お疲れ様です!IT業界で働くアライグマです!
Pydanticは「境界」に置くのがちょうどいい——これが、私がPydantic v2を使い込んで得た結論です。
「バリデーションをどこに書くべきか」「ドメインロジックとの境界をどう設計するか」という悩みは、FastAPIやLangChainを使うプロジェクトで必ず出てきます。Pydanticを内部のあらゆる場所で使うと、かえってコードが複雑になることもあります。
- Pydantic v2の基本概念と、v1からの主要な変更点
- 「境界」にPydanticを配置する設計パターン
- FastAPIでの入出力バリデーション実装
- LangChainでのStructured Output活用
- パフォーマンス最適化とベストプラクティス
この記事では、Pydantic v2を使った型安全なバリデーション設計を、FastAPIとLLMアプリケーションの実装パターンとともに解説します。
Pydantic v2の基本と「境界」設計の考え方
Pydanticは、Pythonのデータバリデーションライブラリです。v2では内部がRustで書き直され、パフォーマンスが大幅に向上しました。しかし、重要なのは「どこで使うか」という設計判断です。
Pydanticが得意な領域
Pydanticは以下の場面で威力を発揮します。
- 外部からの入力検証:APIリクエスト、設定ファイル、環境変数
- 外部への出力整形:APIレスポンス、シリアライズ
- LLMの出力パース:Structured Output、Function Calling
一方、ドメインロジックの内部でPydanticモデルを多用すると、以下の問題が起きがちです。
- バリデーションのオーバーヘッドが積み重なる
- ドメインモデルとPydanticモデルの二重管理
- テストが複雑になる
ドメインモデリング実践ガイドでも触れましたが、ドメインロジックは純粋なPythonクラスで表現し、Pydanticは「境界」に配置するのが効果的です。Clean Architecture 達人に学ぶソフトウェアの構造と設計で紹介されているクリーンアーキテクチャの考え方を適用すると、この境界設計がより明確になります。

【ケーススタディ】バリデーション設計の改善で保守性が向上
私のチームで経験した事例を紹介します。
状況(Before):Pydanticモデルが散在して保守困難
私がPjMとして参画したFastAPIプロジェクト(チーム5名、API数約50本)では、Pydanticモデルを以下のように使っていました。
- APIリクエスト/レスポンス用のモデル:12個
- ドメインロジック内部のデータ構造:5個
- DBアクセス層のデータ構造:3個
結果として、同じような構造のモデルが20個以上存在し、1つのフィールドを変更するだけで平均3ファイルを修正する必要がありました。また、Pydantic v1からv2への移行時に、全モデルの修正が必要になり、移行に2週間(工数約40時間)かかりました。
行動(Action):境界にのみPydanticを配置
以下のように設計を見直しました。
# 境界層:APIリクエスト/レスポンス
from pydantic import BaseModel, Field
class CreateUserRequest(BaseModel):
"""API入力の境界"""
name: str = Field(..., min_length=1, max_length=100)
email: str = Field(..., pattern=r"^[\w\.-]+@[\w\.-]+\.\w+$")
class UserResponse(BaseModel):
"""API出力の境界"""
id: int
name: str
email: str
# ドメイン層:純粋なPythonクラス
from dataclasses import dataclass
@dataclass
class User:
"""ドメインモデル(Pydantic不使用)"""
id: int
name: str
email: str
