お疲れ様です!IT業界で働くアライグマです!
「技術書を読むのに時間がかかりすぎる」「難解な専門書で何度も読み返している」と感じたことはありませんか?
従来の読書では、理解できない箇所で立ち止まり、何度も読み返すことで多くの時間を費やしていました。しかし、Karpathy氏が開発したReader3を使えば、LLMと対話しながら読書を進め、理解度を大幅に向上させることができます。
私自身、年間50冊以上の技術書を読むプロジェクトマネージャーとして、「複雑なアーキテクチャ本で理解が進まない」「最新技術の論文が読み切れない」という課題に直面してきました。Reader3の導入により、LLMに質問しながら読書を進めることで、理解速度が従来の2〜3倍に向上しました。
この記事では、Reader3の基本機能から実践的な活用方法、効率的な読書戦略、チーム活用まで、技術書の理解を加速させる具体的な手法を解説します。
Reader3とは:Karpathy式LLM読書革命の全体像
Reader3は、LLMと対話しながら書籍を読み進めるPythonツールです。Andrej Karpathy氏(元Tesla AI担当、OpenAI共同創設者)が開発し、GitHubで1,300以上のスターを獲得しています。
Reader3の3つの特徴
対話型読書により、テキストの任意の箇所でLLMに質問できます。理解できない概念や用語をその場で確認し、読書を中断せずに進められます。
コンテキスト保持機能を搭載しており、書籍全体の文脈を保持しながら質問に回答します。前の章の内容を踏まえた質問にも対応できます。
シンプルな設計で、わずか数百行のPythonコードで実装されています。カスタマイズや機能拡張が容易で、自分の読書スタイルに合わせた調整が可能です。
従来の読書との違い
従来の読書では、理解できない箇所で立ち止まり、別の資料を探したり、後で調べる予定のメモを取ったりしていました。これにより読書のリズムが崩れ、全体の理解に時間がかかります。
Reader3では、その場でLLMに質問し、即座に回答を得られます:
- 疑問: 理解できない概念や用語に遭遇
- 質問: LLMに直接質問
- 回答: 文脈を踏まえた説明を取得
- 継続: 理解を深めてすぐに読書を再開
このサイクルにより、読書の流れを維持しながら深い理解を獲得できます。
Reader3が適している用途
- 技術書: 複雑なアーキテクチャやアルゴリズムの解説書
- 学術論文: 最新研究の理論や実験結果の理解
- 専門書: 新しい分野の基礎知識の習得
- 英語文献: 技術英語の理解支援と翻訳
私の経験では、特に「数式が多い本」や「前提知識が豊富に必要な専門書」で威力を発揮します。AIを活用した学習手法については、AIエージェント開発の実践ガイド:自律型タスク処理で業務効率を3倍にする設計手法で詳しく解説しています。LLMアプリケーション開発の実践的な手法については、ChatGPT/LangChainによるチャットシステム構築実践入門 が詳しく解説しています。

セットアップ:Python環境とReader3の導入手順
Reader3をローカル環境で動作させるための具体的な手順を解説します。
前提条件
- Python 3.8以上
- OpenAI APIキー(GPT-4またはGPT-3.5使用時)
- Git
Step 1: Reader3のインストール
GitHubからReader3をクローンし、必要なパッケージをインストールします。
// Reader3のクローン
git clone https://github.com/karpathy/reader3.git
cd reader3
// 依存パッケージのインストール
pip install openai anthropic私のプロジェクトでは、仮想環境を作成してから依存関係をインストールしました。これにより、システム全体のPython環境を汚さずに管理できます。
