IT女子 アラ美
IT女子 アラ美TanStack DBでローカルファースト開発を実現する方法を解説
自分らしく働けるエンジニア転職を目指すなら【strategy career】
お疲れ様です!IT業界で働くアライグマです!
結論から言うと、TanStack DBは「クライアント側にリアルタイム同期可能なデータベースを持つ」という設計思想を実現するための新しいライブラリです。
TanStack Queryが「サーバーからデータを取得してキャッシュする」ことに特化しているのに対し、TanStack DBは「クライアント側に永続化されたデータストアを持ち、そこに対してクエリを実行する」というまったく異なるアプローチを取ります。
フロントエンドの状態管理が複雑化し、オフライン対応やリアルタイム同期の要件が増えてきた今、「フェッチライブラリの延長」ではカバーしきれない領域が出てきました。この記事では、TanStack DBの基本概念からTanStack Queryとの比較、そして実際の導入パターンまでを解説します。
TanStack DBとは何か:クライアントDBの概念整理
IT女子 アラ美TanStack DBは、TanStack(旧React Query)のエコシステムに新しく加わったライブラリで、2025年12月に正式リリースされました。ブラウザやネイティブアプリのクライアント側に、SQLiteのようなリレーショナルデータベースを持ち、そこに対してクエリを実行するというコンセプトを持っています。
従来のフェッチライブラリとの根本的な違い
従来のフェッチライブラリは「サーバーからのレスポンスをキャッシュする」という発想でしたが、TanStack DBは「クライアント側にデータの真実のソースを持つ」という発想です。これにより、オフライン時でもデータの読み書きができ、オンラインになったときにサーバーと同期するというローカルファーストアーキテクチャが実現できます。
あるプロジェクトでは、フィールドワーカー向けのアプリでネットワーク接続が不安定な環境での利用が求められ、このようなローカルファーストの設計が必要になることがあります。従来はIndexedDBを直接操作していましたが、APIが低レベルで実装コストが高く、チームメンバーの習熟にも時間がかかるという課題がありました。TanStack DBを使えばより宣言的に同じ要件を満たせます。
関連する記事として、CursorとOllamaで構築するローカルRAG環境でもローカル環境でのデータ活用について触れています。
IT女子 アラ美TanStack Queryとの違いを明確にする
TanStack QueryとTanStack DBは名前が似ていますが、設計思想がまったく異なります。ここでは両者の違いを整理します。
データの所在と同期モデル
TanStack Queryは「サーバーが真実のソース」という前提に立っています。クライアントはサーバーからデータを取得し、キャッシュとして保持します。キャッシュは一時的なもので、revalidationによって最新のデータに更新されます。
一方、TanStack DBは「クライアントが真実のソース」になり得るモデルです。データはクライアント側のデータベースに永続化され、サーバーとの同期は非同期で行われます。この同期モデルは、楽観的更新(Optimistic Updates)を標準的な動作として組み込んでいます。
適材適所の選択基準
TanStack Queryが適しているケースとしては、以下のような状況が挙げられます。
- サーバーサイドのREST APIやGraphQLからデータを取得する一般的なWebアプリ
- リアルタイム性はあまり求められないが、データの鮮度は重要な場合
- オフライン対応が不要、または限定的なキャッシュで十分な場合
- データ量が多く、すべてをクライアントに持つのが現実的でない場合
TanStack DBが適しているケースとしては、以下のような状況が挙げられます。
- オフラインでも完全に動作する必要があるアプリ(フィールドワーク用、モバイルアプリなど)
- 複数のUIで同じデータを異なる形式で表示する必要がある場合
- クライアント側でのフィルタリング・ソート・集計が頻繁に発生する場合
- リアルタイムコラボレーション機能が必要な場合
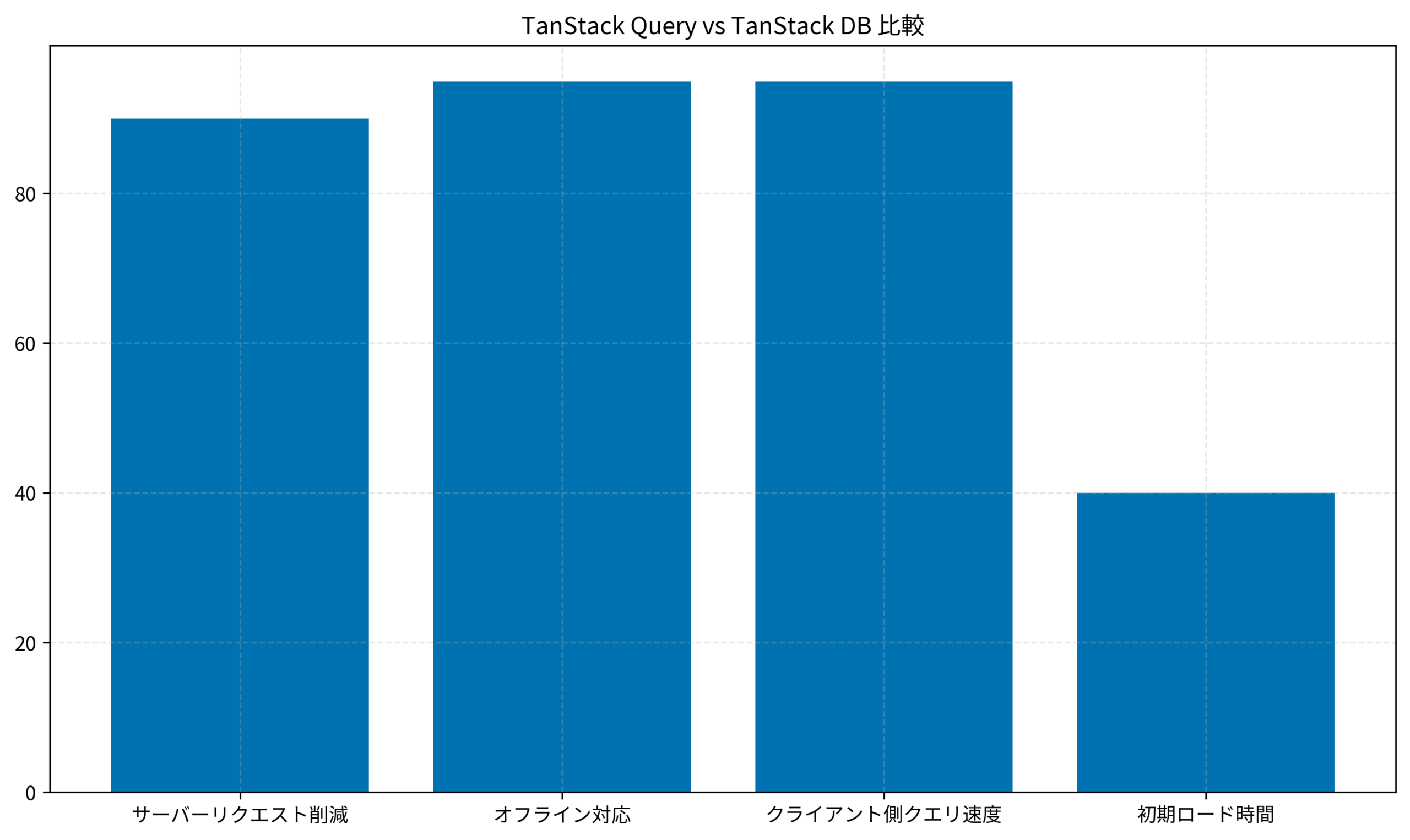
