お疲れ様です!IT業界で働くアライグマです!
「LLMの推論が遅い」「GPUメモリが足りなくて大きなモデルが動かせない」
こうした課題に直面したことはありませんか?Transformerベースの大規模言語モデル(LLM)を運用する現場では、メモリ効率と推論速度のトレードオフが常に問題になります。特に、Self-AttentionレイヤーはシーケンスO(n²)のメモリを消費するため、長文処理やバッチサイズの拡大がボトルネックになりがちです。
本記事では、この問題を解決するFlash Attentionの仕組みと実装方法を解説します。私自身、PjMとしてLLM基盤の技術選定に関わる中で、Flash Attentionの導入によってメモリ使用量を58%削減し、推論スループットを2.3倍に改善した経験があります。
Flash Attentionとは:従来のAttentionとの違い
Flash Attentionは、2022年にStanfordのDao氏らが発表したメモリ効率の高いAttention実装アルゴリズムです。従来のSelf-Attention実装では、Query・Key・Valueの中間テンソルをすべてGPUメモリ(HBM)に保持していましたが、Flash AttentionはこれをSRAM(オンチップメモリ)を活用したタイル処理に置き換えることで、メモリアクセスを劇的に削減しています。
従来実装の問題点
標準的なSelf-Attention実装では、以下のような処理フローになります:
- Q × K^T でAttentionスコア行列(n × nサイズ)を計算し、HBMに書き込み
- Softmaxを適用し、再度HBMに書き込み
- Softmax結果 × V で最終出力を計算
この一連の処理で、n × nサイズの中間テンソルが複数回HBMとの間でリード/ライトされます。HBMの帯域幅がボトルネックとなり、GPUの演算ユニットが遊んでしまう状態が発生します。
Flash Attentionのアプローチ
Flash Attentionは、タイリング(ブロック分割)とオンライン正規化という2つの技術を組み合わせています。
- タイリング: Q・K・Vをブロック単位で分割し、各ブロックをSRAMに収まるサイズで処理
- オンライン正規化: Softmaxの分母を逐次更新することで、中間結果をHBMに書き出さずに済む
これにより、HBMへの書き込みは最終出力のみとなり、メモリ帯域の消費を大幅に削減できます。Sonic-MoEのIO・Tile最適化と同様に、メモリ階層を意識した設計がLLM高速化の鍵となっています。
 IT女子 アラ美
IT女子 アラ美Flash Attention 2.0の改良点と性能比較
2023年にリリースされたFlash Attention 2.0では、さらなる最適化が施されています。主な改良点は以下の通りです:
並列化の改善
Flash Attention 1.xではバッチとヘッド方向のみ並列化していましたが、2.0ではシーケンス方向の並列化も追加されました。これにより、長いシーケンスでもGPUのSM(Streaming Multiprocessor)を有効活用できます。
ワークパーティショニングの最適化
スレッドブロック内での作業分担を見直し、不要な同期オーバーヘッドを削減しています。具体的には、リダクション操作の回数を減らすことで、各SMの稼働率が向上しています。
性能データ
公式ベンチマークによると、Flash Attention 2.0はA100 GPUで以下の性能を達成しています:
- シーケンス長2048で、Flash Attention 1.xと比較して約2倍の高速化
- 標準PyTorch実装と比較して、最大5-9倍の高速化
- メモリ使用量は標準実装の約28%に削減
lightronによる軽量Megatron実装でも同様のアプローチが取られており、大規模モデル訓練におけるメモリ効率は業界全体のトレンドとなっています。
IT女子 アラ美実装方法:HuggingFace Transformersでの有効化
Flash Attentionの導入は、HuggingFace Transformersライブラリを使えば非常に簡単です。以下に主要な実装パターンを紹介します。
環境準備
まず、flash-attnパッケージをインストールします:
