IT女子 アラ美
IT女子 アラ美Snowflake×AI実装の経験はハイクラス転職で高く評価されるわよ
自分らしく働けるエンジニア転職を目指すなら【strategy career】
お疲れ様です!IT業界で働くアライグマです!
「データ分析の民主化を進めたいけど、非エンジニアにSQLを教えるのは現実的じゃない」「BIツールだけでは複雑な分析要件に対応できない」。
こうした悩みを持つチームで、Cortex Analystを導入してSQL作成依頼が週20件から5件に減少した事例があります。この記事では、導入からセマンティックモデル設計、精度向上のベストプラクティスまでを実践的に解説します。
Snowflake Cortex Analystとは:Text-to-SQLを実現するAI機能
IT女子 アラ美AI・データサイエンスの実践スキルを個人レッスンで習得できるわよ
資格と仕事に強い!個人レッスンのプログラミングスクール【Winスクール】
Cortex Analystの基本概念
Snowflake Cortex Analystは、Snowflakeが提供するLLMベースのText-to-SQLエンジンです。ユーザーが自然言語で質問を入力すると、セマンティックモデルを参照してSQLクエリを自動生成し、結果を返します。
従来のBIツールと異なる点は、セマンティックレイヤーを明示的に定義できることです。これにより、「先月の売上」「アクティブユーザー数」といったビジネス用語を、データベースのテーブル・カラム構造に正確にマッピングできます。
セマンティックモデルの役割
セマンティックモデルは、YAMLまたはJSON形式で定義し、以下の要素を含みます。
テーブル定義:物理テーブル名とビジネス上の意味を記述します。
カラム定義:各カラムの型、説明、サンプル値を記述します。
リレーション定義:テーブル間の結合条件を記述します。
メトリクス定義:売上合計、平均単価などの集計ロジックを記述します。
データ構造の明示的な定義はLLMの精度向上に不可欠です。Pydantic v2のバリデーション設計でも同じ原則が解説されています。
IT女子 アラ美Text-to-SQLの精度を高める実装パターン
シノニム(同義語)の充実
セマンティックモデルで最も重要なのは、ビジネス用語のバリエーションを網羅することです。同じ概念でも、部署や担当者によって呼び方が異なるため、シノニムを充実させます。
dimensions:
- name: customer_id
synonyms:
- "顧客ID"
- "ユーザーID"
- "会員ID"
- "カスタマーID"
- "お客様番号"
data_type: NUMBERサンプル値の提供
LLMがカラムの内容を理解しやすくするため、代表的なサンプル値を記述します。
dimensions:
- name: product_category
synonyms: ["商品カテゴリ", "カテゴリ"]
data_type: VARCHAR
sample_values:
- "家電"
- "ファッション"
- "食品"
- "書籍"これにより、「家電の売上」といった質問に対して、LLMが正しいカラムとフィルタ条件を生成できます。
メトリクスの事前定義
頻繁に使われる集計ロジックは、メトリクスとして定義します。
measures:
- name: monthly_revenue
synonyms: ["月次売上", "月間売上"]
expr: "SUM(CASE WHEN DATE_TRUNC('month', order_date) = DATE_TRUNC('month', CURRENT_DATE()) THEN amount ELSE 0 END)"
