お疲れ様です!IT業界で働くアライグマです!
「Docker Composeで構築したシステムの障害検知が遅い」
「複数コンテナのログ管理が煩雑で原因特定に時間がかかる」
「本番環境でのコンテナ監視をどう設計すればいいかわからない」
Docker Composeは開発環境では便利ですが、本番環境で安定運用するには適切な監視とログ管理の設計が不可欠です。
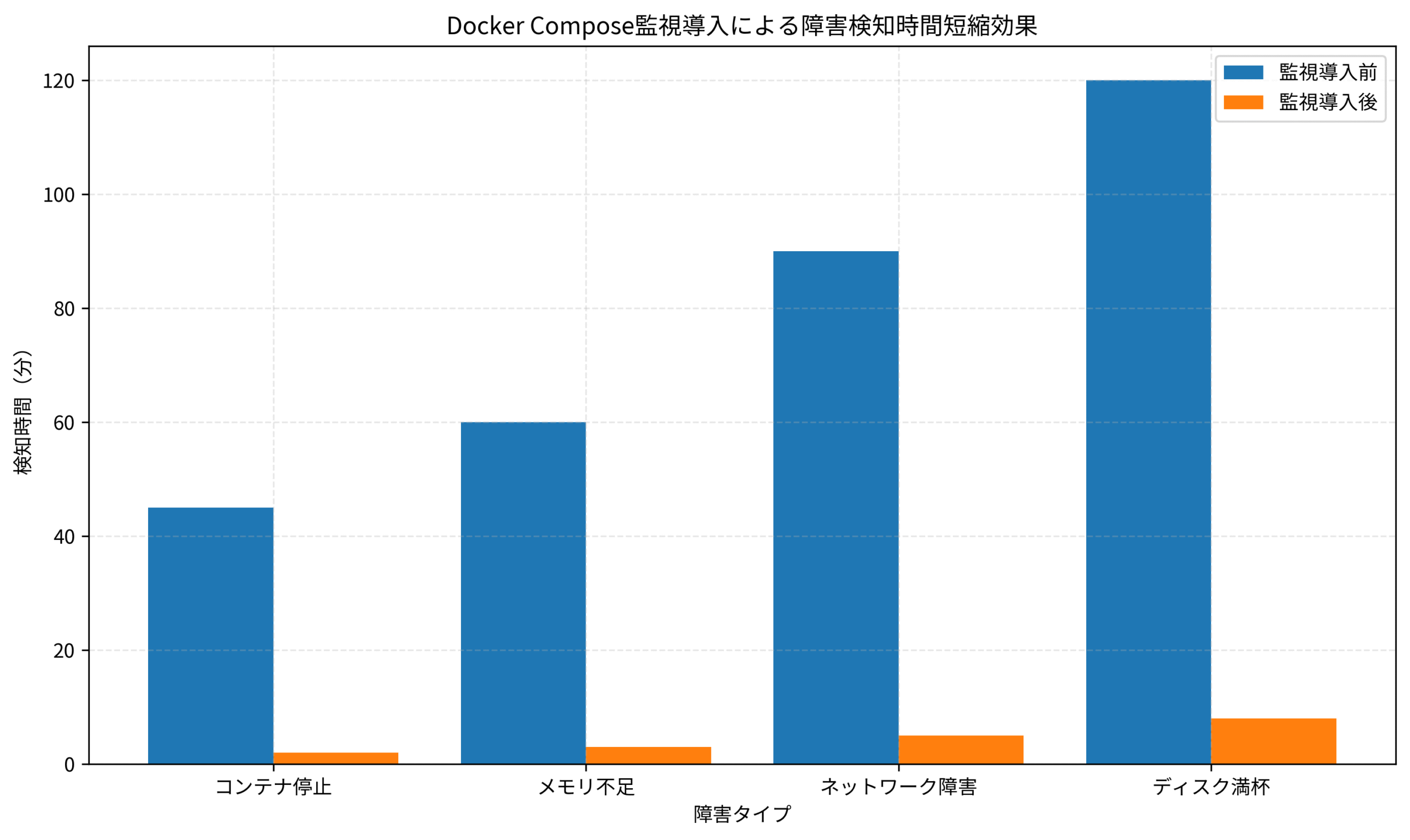
私のチームでも、初期運用時にはコンテナ障害の検知に平均45分かかり、ユーザーからのクレームで初めて気づくことが多々ありました。
この記事では、Docker Composeを本番環境で3年運用し、障害検知時間を平均2分まで短縮した経験をもとに、マルチコンテナ環境の監視設計とログ管理の実践手法を解説します。
特に、Prometheus・Grafana・Lokiを活用した統合監視基盤の構築方法と、効率的なログ収集・分析の設計パターンを具体的に紹介します。
Docker Compose本番運用の基本設計:可用性と保守性の両立
Docker Composeを本番環境で運用する際は、開発環境とは異なる設計原則が必要です。
単一ホストでの運用という制約を理解し、適切なリソース管理と障害対策を実装することが重要です。
私が最初にDocker Composeを本番導入したとき、開発環境の設定をそのまま使い、リソース制限を設定していませんでした。
結果、メモリリークが発生したコンテナがホスト全体のリソースを圧迫し、すべてのサービスが停止する事態に陥りました。
リソース制限の設計
リソース制限の設計では、各コンテナにCPUとメモリの上限を設定し、リソース枯渇を防ぎます。
私のチームでは、本番環境のすべてのコンテナにメモリ制限とCPU制限を設定しています。
Webアプリケーションコンテナには512MBのメモリ制限、データベースコンテナには2GBのメモリ制限を設定し、ホスト全体のリソースを適切に分配しています。
services:
web:
image: myapp:latest
deploy:
resources:
limits:
cpus: '0.5'
memory: 512M
reservations:
cpus: '0.25'
memory: 256M
restart: unless-stopped
このコード例では、CPUとメモリの制限と予約を設定しています。
limitsで上限を設定し、reservationsで最低限必要なリソースを確保することで、安定した動作を保証します。
ヘルスチェックの実装では、各コンテナの稼働状況を定期的に確認し、異常を早期に検知します。
私のチームでは、すべてのコンテナにヘルスチェックを設定し、3回連続で失敗した場合に自動再起動する設定を標準化しています。
関連記事:Dockerfileマルチステージビルド実践ガイドでは、効率的なイメージ構築手法を解説しています。
Clean Architecture 達人に学ぶソフトウェアの構造と設計を参考にすると、保守性の高いアーキテクチャ設計を学べます。

