
お疲れ様です!IT業界で働くアライグマです!
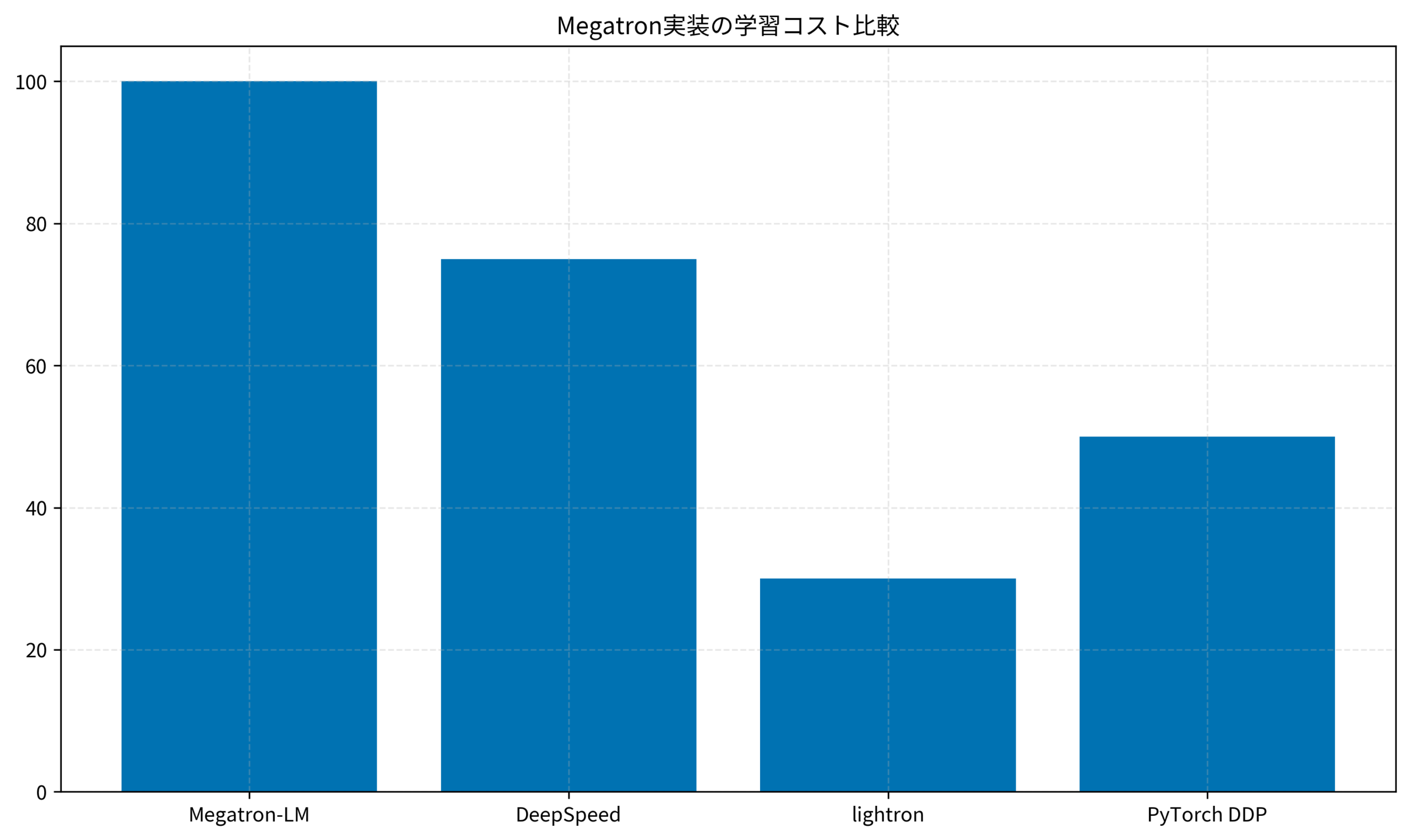
ある研究開発プロジェクトでは、lightronを使って研究用のLLM訓練環境を構築し、Megatron-LMと比較して環境構築時間を70%削減しました。この記事では、lightronの特徴から実装手順、Megatron-LMとの違いまでを実践的に解説します。
Megatron-LMの課題とlightronの位置づけ
ケーススタディ:Megatron-LM環境構築で3日間を費やしたチーム
状況(Before)
ある研究チームは、GPT-2規模のモデルを独自データセットで事前学習する計画を立てていました。Megatron-LMを選択しましたが、CUDA 11.8とPyTorch 2.0の互換性問題、Apex拡張のビルドエラー、分散学習の設定ミスなどで、環境構築に3日間を費やし、「学習環境の構築だけで疲弊してしまう」という課題がありました。
行動(Action)
lightronに切り替え、PyTorchとtransformersライブラリのみで環境を構築しました。依存関係がシンプルなため、30分でインストールが完了し、Data並列での学習を即座に開始できました。その後、段階的にTensor並列を追加し、最終的に4GPU環境でハイブリッド並列を実現しました。
結果(After)
環境構築時間を3日から30分に短縮し、学習開始までの時間を大幅に削減しました。コードの可読性が高いため、チームメンバー全員が分散学習の仕組みを理解でき、デバッグ効率も向上しました。
Megatron-LMの複雑性
Megatron-LMは、NVIDIAが開発した大規模言語モデル訓練のためのフレームワークです。Tensor並列、Pipeline並列、Data並列を組み合わせた高度な分散学習機能を提供しますが、以下の課題があります。
環境構築の複雑さ:Megatron-LMは、NVIDIA Apexやcuda-toolkitなど、多数の依存関係を持ちます。特定のCUDAバージョンやPyTorchバージョンとの互換性を確保する必要があり、初学者にとってハードルが高い状況です。
コードベースの巨大さ:Megatron-LMのコードベースは、本番運用を想定した最適化が多数含まれており、研究・学習目的で使うには過剰な機能が多く含まれています。
デバッグの困難さ:分散学習の複雑な実装により、エラーが発生した際の原因特定が難しく、学習コストが高くなります。
lightronの特徴
lightronは、Megatronの軽量実装として設計されたフレームワークです。研究・学習用途に特化し、以下の特徴を持ちます。
シンプルな依存関係:PyTorchとtransformersライブラリのみで動作し、複雑な環境構築が不要です。
読みやすいコード:Megatronの核となる機能(Tensor並列、Pipeline並列)を最小限の実装で再現しており、学習・研究目的での理解が容易です。
段階的な学習:基本的なData並列から始めて、Tensor並列、Pipeline並列へと段階的に機能を追加できる設計になっています。
Sonic-MoE実践ガイド:IO・Tile最適化でMixture of Expertsモデルを高速化するでも解説されていますが、大規模モデル訓練では最適化手法の理解が重要です。大規模言語モデルの基礎知識を身につけることで、lightronの設計思想がより深く理解できます。
 IT女子 アラ美
IT女子 アラ美lightronの環境構築と前提条件
必要な環境
lightronを動作させるには、以下の環境が必要です。
Python 3.8以上:lightronはPython 3.8以降で動作します。
PyTorch 1.13以上:分散学習機能を使用するため、PyTorch 1.13以降が推奨されます。
CUDA対応GPU:Tensor並列やPipeline並列を使用する場合、複数のGPUが必要です。最小構成では2GPU、推奨構成では4GPU以上を用意します。
