お疲れ様です!IT業界で働くアライグマです!
ここ最近、社内の定例レポートやダッシュボード作成に「LLM+開発環境」を組み合わせるチームが一気に増えてきました。その中でも、CursorのようなAIエディタを使ってデータ分析やレポート生成まで自動化しようとする動きは、PjM視点でも非常にインパクトが大きい取り組みだと感じています。
一方で、現場のPjMやリーダーからは次のような声もよく聞こえてきます。
「毎月のKPIレポートをCursorで自動化したいけれど、どこまで任せてよいか判断がつかない」
「一度仕組みを作ったあと、担当者が変わっても運用し続けられるか不安です」
「セキュリティやレビューの観点で、どこまでをツールに任せ、どこから先を人間が見るべきか整理できていない」
私自身、事業会社のPjMとして「人手でやっていた週次・月次レポート」を段階的に自動化していくプロジェクトを複数担当してきました。最初は私も「Cursorにどこまで分析を任せてよいのか」が分からず、PoCで作ったスクリプトが本番運用に乗らないまま終わってしまったこともあります。しかし、データソース・KPI・レビュー体制といった前提を整理し、運用設計まで含めて仕組み化すると、チーム全体の負荷を下げつつ、レポートの質も安定させることができました。
本記事では、そうした経験を踏まえて、「Cursorに分析をやらせる」状態を目指すPjM向けに、データレポート自動化の設計と運用パターンを整理します。単にスクリプトを書く話ではなく、「誰が・いつ・どのようにレポート結果を信頼できるようにするか」という観点で、一連の流れを見ていきます。
Cursorに分析を任せる前に整理すべき3つの前提
どのレポートを自動化対象にするのかを明確にする
最初の一歩は、「とにかく全部を自動化する」のではなく、どのレポートから着手するかを絞り込むことです。
私のチームでは、次のような観点で候補レポートを棚卸ししました。
- 頻度(週次・月次・四半期など)と作業時間の大きさ
- データソースが安定しているか(集計ロジックが頻繁に変わらないか)
- レポートの読者が誰か(経営層/現場リーダー/プロジェクトチームなど)
この棚卸しを行うことで、「毎月必ずやっているが、やっている本人しか中身を把握していないレポート」や、「人がやらなくても良さそうな定型集計」が見えてきます。まずはこうしたレポートからCursor自動化の対象にすると、効果が分かりやすく、関係者の合意も得やすくなります。棚卸しの進め方については、開発環境のパフォーマンスチューニング:IDEとツールの最適化で作業効率を向上させる手法のように「現状の作業を可視化する」アプローチが参考になります。Measure What Matters(OKR)を手元に置きながら、どのレポートに投資するかをチームで議論してみてください。

Cursorレポート自動化のアーキテクチャ設計
データ取得・変換・レポート生成の責務を分ける
Cursorに分析を任せると言っても、「全部を1つのスクリプトに押し込む」と運用が破綻しやすくなります。
私のチームでは、次の3レイヤーに分けて設計しました。
- データ取得レイヤー:SQLやAPI呼び出しで必要なデータを集める
- 変換レイヤー:取得したデータをKPIごとに集計・加工する
- レポート生成レイヤー:グラフやテキストレポートを組み立てる
このとき、データ取得レイヤーは既存の分析基盤(例:BigQueryやSnowflake)側のクエリとして管理し、Cursorは主に「変換レイヤー以降」を担うようにしました。こうすることで、データソースや権限の管理は既存チームの運用ルールを尊重しつつ、Cursor側では集計ロジックとレポート形式の改善に集中できます。詳しい設計の考え方は、セルフホスト型ナレッジベース構築術:チーム情報共有を3倍効率化するツール選定と運用設計で紹介した「責務分離」の発想がそのまま役に立ちました。LLMまわりの設計方針も合わせて整理しておくとスムーズです。
