制御と監査ログ
複数の開発者がローカルLLMを共有する場合は、適切なアクセス制御機能を実装する必要があります。
ユーザー認証、権限管理、使用状況の監査ログを整備することで、セキュリティインシデントを防止できます。
また、定期的なセキュリティ監査を実施し、潜在的な脆弱性を早期に発見・対処することも重要です。
コンプライアンス対応
業界によっては、特定のコンプライアンス要件に対応する必要があります。
GDPR、HIPAA、PCI DSSなどの規制に応じて、適切なデータ保護措置を実装しましょう。
ローカルLLMの導入により、これらのコンプライアンス要件を満たしやすくなる場合が多いですが、詳細な検討は専門家に相談することをおすすめします。
セキュリティを意識した開発環境については、Microsoft LiteBoxでRust製Linuxサンドボックスを構築する方法も参考になります。
IT女子 アラ美よくある質問
ローカルLLMでClaude Codeの全機能が使えますか?
ファイル編集やコマンド実行などのツール呼び出し機能は、function callingに対応したモデル(Qwen3-Coder、DeepSeek-V3など)でのみ動作します。8B以下の小型モデルではツール呼び出しが正常に動作しない場合があります。
ローカルLLMとクラウドを併用する場合、切り替えは面倒ではないですか?
シェルエイリアスを設定しておけば、cc-local と cc-opus のようにワンコマンドで切り替え可能です。環境変数の変更だけなので、ツールの再インストールなどは不要です。
GPUを持っていない場合でもローカルLLMは使えますか?
CPU環境でも動作しますが、レスポンス速度が大幅に低下します。Qwen2.5-Coder 7Bなど軽量モデルであればCPUでも実用的な速度で動作しますが、本格的に活用するならGPU搭載マシンかクラウドGPUサービスの利用を推奨します。
ローカルLLM環境の構築に適したクラウドPCやサーバーサービスを選ぶ際は、GPU対応・ストレージ容量・月額コストの3点を重視してください。
未経験からITエンジニアを目指したい方は、以下のIT業界特化型の転職エージェントを活用するのが近道です。
| 比較項目 | ラクスパートナーズ | ユニゾンキャリア | @PRO人(未経験) |
|---|---|---|---|
| 研修・学習 | 3ヶ月自社研修実プロジェクトベース | 学習相談ありIT知識サポート | 基礎から支援学習方法の相談可 |
| 求人の質 | 有名企業常駐中心 | 優良企業を厳選 | 未経験・育成枠 |
| サポート体制 | 正社員雇用+研修 | Google★4.8 | 入社後フォローあり |
| おすすめ度 | 未経験から正社員 | A口コミ重視なら | A丁寧な伴走型 |
| 公式サイト | 無料相談する | - | - |
IT女子 アラ美まとめ
Claude CodeとOllamaを連携してローカルLLMを活用することで、大幅なコスト削減とプライバシー保護を同時に実現できます。
- 環境変数2つの設定だけでClaude CodeをローカルLLMに接続可能
- 日常タスクはローカル、難しい設計はクラウドの使い分けでAPI費用を80%以上削減
- 初期投資の回収期間は約1.6年で、2年目以降は年間8万円前後の削減効果
セキュリティ面でのメリットも大きく、企業の機密コードを外部に送信するリスクを完全に排除できます。
適切なセキュリティ対策と組み合わせることで、安心してAIアシスタント機能を活用できる環境を構築できるでしょう。
IT女子 アラ美