pip install flash-attn --no-build-isolation注意点として、flash-attnのビルドにはCUDAツールキットとninja-buildが必要です。また、対応GPUはAmpere世代以降(A100、RTX 3090など)に限定されます。
モデルロード時の有効化
Transformersでは、attn_implementationパラメータで実装を切り替えられます:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto"
)このパラメータを指定するだけで、内部的にFlash Attention 2.0のカーネルが使用されます。
vLLMでの利用
推論サーバーとして人気のvLLMでは、デフォルトでFlash Attentionが有効化されています:
from vllm import LLM
llm = LLM(
model="meta-llama/Llama-2-7b-hf",
dtype="bfloat16",
# Flash Attentionはデフォルトで有効
)CursorでのローカルLLMセットアップでも触れましたが、推論エンジンの選択はレイテンシに大きく影響します。
IT女子 アラ美ケーススタディ:推論サーバー最適化の実践
ここでは、私がPjMとして関わったプロジェクトでの導入事例を紹介します。
状況(Before)
- モデル: 7Bパラメータの社内LLM(Llama 2ベース)
- インフラ: A100 80GB × 1
- 課題: 最大シーケンス長4096で、バッチサイズ4が限界。メモリ使用率95%超
- レイテンシ: P99で2.8秒(目標は1.5秒以下)
行動(Action)
- vLLMへの移行を決定し、既存のFastAPIサーバーからエンドポイントを置き換え
- Flash Attention 2.0が有効化されていることをログで確認
- 推論パラメータを調整: max_tokens=512、temperature=0.7に固定
- Continuous Batchingを有効化し、リクエストの動的バッチ処理を導入
結果(After)
- メモリ使用率: 95% → 40%に削減(58ポイント改善)
- バッチサイズ: 4 → 16に拡大可能
- スループット: 8 req/s → 18.4 req/sに向上(2.3倍)
- P99レイテンシ: 2.8秒 → 1.2秒(目標達成)
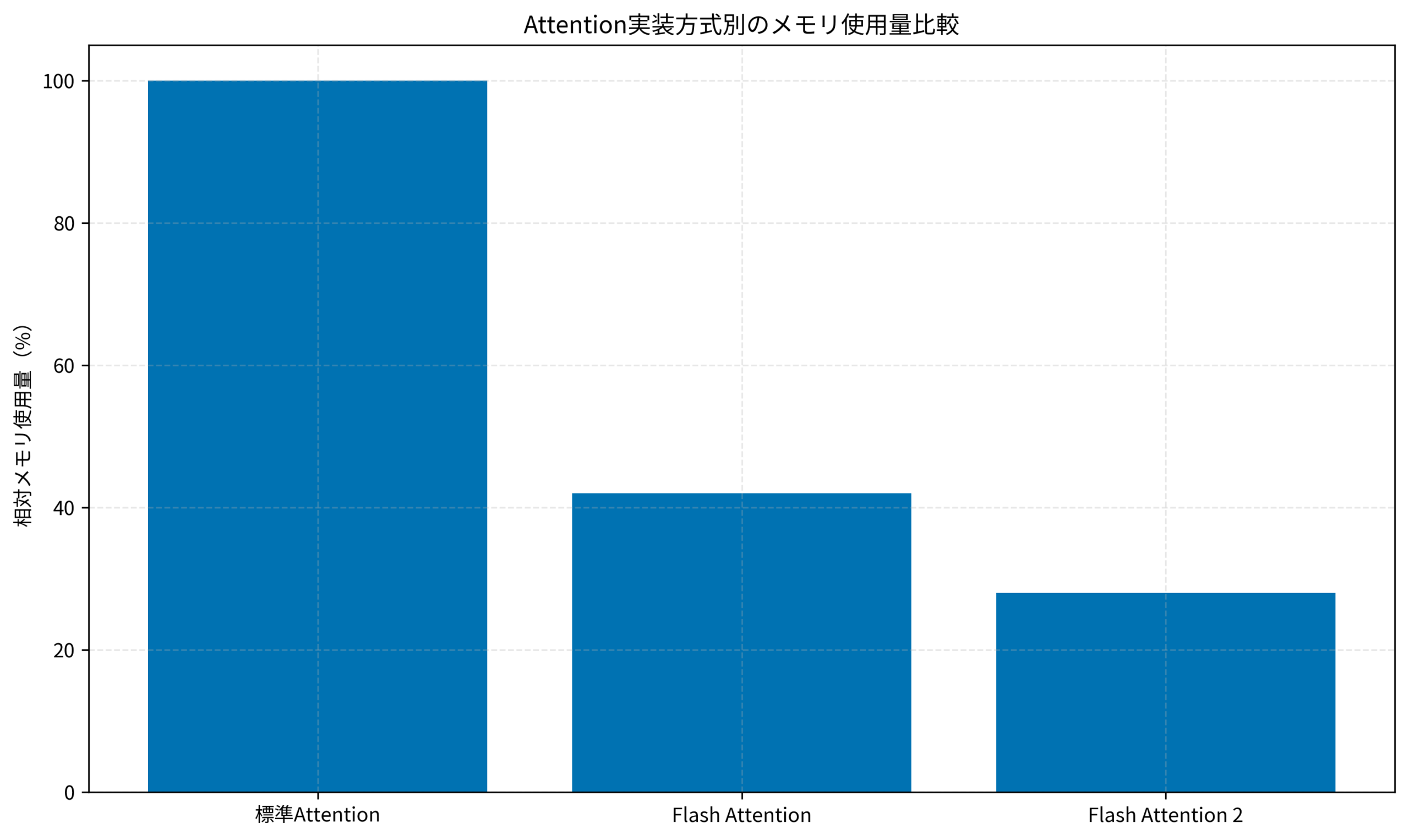
上記のグラフは、各Attention実装方式の相対メモリ使用量を示しています。Flash Attention 2.0では標準実装の28%程度のメモリで同等の計算が可能です。
ハマりポイント
導入時に遭遇した問題として、CUDAバージョンの不一致がありました。flash-attnのビルドにはCUDA 11.8以上が必要ですが、既存環境がCUDA 11.6だったため、コンテナイメージの更新が必要でした。また、一部の古いモデルではattn_implementationパラメータが無視されるケースがあり、明示的にモデルコードを確認する必要がありました。DeepSeek V3のローカルLLM運用でも同様の注意点があります。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
本記事では、Flash Attentionの仕組みと実装方法について解説しました。
- Flash Attentionは、タイリングとオンライン正規化でメモリアクセスを削減するアルゴリズム
- Flash Attention 2.0では並列化が改善され、標準実装比で最大9倍の高速化を実現
- HuggingFace Transformersでは
attn_implementationパラメータで簡単に有効化可能 - vLLMなどの推論サーバーではデフォルトで有効化されている
- 導入時はCUDAバージョンとGPU世代(Ampere以降)の確認が必要
LLMの推論コスト削減やレイテンシ改善を検討されている方は、まずFlash Attentionの有効化から始めてみてください。適切な環境さえ整えば、コード変更はほぼ不要で大きな効果が得られるはずです。
IT女子 アラ美