def change_email(self, new_email: str) -> "User":
# ドメインロジックはここに
return User(id=self.id, name=self.name, email=new_email)結果(After):モデル数が半減、移行コストも削減
Pydanticモデルを境界層に限定した結果、モデル数は20個から8個に減少。ドメインロジックの変更がAPIモデルに影響しなくなり、保守性が大幅に向上しました。
SQLModel入門でも紹介しましたが、SQLModelを使う場合も同様に、DB層とAPI層の境界を意識した設計が重要です。ソフトウェアアーキテクチャの基礎で解説されている「関心の分離」の原則がここでも活きてきます。
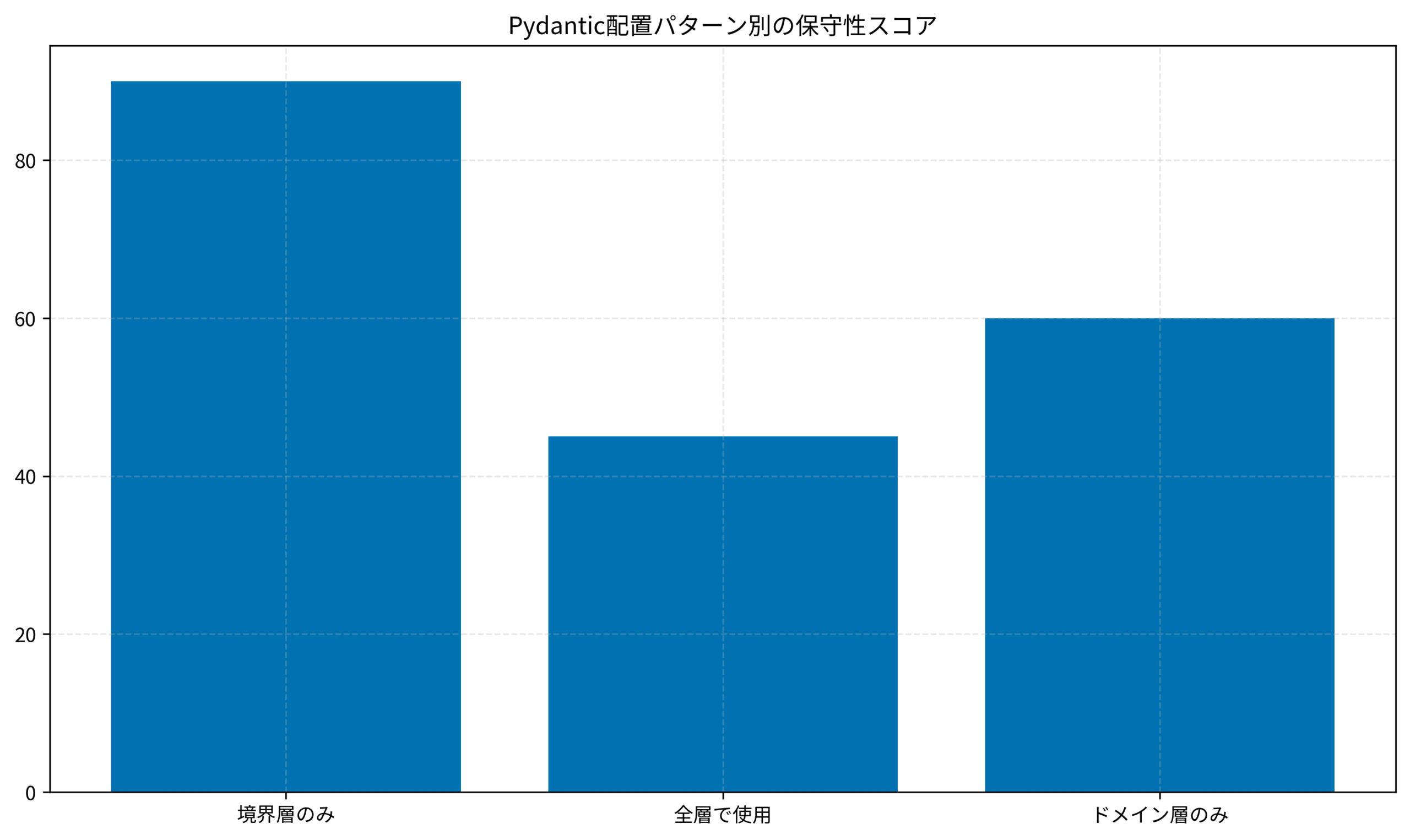
以下のグラフは、Pydanticの配置パターン別に保守性を評価したものです。境界層のみに配置するパターンが最も高いスコアを示しています。
FastAPIでの入出力バリデーション実装
FastAPIとPydantic v2を組み合わせた、実践的なバリデーション実装パターンを紹介します。
リクエストバリデーションの実装
Pydantic v2では、field_validatorとmodel_validatorを使って柔軟なバリデーションを実装できます。
from pydantic import BaseModel, Field, field_validator, model_validator
from typing import Optional
class CreateArticleRequest(BaseModel):
title: str = Field(..., min_length=1, max_length=200)
content: str = Field(..., min_length=10)
tags: list[str] = Field(default_factory=list, max_length=10)
published: bool = False
@field_validator("tags")
@classmethod
def validate_tags(cls, v: list[str]) -> list[str]:
# 重複を除去し、空文字を除外
return list(dict.fromkeys(tag.strip() for tag in v if tag.strip()))
@model_validator(mode="after")
def validate_published_content(self) -> "CreateArticleRequest":
# 公開記事は最低100文字必要
if self.published and len(self.content) < 100:
raise ValueError("公開記事は100文字以上必要です")
return selfレスポンスのシリアライズ設定
v2ではmodel_configでシリアライズの挙動を細かく制御できます。
from pydantic import BaseModel, ConfigDict
from datetime import datetime
class ArticleResponse(BaseModel):
model_config = ConfigDict(
from_attributes=True, # ORMモデルからの変換を許可
json_encoders={datetime: lambda v: v.isoformat()},
)
id: int
title: str
content: str
created_at: datetime
updated_at: Optional[datetime] = NoneFeature Flagの設計と運用で紹介した段階的リリースの考え方は、APIのバリデーションルール変更時にも応用できます。Python自動化の書籍で紹介されているPythonのベストプラクティスに従い、型ヒントを活用しています。