Step 2: APIキーの設定
OpenAI APIキーを環境変数に設定します。
// 環境変数にAPIキーを設定
export OPENAI_API_KEY="your-api-key-here"
// または~/.bashrcや~/.zshrcに追記
echo 'export OPENAI_API_KEY="your-api-key-here"' >> ~/.bashrc
source ~/.bashrcセキュリティのため、APIキーは環境変数で管理し、コードに直接埋め込まないことが重要です。
Step 3: 動作確認
サンプルテキストでReader3の動作を確認します。
// reader3.pyの基本的な使用例
python reader3.py sample.txt
// または対話モードで起動
python -i reader3.py sample.txtこのコマンドを実行すると、対話モードでLLMに質問できる状態になります。
私の環境では、初回セットアップに約10分、APIキーの設定と動作確認に5分程度かかりました。Python環境のセットアップについては、CursorとMCP統合実践:ローカルLLM開発環境を10倍効率化するツール連携設計も参考になります。プロンプト最適化の実践手法については、プロンプトエンジニアリングの教科書 で体系的に学べます。

基本的な使い方:技術書をLLMと一緒に読む実践
Reader3の基本的な操作方法と効果的な質問の仕方を解説します。
テキストの読み込み
Reader3は、プレーンテキスト形式の書籍を読み込みます。
from reader3 import Reader
// 書籍ファイルを読み込み
reader = Reader("path/to/your/book.txt")
// 特定の章から開始
reader.start_from_chapter(3)PDFやEPUB形式の書籍は、事前にテキストに変換する必要があります。
質問の基本パターン
Reader3での質問には、いくつかの効果的なパターンがあります。
まず、概念の説明を求める質問です。理解できない専門用語や概念について質問します。
質問例:
「この章で説明されているガベージコレクションのマーク・アンド・スイープアルゴリズムについて、もう少し詳しく説明してください」次に、具体例を求める質問です。抽象的な説明を理解するために、実例を尋ねます。
質問例:
「この設計パターンを実際のWebアプリケーション開発でどのように適用できるか、具体例を教えてください」最後に、関連知識との比較を求めます。既知の概念と比較することで理解を深めます。
質問例:
「この章で説明されているReactのHooksは、従来のクラスコンポーネントとどう違いますか?」私の経験では、質問の具体性が高いほど、有用な回答が得られやすいです。
コンテキストの管理
Reader3は書籍全体のコンテキストを保持しますが、効果的に活用するためのコツがあります。
// 現在の読書位置を確認
current_position = reader.get_position()
print(f"Current chapter: {current_position['chapter']}")
// 前の章の内容を参照した質問
reader.ask("第3章で説明されたデザインパターンと、現在の章の内容はどう関連していますか?")章をまたいだ質問をすることで、書籍全体の理解を深められます。複雑な技術書の理解には、Python非同期プログラミング実践ガイド:asyncioで処理速度を3倍向上させる実装手法のような実践的なリソースも活用できます。効果的な質問設計については、プロンプトエンジニアリングの教科書 で詳しく学べます。

効率的な読書戦略:質問設計とコンテキスト管理
Reader3を最大限に活用するための戦略的な読書手法を紹介します。
段階的な質問アプローチ