data_type: NUMBER複雑なロジックの抽象化は運用の安全性を高めます。Feature Flagの設計と運用パターンでも同様のアプローチが解説されています。
IT女子 アラ美セマンティックモデルの設計と実装
基本的なセマンティックモデルの構造
セマンティックモデルは、YAML形式で記述します。以下は、ECサイトの売上分析を想定した基本例です。
name: sales_analytics
tables:
- name: orders
description: "注文テーブル"
base_table:
database: PROD_DB
schema: PUBLIC
table: ORDERS
dimensions:
- name: order_id
synonyms: ["注文ID", "オーダー番号"]
data_type: NUMBER
unique: true
- name: order_date
synonyms: ["注文日", "購入日"]
data_type: DATE
- name: customer_id
synonyms: ["顧客ID", "ユーザーID"]
data_type: NUMBER
measures:
- name: total_amount
synonyms: ["売上金額", "注文金額"]
data_type: NUMBER
aggregation: SUM
expr: amountケーススタディ:導入前後の変化
状況(Before)
データアナリストから「先月の商品カテゴリ別売上を出してほしい」という依頼が週に20件あり、エンジニアがSQLを書いて結果を返すまで平均2時間かかっていました。当時は「定型的な抽出作業に時間を取られる」という課題がありました。
行動(Action)
主要な分析パターン30種類を洗い出し、セマンティックモデルに定義しました。「商品カテゴリ」「売上」「先月」といったビジネス用語を物理テーブル構造にマッピングすることで、アナリストが理解できる形に整備しました。
結果(After)
アナリストが自然言語で質問を入力し、即座に結果を取得できるようになりました。SQL作成依頼が週5件に減少し、エンジニアの作業時間が週40時間から10時間に削減されました。
データアクセス層の抽象化は開発効率とユーザー体験の両方を向上させます。GraphQL導入判断ガイドでも同じ原則が解説されています。
IT女子 アラ美ケーススタディ:運用とトラブルシューティング
IT女子 アラ美佐藤さん(仮名・31歳・データエンジニア・経験6年)のチームで遭遇したよくある問題と解決策を紹介します。
よくある問題と解決策
質問の意図が正しく解釈されない場合、セマンティックモデルのシノニムを追加します。ユーザーからのフィードバックを収集し、実際に使われている用語をモデルに反映させることが重要です。
複雑な結合が生成されない場合、リレーション定義を見直します。特に、多対多の関係や中間テーブルを経由する結合は、明示的に定義する必要があります。
relationships:
- name: order_to_product
left_table: orders
left_column: product_id
right_table: products
right_column: product_id
join_type: INNERパフォーマンスが低下する場合、生成されたSQLを確認し、不要なサブクエリやカーテシアン積が発生していないかチェックします。必要に応じて、マテリアライズドビューを作成し、セマンティックモデルのベーステーブルとして指定します。
セキュリティとアクセス制御
Cortex Analystは、Snowflakeのロールベースアクセス制御(RBAC)と統合されています。ユーザーがアクセスできるテーブルのみがセマンティックモデルに含まれるよう、適切に権限を設定します。