LangChainでのStructured Output活用
LLMアプリケーションでは、Pydanticを使ったStructured Outputが非常に有効です。LLMの出力を型安全に扱えるようになります。
基本的なStructured Output
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
class ExtractedEntity(BaseModel):
"""LLM出力の構造化モデル"""
name: str = Field(description="エンティティの名前")
category: str = Field(description="カテゴリ(人物/組織/場所)")
confidence: float = Field(ge=0.0, le=1.0, description="信頼度スコア")
class ExtractionResult(BaseModel):
"""抽出結果全体"""
entities: list[ExtractedEntity] = Field(default_factory=list)
summary: str = Field(description="テキストの要約")
# LLMにStructured Outputを指定
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm = llm.with_structured_output(ExtractionResult)
prompt = ChatPromptTemplate.from_messages([
("system", "テキストからエンティティを抽出してください。"),
("human", "{text}")
])
chain = prompt | structured_llm
result: ExtractionResult = chain.invoke({"text": "OpenAIのサム・アルトマンCEOが..."})バリデーションエラーのハンドリング
LLMの出力は必ずしも期待通りではないため、エラーハンドリングが重要です。
from pydantic import ValidationError
from typing import Optional
def safe_extract(text: str) -> Optional[ExtractionResult]:
try:
return chain.invoke({"text": text})
except ValidationError as e:
# バリデーションエラーをログに記録
print(f"LLM出力のバリデーションエラー: {e}")
return None
except Exception as e:
print(f"予期しないエラー: {e}")
return NoneLangChainとLangGraphでAIエージェントを構築する実装ガイドでも紹介しましたが、エージェント開発ではStructured Outputが特に重要です。ChatGPT/LangChainによるチャットシステム構築実践入門で解説されているLLMアプリケーションの設計パターンを参考にしています。

まとめ
Pydantic v2は、「境界」に配置することで最大の効果を発揮します。
- Pydanticは外部との境界(API入出力、LLM出力、設定ファイル)に配置する
- ドメインロジック内部は純粋なPythonクラス(dataclassなど)で表現する
- FastAPIでは
field_validatorとmodel_validatorで柔軟なバリデーションを実装 - LangChainのStructured OutputでLLM出力を型安全に扱う
- バリデーションエラーのハンドリングを忘れずに実装する
Pydanticを「どこで使うか」を意識することで、保守性の高いコードベースを実現できます。まずは既存プロジェクトのPydanticモデルを見直し、境界層に集約することから始めてみてください。