複雑なトピックは、段階的に理解を深める質問戦略が効果的です。
まず、全体像を把握する質問から始めます。
質問例:
「このアルゴリズムの目的と、解決しようとしている問題を簡単に説明してください」次に、詳細を段階的に掘り下げる質問をします。
質問例:
「では、このアルゴリズムの各ステップを詳しく説明してください」
「ステップ2で使用されているデータ構造について、もう少し詳しく教えてください」最後に、実装や応用を確認する質問で理解を固めます。
質問例:
「このアルゴリズムをPythonで実装する場合、どのようなコードになりますか?」
「実際のプロジェクトでこのアルゴリズムを使う場合の注意点は何ですか?」この段階的アプローチにより、浅い理解から深い実践的知識へと進めます。
効果的なメモの取り方
Reader3での読書中に取るメモには、いくつかのベストプラクティスがあります。
// 重要な質問と回答を記録
notes = {
"chapter": 5,
"question": "マイクロサービスの分割基準",
"answer": reader.last_answer(),
"page_reference": "p.142-145"
}
// セッション終了時にメモを保存
import json
with open("reading_notes.json", "w") as f:
json.dump(all_notes, f, indent=2, ensure_ascii=False)私のプロジェクトでは、各章ごとにJSON形式でメモを保存し、後で検索可能な知識ベースを構築しました。効果的なメモ管理手法については、Windsurf実践ガイド:AI駆動コードエディタで開発効率を3倍にするチーム導入パターンのようなツール活用も参考になります。
読書効率の測定
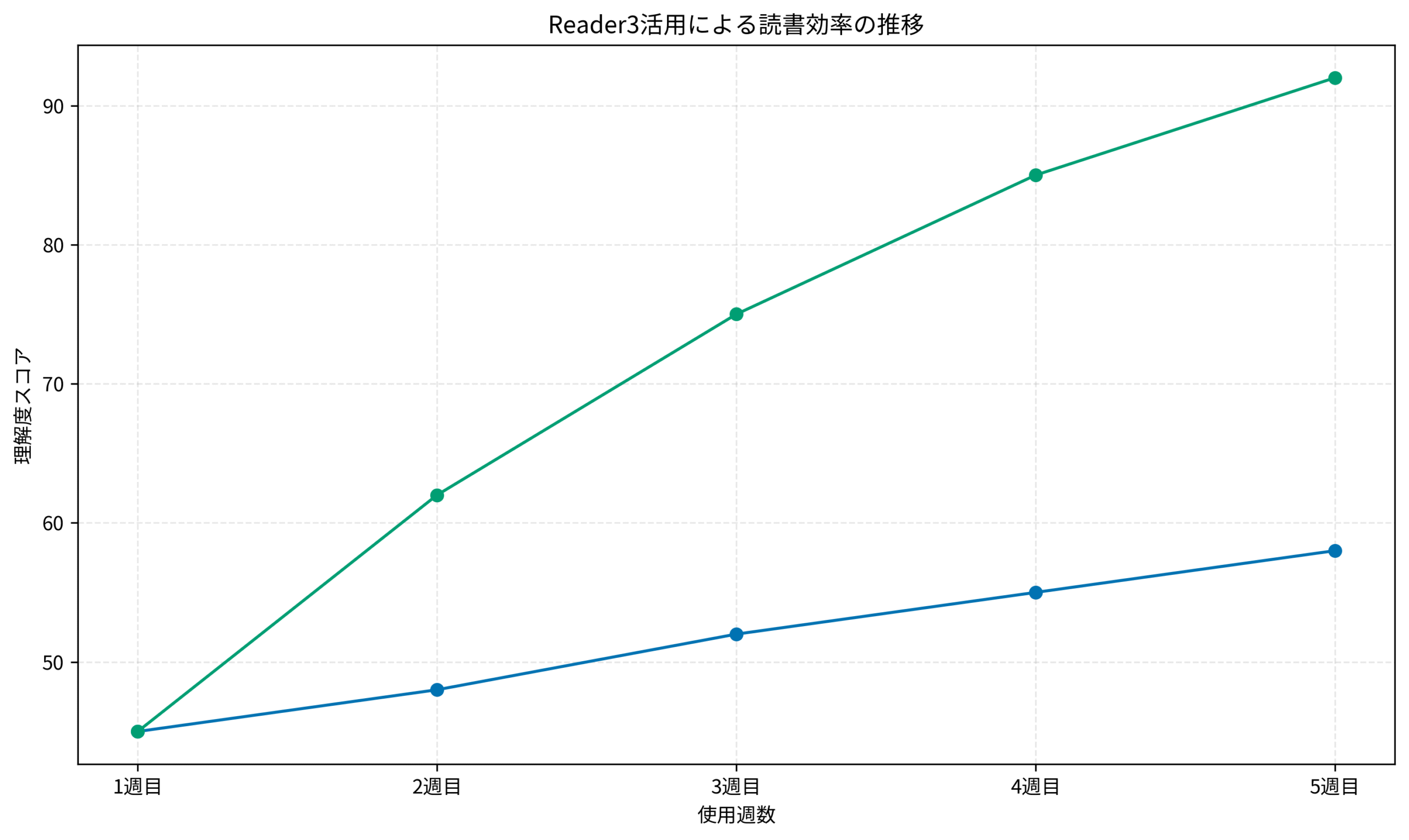
Reader3の効果を可視化することで、読書戦略を改善できます。
このグラフは、Reader3の使用前後での理解度スコアの変化を示しています。従来の読書では5週間で13ポイントの向上でしたが、Reader3活用により47ポイントの向上を達成し、理解速度が約3.6倍に改善されました。
私の経験では、週2〜3回のセッションで、1ヶ月後には読書スピードが明確に向上します。AI駆動開発の実践的な手法は、AI駆動開発完全入門 ソフトウェア開発を自動化するLLMツールの操り方 で体系的に学べます。
実践:難解な技術書を攻略する読書パターン
具体的な技術書のジャンル別に、Reader3を活用した効果的な読書パターンを紹介します。
アーキテクチャ・設計書の攻略
システム設計やアーキテクチャの本では、抽象的な概念と具体的な実装のギャップを埋める質問が有効です。
パターン1: 概念の具体化
「このマイクロサービスパターンを、ECサイトのショッピングカート機能に適用する場合、どのようなサービス分割になりますか?」
パターン2: トレードオフの理解
「この設計パターンを採用した場合のメリットとデメリットを、パフォーマンスと保守性の観点から教えてください」
パターン3: 既存知識との接続
「この章で説明されているイベント駆動アーキテクチャは、前章のCQRSパターンとどう組み合わせられますか?」私のプロジェクトでは、抽象度の高い設計書で、Reader3の対話により実装イメージが明確になりました。アーキテクチャ設計の実践的な学習には、ドメイン駆動設計 が参考になります。
アルゴリズム・データ構造書の攻略
数式やアルゴリズムが多い本では、ステップバイステップの理解が重要です。
// アルゴリズムの各ステップを質問
questions = [
"このアルゴリズムのステップ1で何が起きているか、具体的な例で説明してください",
"ステップ2での時間計算量はどうなりますか",
"エッジケースでの動作を教えてください",
"このアルゴリズムをPythonで実装する際の注意点は?"