Cursorプロジェクト構成とテンプレート化
もう1つ大事なのが、「1本のレポートだけに閉じたスクリプト」にしないことです。
私たちは次のようなルールでCursorプロジェクトを構成しました。
- 共通ライブラリフォルダ:日付処理・グラフ共通設定・エラーハンドリングなどをモジュール化
- レポートごとのフォルダ:KPI定義・クエリ・出力フォーマットを1セットで管理
- エントリポイント:すべてのレポートを一括実行するスクリプト
これにより、新しいレポートを追加するときも「既存フォルダをコピーして必要な部分だけ変更する」という流れで進められるようになりました。ChatGPT/LangChainによるチャットシステム構築実践入門を参考に、「LLMが触る部分」と「人間が保守する部分」の境界を意識しながらプロジェクト構成を決めておくと、後から見返したときの理解コストを下げられます。
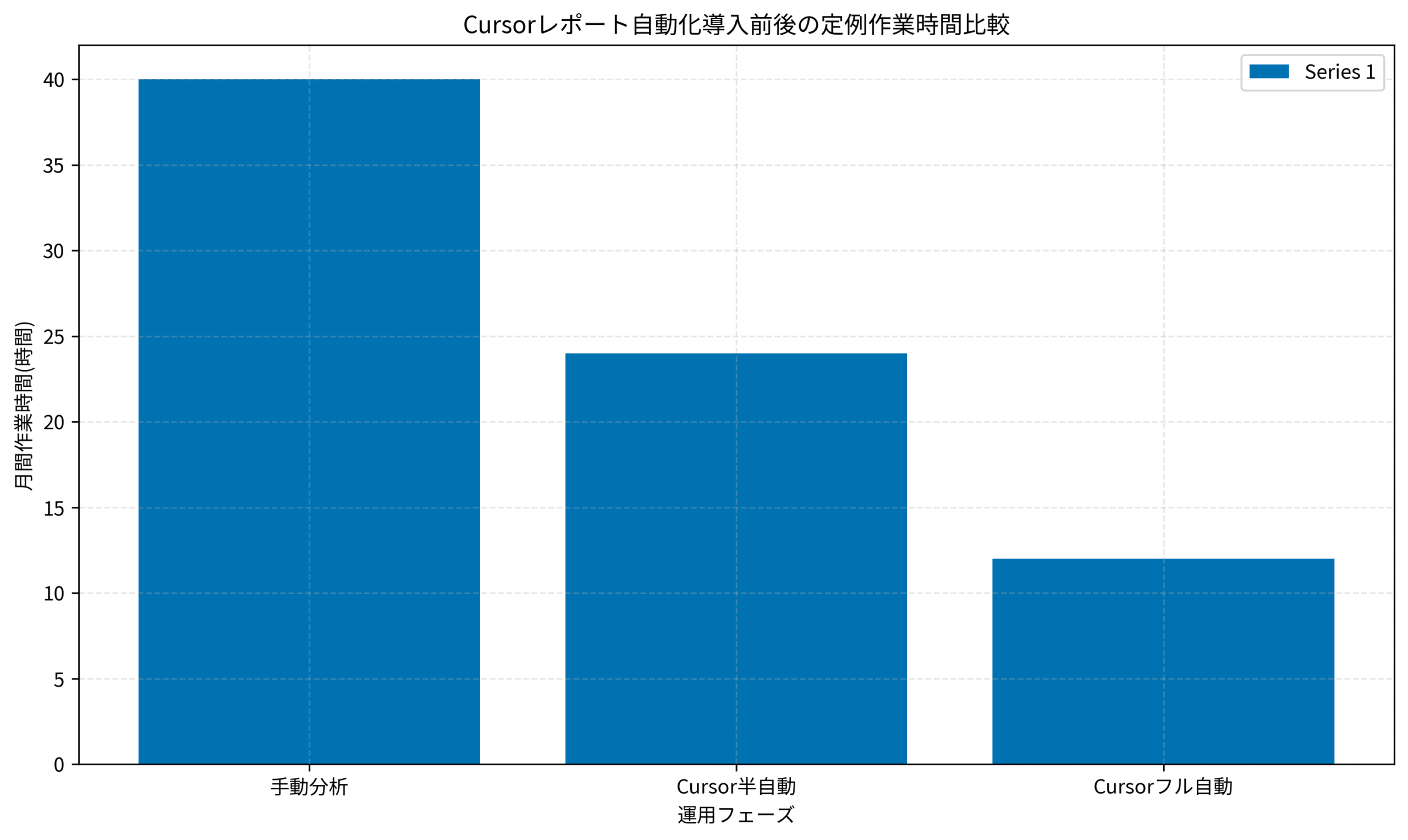
データ品質とレビュー体制の設計
「誰がどのタイミングで数字を信頼するか」を決める
レポート自動化で最も危険なのは、「自動で出てきた数字をそのまま信じてしまう」状態です。
私がPjMとしてまず決めたのは、次の3点でした。
- 初回リリース時は、最低1〜2サイクルは人手のレポートと突き合わせる
- 閾値を超える値動きがあった場合はアラートを出し、必ず人間がレビューする
- 集計ロジックを変更したときは、必ず変更履歴と検証結果を残す
これにより、「Cursorが出してきた数字を盲信する」のではなく、「人間が信頼できるようにするためのプロセス」として自動化を位置付けることができます。類似の考え方は、OpenTelemetry実装ガイドで紹介した「メトリクスの解釈プロセス」の話とも共通しています。モレスキンのようなドット方眼ノートに、気づいたポイントを書き溜めておくと、次回以降のレビューが楽になります。
ログと出力結果を「あとから検証できる形」で残す
もう1つのポイントは、Cursorが実行したクエリや集計ロジックを後から検証できるようにしておくことです。
具体的には、次のような運用にしました。
- 実行したSQLやAPIリクエストを、日付付きのログファイルとして保存する
- レポート出力時点のコードスナップショット(コミットIDやタグ)を記録する
- 過去レポートと比較できるよう、主要KPIをCSVでも保存する
こうすることで、「先月と今月で数字が合わない」といったときに、どこでロジックが変わったのかを辿りやすくなります。ログの置き場所や命名ルールは、OpenTelemetry実装ガイド:分散トレーシングでマイクロサービスの可視化を実現するで紹介しているような観点を応用すると、チーム全体で共有しやすくなります。モレスキン クラシックノート ドット方眼 ラージのような紙のノートに「検証メモ」を残しておくのも、現場では意外と効きます。

定例運用プロセスとモニタリング
実行フローと失敗時のハンドリングを決めておく
Cursorレポート自動化を本番運用に乗せる際には、「誰がボタンを押し、失敗したときにどうするか」をあらかじめ決めておく必要があります。
私のチームでは、次のような運用フローを設計しました。
- 毎週○曜日の午前中に、担当者がCursorプロジェクトから一括実行する
- 実行結果のサマリログをSlackチャンネルに自動投稿する
- エラーが出た場合は、エラー種別ごとに対応フロー(データ欠損/権限エラー/集計ロジック不整合など)を決めておく
この「対応フロー」は、GitHub Copilotでチームの生産性が低下する?PjMが明かす本当の導入判断と社内統制で触れているガバナンスの考え方と似ています。ストレッチや小休憩も含めて自分のコンディションをモニタリングしておくと、定例のレビュー時間を安定して確保しやすくなります。