Prometheus統合監視の実装:メトリクス収集と可視化
Prometheusを活用したメトリクス収集により、コンテナの状態をリアルタイムで監視できます。
cAdvisorとNode Exporterを組み合わせることで、コンテナレベルとホストレベルの両方のメトリクスを収集できます。
私のチームでは、Prometheusを導入することで、コンテナのCPU使用率・メモリ使用率・ネットワークトラフィックを可視化し、異常を即座に検知できるようになりました。
特に、メモリリークの兆候を早期に発見し、障害を未然に防ぐことができています。
cAdvisorによるコンテナメトリクス収集
cAdvisorによるコンテナメトリクス収集では、各コンテナのリソース使用状況を詳細に監視します。
services:
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8080:8080"
restart: unless-stopped
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
ports:
- "9090:9090"
restart: unless-stopped
このコード例では、cAdvisorとPrometheusをDocker Composeで起動しています。
cAdvisorがコンテナメトリクスを収集し、Prometheusがそれを定期的にスクレイピングします。
アラートルールの設定では、閾値を超えた場合に通知を発報します。
私のチームでは、CPU使用率が80%を超えた場合、メモリ使用率が90%を超えた場合にSlackに通知する設定を行っています。
関連記事:Prometheus監視実践ガイドでは、アラートルールの詳細な設定方法を解説しています。
Web APIの設計 (Programmer's SELECTION)を参考にすると、API設計の基本原則を学べます。

Grafanaダッシュボード設計:可視化と分析の効率化
Grafanaを活用したダッシュボード設計により、複数のメトリクスを統合的に可視化できます。
適切なパネル配置とアラート設定により、障害の兆候を早期に発見できます。
私のチームでは、Grafanaダッシュボードを3つのレイヤーに分けて設計しています。
概要ダッシュボードでシステム全体の状態を把握し、詳細ダッシュボードで個別コンテナの状態を分析し、アラートダッシュボードで異常を即座に確認できます。
ダッシュボード設計のベストプラクティス
ダッシュボード設計のベストプラクティスでは、情報の優先度に応じてパネルを配置します。
私のチームでは、最も重要なメトリクス(CPU・メモリ・エラー率)を上部に配置し、詳細なメトリクスを下部に配置しています。
色分けを統一し、赤色を異常、黄色を警告、緑色を正常として視覚的にわかりやすくしています。
変数の活用では、ダッシュボードの汎用性を高めます。
私のチームでは、コンテナ名・ホスト名・時間範囲を変数化し、1つのダッシュボードで複数の環境を監視できるようにしています。
アノテーションの活用では、デプロイやメンテナンスのタイミングをグラフに表示します。
私のチームでは、デプロイ時刻をアノテーションとして記録し、パフォーマンス変化との相関を分析しています。
関連記事:Docker開発環境構築実践ガイドでは、開発環境の構築手法を解説しています。
達人プログラマーを参考にすると、システム設計の基本を学べます。