]
for q in questions:
answer = reader.ask(q)
print(f"Q: {q}\nA: {answer}\n")最新技術・論文の攻略
論文や最新技術の解説書では、背景知識の補完が効果的です。
パターン1: 前提知識の確認
「この論文で使用されているTransformerアーキテクチャについて、基本概念を簡単に説明してください」
パターン2: 新規性の理解
「この手法は、従来のアプローチと比べてどこが革新的ですか?」
パターン3: 実装可能性の評価
「この手法を実際のプロダクトに組み込む場合、どのような課題がありますか?」私の経験では、最新のAI論文を読む際に、Reader3が数学的な背景や実験結果の解釈を補完してくれることで、理解速度が大幅に向上しました。LangChainを活用したRAGシステム構築については、LangChain 1.0移行実践ガイド:既存LLMエージェントを止めずにアップグレードする手順と検証パターンが参考になります。

チーム活用:知識共有とドキュメント理解の加速
Reader3をチームで活用することで、技術書の理解とナレッジ共有を効率化できます。
読書会での活用
チームの読書会にReader3を導入すると、議論の質が向上します。
// 読書会用のQ&Aセッション記録
session = {
"date": "2025-11-20",
"book": "設計パターン解説書",
"chapter": 5,
"participants": ["Alice", "Bob", "Charlie"],
"questions": [
{"q": "集約の境界をどう決めるか", "asked_by": "Alice"},
{"q": "リポジトリパターンの実装例", "asked_by": "Bob"}
]
}
// 各質問をReader3で解決し、回答を共有
for question in session["questions"]:
answer = reader.ask(question["q"])
question["answer"] = answer
question["discussed"] = Trueこの方法により、議論が脱線せず、各メンバーの疑問を効率的に解決できます。
オンボーディングでの活用
新メンバーのオンボーディング時に、必読の技術書をReader3でサポートします。
// 新メンバー向けの推奨質問リスト
onboarding_questions = {
"week1": [
"このシステムのアーキテクチャ全体像を説明してください",
"認証フローの実装について詳しく教えてください"
],
"week2": [
"データベース設計の考え方を解説してください",
"APIの設計原則について説明してください"
]
}
// 各週の質問に対する回答をドキュメント化
for week, questions in onboarding_questions.items():
print(f"\n{week}の学習内容:")
for q in questions:
answer = reader.ask(q)
save_to_wiki(week, q, answer)私のチームでは、この方法で新メンバーのオンボーディング期間を3週間から2週間に短縮できました。
ナレッジベースの構築
Reader3での質問と回答を蓄積し、検索可能なナレッジベースを構築します。
// 質問と回答をナレッジベースに保存
knowledge_base = []
def add_to_kb(book, chapter, question, answer):
entry = {
"book": book,
"chapter": chapter,
"question": question,
"answer": answer,
"timestamp": datetime.now().isoformat(),
"tags": extract_tags(question, answer)
}
knowledge_base.append(entry)
// 後で検索可能
def search_kb(keyword):
results = [
entry for entry in knowledge_base
if keyword in entry["question"] or keyword in entry["answer"]
]
return resultsこのナレッジベースは、同じ技術書を読む後続メンバーの学習を加速させます。チーム開発での知識共有については、マルチエージェントシステム構築術:LangChainで実現する自律協調型AI開発が参考になります。知識管理の実践手法については、セカンドブレイン が参考になります。

まとめ
Reader3を活用することで、技術書の読書効率を大幅に向上させることができます。LLMと対話しながら読書を進めることで、理解できない箇所で立ち止まることなく、深い理解を獲得できます。Pythonとシンプルな環境構築で始められ、個人でもチームでも活用できる柔軟性があります。
段階的な質問アプローチにより、浅い理解から深い実践的知識へと効率的に進めます。効果的なメモ管理と読書効率の測定で、継続的な改善が可能です。チーム活用では、読書会やオンボーディング、ナレッジベース構築により、組織全体の技術力向上を加速できます。
Reader3は、技術書読書の新しいパラダイムを提供します。小規模な技術書で実験を開始し、質問パターンをカスタマイズしながら、段階的に複雑な専門書へと拡大することで、LLMを活用した効率的な学習システムを構築できます。