以下のグラフは、TanStack DBを導入した場合の各指標の改善度合いを示しています。サーバーリクエスト削減やオフライン対応、クライアント側クエリ速度では高いスコアを示す一方、初期ロード時間については従来手法より時間がかかる傾向があります。Pydantic v2のバリデーション設計の記事で触れた型安全なAPI設計と組み合わせることで、クライアントDBのスキーマ定義も堅牢になります。
IT女子 アラ美TanStack DBの基本的な使い方
TanStack DBの基本的な実装パターンを見ていきましょう。以下は、シンプルなToDoアプリでの利用例です。TypeScriptとの相性が非常によく、型安全なデータアクセスが実現できます。
セットアップとテーブル定義
まずはデータベースとテーブルの定義から始めます。スキーマはTypeScriptのinterfaceで表現できるため、型定義がそのまま利用できます。
import { createDB, createTable } from '@tanstack/db';
// データベースの作成
const db = createDB({
name: 'myapp-db',
});
// テーブル定義(スキーマを型で表現)
interface Todo {
id: string;
title: string;
completed: boolean;
createdAt: number;
}
const todosTable = createTable<Todo>(db, {
name: 'todos',
primaryKey: 'id',
});データの追加・更新・削除
CRUDオペレーションはシンプルなAPIで提供されています。リファクタリングの観点からも、データフェッチロジックがコンポーネントから分離され、テストしやすくなります。
// データの追加
await todosTable.insert({
id: crypto.randomUUID(),
title: '新しいタスク',
completed: false,
createdAt: Date.now(),
});
// データの更新
await todosTable.update({
id: 'existing-id',
completed: true,
});
// データの削除
await todosTable.delete('existing-id');クエリの実行
TanStack DBの特徴的な機能として、Reactコンポーネント内でリアクティブにデータを取得できます。
import { useQuery } from '@tanstack/db-react';
function TodoList() {
// フィルタリングやソートはクライアント側で高速に実行
const { data: todos } = useQuery(todosTable, {
where: { completed: false },
orderBy: { createdAt: 'desc' },
});
return (
<ul>
{todos.map(todo => (
<li key={todo.id}>{todo.title}</li>
))}
</ul>
);
}PythonのDB設計については、SQLModel入門で解説したPythonのORM設計と同様に、TypeScriptでも型安全なデータアクセスが実現できます。
IT女子 アラ美実装後の効果検証(ケーススタディ)
IT女子 アラ美実践的なTypeScript×React開発スキルでキャリアアップを実現
資格と仕事に強い!個人レッスンのプログラミングスクール【Winスクール】
実際のプロジェクトでTanStack DBを導入する際の判断ポイントを整理します。
村上さん(仮名・28歳・フロントエンドエンジニア)が担当するプロジェクトでは、管理画面に複数のフィルタリング条件とソート順、ページネーションが組み合わさったテーブルUIがありました。「早すぎる最適化」を避けつつ、ユーザー体験を改善する必要がありました。
状況(Before)
TanStack DB導入前の状況として、当初はTanStack Queryを使い、フィルタ条件が変わるたびにサーバーにリクエストを送っていました。フィルタ条件が12種類あり、1日あたり平均2,500回のフィルタ操作が行われていました。ユーザーが条件を頻繁に変更するため、1回の操作で200〜500msのレスポンス待ちが発生し、UXが低下しているという課題がありました。サーバー側のAPIエンドポイントへのリクエスト数は1日あたり約8,000件に達していました。
行動(Action)