transformersライブラリ:モデル定義やトークナイザーの利用に使用します。
インストール手順
lightronのインストールは、GitHubリポジトリからクローンして行います。
# リポジトリのクローン
git clone https://github.com/lwj2015/lightron.git
cd lightron
# 依存関係のインストール
pip install -r requirements.txt
# lightronのインストール
pip install -e .動作確認
インストール後、以下のコマンドで動作確認を行います。
# 単一GPUでの動作確認
python examples/pretrain_gpt.py \
--num-layers 12 \
--hidden-size 768 \
--num-attention-heads 12 \
--micro-batch-size 4 \
--global-batch-size 8 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 100 \
--lr 0.00015 \
--min-lr 1.0e-5 \
--lr-decay-style cosine \
--log-interval 10このコマンドは、GPT-2スタイルのモデルを小規模データセットで事前学習します。正常に動作すれば、学習ログが出力されます。
DeepSeek V3.2ローカルLLM実践ガイド:PjM視点で見る導入判断と運用設計でも解説されていますが、ローカルLLM環境の構築では依存関係の管理が重要です。Python環境管理の知識を活用することで、トラブルシューティングがスムーズになります。
IT女子 アラ美Data並列による基本的な分散学習
Data並列の仕組み
Data並列は、最もシンプルな分散学習手法です。各GPUが同じモデルのコピーを持ち、異なるデータバッチを処理します。勾配を集約してモデルを更新することで、学習を高速化します。
lightronでは、PyTorchのDistributedDataParallel(DDP)を使用してData並列を実装します。
実装例
以下は、lightronでData並列を使用する基本的な実装例です。
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from lightron.model import GPTModel
from lightron.training import Trainer
# 分散環境の初期化
dist.init_process_group(backend='nccl')
local_rank = int(os.environ['LOCAL_RANK'])
torch.cuda.set_device(local_rank)
# モデルの定義
model = GPTModel(
num_layers=12,
hidden_size=768,
num_attention_heads=12,
vocab_size=50257
).cuda(local_rank)
# DDPでラップ
model = DDP(model, device_ids=[local_rank])
# トレーナーの設定
trainer = Trainer(
model=model,
optimizer=torch.optim.AdamW(model.parameters(), lr=1e-4),
train_dataloader=train_loader,
max_steps=10000
)
# 学習実行
trainer.train()実行コマンド
Data並列での学習は、torchrunコマンドで実行します。
# 4GPU環境での実行
torchrun --nproc_per_node=4 train_data_parallel.pyこのコマンドは、4つのGPUでData並列学習を実行します。各GPUが独立してバッチを処理し、勾配を集約してモデルを更新します。