ダッシュボードで「自動化の健康状態」を見える化する
また、レポートの内容だけでなく、「自動化そのものの健康状態」をモニタリングすることも重要です。
私たちは、次の指標をダッシュボード化しました。
- レポート実行成功率(週次・月次)
- 実行時間の推移(1本あたり・全体)
- エラー発生件数と原因カテゴリ
これにより、「最近エラーが増えていないか」「新しいレポートを追加したことで全体の実行時間が伸びていないか」といった観点を継続的にチェックできます。Fitbit Charge 5 GPS搭載フィットネストラッカーのようなウェルネス系デバイスと同じで、「まずは見える化しないと改善が始まらない」という感覚を、ツール運用にも持ち込むイメージです。

導入プロジェクトの進め方:PjMのチェックリスト
スモールスタートと関係者巻き込み
最後に、PjMの立場から「Cursorレポート自動化プロジェクトをどう進めるか」を整理します。
私が実務で意識しているのは、次のようなステップです。
- まずは1本の月次レポートだけを対象に、小さくPoCを行う
- PoCの結果をもとに、関係者と「どの部分が一番効果的だったか」を振り返る
- 成功パターンをテンプレート化し、2本目・3本目のレポートにも横展開する
このとき、PjMが実践するチーム生産性向上術で紹介しているように、「ツール導入前に成功条件を言語化しておく」ことが、後から振り返るうえで非常に重要です。アジャイルサムライでおなじみのインセプションデッキの考え方を、Cursorレポート自動化にも適用すると、ステークホルダーの期待値を揃えやすくなります。
ナレッジの蓄積と次の自動化候補の発掘
1本目のレポート自動化に成功したら、そこで得た知見をきちんとナレッジとして残しておくことが重要です。
私のチームでは、次のような運用を行いました。
- 「Cursorレポート自動化ハンドブック」として、手順・注意点・テンプレートを社内Wikiにまとめる
- 定例の振り返り会で、「次に自動化したいレポート候補」を毎回3つずつ出してもらう
- 技術的に難しい候補は、先に小さなPoCでリスクを洗い出す
こうしてナレッジと候補リストを溜めておくことで、「自動化の成功体験」が単発で終わらず、チーム全体の文化として定着していきます。外部記憶の考え方を取り入れると、知見が個人に閉じず、組織的に再利用しやすくなります。

まとめ
Cursorに分析をやらせる、という発想は魅力的ですが、設計や運用を誤ると「誰も中身を理解していない自動レポート」が量産されてしまうリスクもあります。
本記事では、まず自動化対象のレポートを棚卸しし、どこから着手するかを決めるところから始めました。次に、データ取得・変換・レポート生成の3レイヤーに分けてアーキテクチャを設計し、Cursorプロジェクトの構成やテンプレート化のポイントを整理しました。
さらに、「誰がどのタイミングで数字を信頼するか」を軸にデータ品質とレビュー体制を設計し、ログや出力結果をあとから検証できる形で残す運用についても触れました。定例運用プロセスとモニタリングの章では、自動化の健康状態をダッシュボードで可視化し、エラー傾向や実行時間の推移を継続的に観測する重要性を整理しました。
最後に、PjMとしての進め方として、スモールスタート・関係者巻き込み・ナレッジ蓄積という3つの観点から、プロジェクトの進行と次の自動化候補の発掘方法を紹介しました。
あなたのチームでも、まずは1本のレポートからで構いません。小さく試しながら成功パターンをテンプレート化し、少しずつ自動化の範囲を広げていくことで、「Cursorに分析をやらせる」世界を現実的な形で実現していきましょう。