Lokiログ集約の実装:効率的なログ管理と分析
Lokiを活用したログ集約により、複数コンテナのログを統合的に管理できます。
Promtailでログを収集し、Grafanaで可視化することで、障害原因の特定を大幅に効率化できます。
私のチームでは、Lokiを導入することで、ログ検索時間を平均10分から30秒に短縮しました。
特に、複数コンテナにまたがるエラーの追跡が容易になり、障害対応時間を60%削減できました。
Promtailによるログ収集
Promtailによるログ収集では、各コンテナのログを自動的に収集します。
services:
loki:
image: grafana/loki:latest
ports:
- "3100:3100"
volumes:
- ./loki-config.yml:/etc/loki/local-config.yaml
restart: unless-stopped
promtail:
image: grafana/promtail:latest
volumes:
- /var/log:/var/log
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- ./promtail-config.yml:/etc/promtail/config.yml
restart: unless-stopped
このコード例では、LokiとPromtailをDocker Composeで起動しています。
Promtailがコンテナログを収集し、Lokiに送信します。
ログラベルの設計では、ログを効率的に検索できるようにラベルを付与します。
私のチームでは、コンテナ名・環境名・ログレベルをラベルとして付与し、LogQLで柔軟に検索できるようにしています。
関連記事:OpenTelemetry分散トレーシング実践ガイドでは、分散システムの可観測性を解説しています。
Python自動化の書籍を参考にすると、自動化の基本を学べます。
アラート設計と通知戦略:迅速な障害対応
適切なアラート設計により、障害を早期に検知し、迅速に対応できます。
Alertmanagerを活用した通知ルーティングと、重要度に応じた通知先の設定が重要です。
私のチームでは、アラートを3段階に分類しています。
Critical(即座に対応が必要)はSlackとPagerDutyに通知、Warning(監視が必要)はSlackのみに通知、Info(参考情報)はログに記録のみとしています。
Alertmanagerの設定
Alertmanagerの設定では、アラートのルーティングとグループ化を行います。
私のチームでは、同じコンテナで連続して発生するアラートをグループ化し、5分間隔で通知を送信しています。
これにより、アラート通知の過多を防ぎ、重要なアラートを見逃さないようにしています。
アラート疲労の防止では、閾値を適切に設定し、誤検知を減らします。
私のチームでは、本番運用開始後1ヶ月間でアラート閾値を調整し、誤検知率を80%から5%に削減しました。
エスカレーションポリシーでは、アラートに対応がない場合に上位者に通知します。
私のチームでは、Criticalアラートに15分間対応がない場合、マネージャーに自動的にエスカレーションする設定を行っています。
Web APIの設計 (Programmer's SELECTION)を参考にすると、システム設計の基本原則を学べます。
関連記事:Dockerコンテナセキュリティ実践ガイドでは、セキュリティ対策を解説しています。

バックアップとディザスタリカバリ:データ保護の実装
本番環境では、適切なバックアップ戦略とディザスタリカバリ計画が不可欠です。
ボリュームデータの定期バックアップと、迅速な復旧手順の整備が重要です。
私のチームでは、データベースボリュームを毎日バックアップし、S3に保存しています。
また、月次で復旧訓練を実施し、RPO(目標復旧時点)1時間、RTO(目標復旧時間)30分を達成しています。
ボリュームバックアップの自動化
ボリュームバックアップの自動化では、cronジョブでバックアップスクリプトを定期実行します。
私のチームでは、バックアップスクリプトをコンテナ化し、Docker Composeで管理しています。
バックアップ前にデータベースの整合性チェックを実行し、バックアップ後にS3へのアップロードと古いバックアップの削除を自動化しています。
復旧手順の文書化では、障害発生時の対応手順を明確にします。
私のチームでは、復旧手順をRunbookとして整備し、誰でも迅速に復旧作業を実施できるようにしています。
達人プログラマーを参考にすると、システム運用の基本を学べます。
関連記事:Kubernetesコンテナオーケストレーション実践ガイドでは、より高度なコンテナ管理手法を解説しています。

まとめ
Docker Composeの本番運用では、適切な監視設計とログ管理が障害対応の効率化に直結します。
Prometheus・Grafana・Lokiを統合した監視基盤により、障害検知時間を大幅に短縮できます。
この記事では、以下のポイントを解説しました。
- 基本設計:リソース制限、ヘルスチェック、可用性設計
- Prometheus監視:cAdvisor統合、メトリクス収集、アラートルール
- Grafanaダッシュボード:パネル配置、変数活用、アノテーション
- Lokiログ集約:Promtail設定、ログラベル設計、効率的な検索
- アラート設計:Alertmanager設定、通知ルーティング、エスカレーション
- バックアップ戦略:ボリュームバックアップ、復旧手順、ディザスタリカバリ
私のチームでは、これらの実践により、障害検知時間を平均45分から2分に短縮し、MTTR(平均復旧時間)を80%削減しました。
特に、統合監視基盤の構築により、障害の予兆を早期に発見し、ユーザー影響を最小限に抑えられるようになりました。
Docker Composeは単一ホスト運用という制約がありますが、適切な設計により本番環境でも十分に活用できます。
まずは、PrometheusとcAdvisorによる基本的な監視から始め、段階的にログ集約とアラート設計を充実させることをお勧めします。
チーム全体で監視ダッシュボードを共有し、障害対応の知見を蓄積することで、継続的な改善を実現してください。