git worktreeとDocker Volumeスナップショットで実現するAIエージェント並行開発環境でも解説されていますが、並行処理環境の構築では環境変数の管理が重要です。データ基盤の知識を活用することで、分散学習の設計がより深く理解できます。
IT女子 アラ美Tensor並列とPipeline並列の実装
Tensor並列の仕組み
Tensor並列は、モデルの各層を複数のGPUに分割する手法です。Attention層やFeed-Forward層の重み行列を列方向に分割し、各GPUが部分的な計算を担当します。
lightronでは、Megatronの実装を簡略化したTensor並列を提供します。
from lightron.model import GPTModelTP
from lightron.parallel import TensorParallelGroup
# Tensor並列グループの初期化
tp_group = TensorParallelGroup(world_size=2)
# Tensor並列対応モデル
model = GPTModelTP(
num_layers=12,
hidden_size=768,
num_attention_heads=12,
vocab_size=50257,
tensor_parallel_group=tp_group
).cuda()Pipeline並列の実装
Pipeline並列は、モデルの層を複数のGPUに分割し、各GPUが異なる層を担当する手法です。マイクロバッチを使用して、各GPUが並行して異なるバッチを処理します。
from lightron.model import GPTModelPP
from lightron.parallel import PipelineParallelGroup
# Pipeline並列グループの初期化
pp_group = PipelineParallelGroup(world_size=4)
# Pipeline並列対応モデル
model = GPTModelPP(
num_layers=24,
hidden_size=1024,
num_attention_heads=16,
vocab_size=50257,
pipeline_parallel_group=pp_group,
num_stages=4
).cuda()ハイブリッド並列
lightronは、Data並列、Tensor並列、Pipeline並列を組み合わせたハイブリッド並列もサポートします。例えば、8GPU環境で2-way Tensor並列と2-way Pipeline並列と2-way Data並列を組み合わせた構成が可能です。
lspmuxでrust-analyzerの起動を高速化する:大規模Rustプロジェクトの開発効率改善でも解説されていますが、大規模プロジェクトでは並列化戦略の設計が重要です。アーキテクチャ設計の知識を活用することで、最適な並列構成を選択できます。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
lightronは、Megatron-LMの軽量実装として、研究・学習用途に最適化されたフレームワークです。以下の3つのポイントを押さえることで、効率的にLLM訓練環境を構築できます。
シンプルな環境構築:PyTorchとtransformersライブラリのみで動作し、複雑な依存関係の管理が不要です。
段階的な学習:Data並列から始めて、Tensor並列、Pipeline並列へと段階的に機能を追加できる設計になっています。
読みやすいコード:Megatronの核となる機能を最小限の実装で再現しており、学習・研究目的での理解が容易です。
lightronを使うことで、Megatron-LMの複雑さに悩まされることなく、大規模言語モデルの分散学習を実践的に学べます。まずはData並列での学習から始めて、徐々にTensor並列やPipeline並列を試してみてください。
IT女子 アラ美