データアクセス層のセキュリティ設計はシステム全体の信頼性に直結します。AWS設計ガイドラインのベストプラクティスでも詳しく解説されています。
IT女子 アラ美主要Text-to-SQLツールとの比較
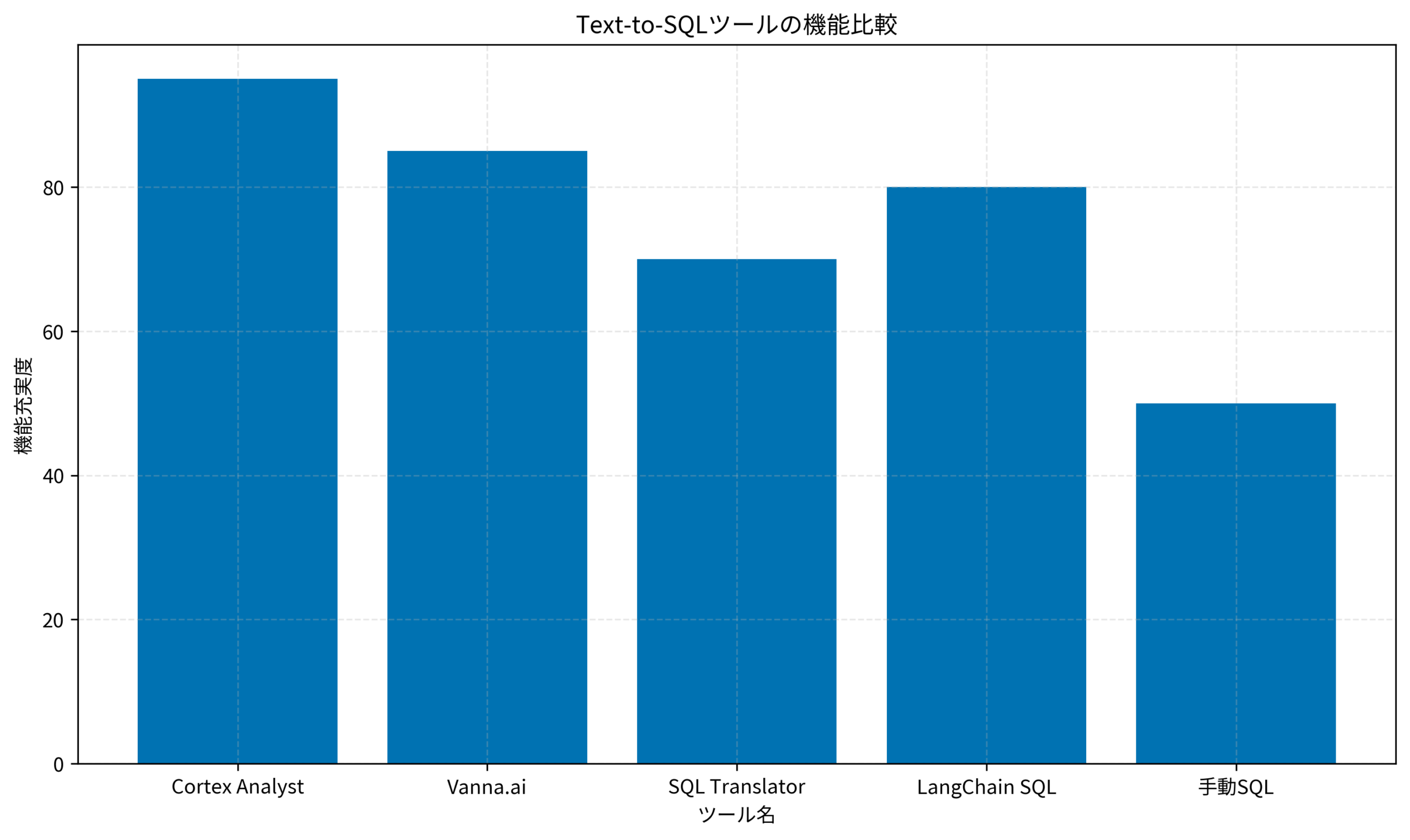
機能充実度の比較
Cortex Analystと他の主要Text-to-SQLツールを比較すると、それぞれに特徴があります。
Vanna.aiは、オープンソースのText-to-SQLフレームワークで、RAGベースのアプローチを採用しています。柔軟性が高い一方、セマンティックモデルの定義が必要で、初期設定に時間がかかります。
SQL Translatorは、シンプルな自然言語→SQL変換ツールですが、複雑なビジネスロジックやテーブル結合には対応しづらい傾向があります。
LangChain SQLは、LangChainエコシステムの一部として提供され、カスタマイズ性が高い反面、プロンプトエンジニアリングの知識が必要です。
Cortex Analystは、Snowflakeネイティブで動作し、セマンティックモデルによる高精度なSQL生成が可能です。特に、複数テーブルの結合や集計ロジックの事前定義に強みがあります。
ドメイン知識の明示的な定義はLLMの精度向上に不可欠です。CursorとOllamaで構築するローカルRAG環境でも同じ原則が解説されています。
佐藤さんは振り返ります。「セマンティックモデルにシノニムを追加したのが正解だった。ユーザーが実際に使う用語をモデルに反映するだけで精度が劇的に改善した」。
IT女子 アラ美よくある質問
Cortex Analystの利用に追加コストはかかりますか?
Snowflakeの従量課金モデルに含まれます。クエリ実行時のコンピュートコストは発生しますが、Cortex Analyst自体の追加ライセンス料は不要です。
セマンティックモデルの作成にどのくらいの工数がかかりますか?
テーブル数10程度の標準的なデータベースなら、2〜3日で基本的なモデルを構築できます。精度向上のためのチューニング(シノニム追加、検証クエリ定義)に追加で1〜2日が目安です。
生成されたSQLの精度はどのくらいですか?
適切にセマンティックモデルを設計すれば、単純な集計クエリで90%以上の精度が期待できます。複雑な結合やサブクエリが必要なケースでは70〜80%程度で、人間のレビューを組み合わせる運用が現実的です。
Snowflakeを活用したデータ分析スキルを習得すると、市場価値は大きく向上します。ハイクラスエンジニア転職エージェント3社比較で紹介しているエージェントを活用すると、専門性の高いスキルを持つエンジニア向けの高条件な求人に出会いやすくなります。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
Snowflake Cortex Analystは、セマンティックモデルを定義することで、自然言語からの高精度なSQL生成を実現します。ビジネス用語とデータベーススキーマを明示的に紐付けることで、非エンジニアでもデータ分析が可能になり、エンジニアの負担を大幅に削減できます。
最低限やっておきたいこと:
- 主要なテーブルとカラムをセマンティックモデルに定義する
- ビジネス用語のシノニムを充実させる
- 頻繁に使われる集計ロジックをメトリクスとして事前定義する
余力があれば試してほしい発展パターン:
- ユーザーからのフィードバックを収集し、セマンティックモデルを継続的に改善する
- マテリアライズドビューを活用してパフォーマンスを最適化する
- 複数のセマンティックモデルを用途別に作成し、ユーザーグループごとに提供する
IT女子 アラ美