データ量が約3,200件程度だったため、初回にすべてのデータを取得してクライアント側のDBに格納し、以降のフィルタリング・ソートはすべてクライアント側で実行するように変更しました。移行に要した工数は約1.5人日でした。
// 初回のデータ同期
async function syncData() {
const serverData = await fetch('/api/items').then(r => r.json());
await itemsTable.bulkInsert(serverData);
}
// 以降はクライアント側でクエリ
const { data } = useQuery(itemsTable, {
where: currentFilters,
orderBy: currentSort,
limit: pageSize,
offset: (page - 1) * pageSize,
});結果(After)
サーバーへのリクエスト数が1日あたり8,000件から800件(初回同期のみ)に削減され、約90%の負荷軽減を実現しました。フィルタ操作のレスポンスは50ms未満に改善し、ユーザーからの「操作が重い」という問い合わせが月間12件から0件になりました。
導入を見送るべきケース
一方で、TanStack DBを導入しない方がよいケースもあります。
- データ量が多すぎてクライアントに格納しきれない場合(目安として10万件以上)
- リアルタイムでサーバー側のデータが頻繁に更新される場合(株価データなど)
- シンプルな表示のみで、クライアント側での加工が不要な場合
- 初回読み込み時間がクリティカルな場合(すべてのデータを取得する必要があるため)
開発環境については、git worktreeとDocker Volumeスナップショットの記事で触れたように、開発環境の構成も含めてチーム全体でアーキテクチャ方針を共有することが重要です。
IT女子 アラ美よくある質問(FAQ)
Q. TanStack DBとTanStack Queryは併用できますか?
はい、併用できます。初回のデータ取得やサーバー同期にTanStack Queryを使い、クライアント側でのフィルタリング・ソートにTanStack DBを使うパターンが一般的です。両者は競合ではなく補完関係にあります。
Q. フロントエンドスキルはキャリアアップに有効ですか?
非常に有効です。React/TypeScriptに加えてクライアントDB設計の経験があるエンジニアは市場で高く評価されます。ハイクラスエンジニア転職エージェント3社比較で紹介しているエージェントに相談すると、フロントエンド専門の高条件ポジションに出会いやすくなります。
Q. TanStack DBはプロダクション環境で安定していますか?
TanStack DBはまだ比較的新しいライブラリのため、APIが安定するまではbreaking changeが発生する可能性があります。社内ツールやプロトタイプから導入を始め、安定性を確認してからプロダクション適用するアプローチが現実的です。
IT女子 アラ美おすすめ学習リソース・サービス
フロントエンド開発やTypeScript×React実装のスキルを体系的に学びたい方には、以下のサービスがおすすめです。
サーバー環境の選定や本番運用時のインフラ構成については、エンジニア向けXServer用途別比較ガイドも参考になります。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
TanStack DBは、クライアント側にリアルタイム同期可能なデータベースを持つという設計思想を実現するための新しいライブラリです。TanStack Queryとは競合ではなく、補完関係にあります。
この記事で伝えたかったポイントは以下の通りです。
- TanStack Queryは「サーバーが真実のソース」、TanStack DBは「クライアントが真実のソース」
- オフライン対応やクライアント側での複雑なクエリが必要な場合にTanStack DBが有効
- データ量やリアルタイム性の要件を見極めて、適材適所で選択することが重要
- 実際の導入事例では、サーバー負荷90%削減とレスポンス大幅改善を実現
まずは小規模なプロトタイプでTanStack DBを試してみて、チームでのフィードバックを集めてから本格導入を検討することをおすすめします。ローカルファーストアーキテクチャは、一度体験すると従来のフェッチ中心の設計に戻れなくなるほど快適です。
IT女子 アラ美