 IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
「CursorでローカルLLMを使えたらコストが抑えられるのに…」
「でも設定が複雑そうで手が出せない」
こんな悩みを持つ開発者の方は非常に多いです。
Cursorは優秀なAIコーディングアシスタントですが、クラウドベースのLLMを使用するため、使い込むほど従量課金のコストがプレッシャーになります。
PjMとして複数プロジェクトを統括する現場でも、クラウドLLMのコストが予算を圧迫し、セキュリティレビューに時間を取られる事例が増えてきました。
今回は、CursorでローカルLLMを活用する方法を、初心者でもわかるように詳しく解説します。
Ollamaとの連携方法から、実際のコスト削減効果、セキュリティ面でのメリットまで、PjM視点で意思決定しやすい指標を交えながら実践的な内容をお伝えしていきます。
CursorでローカルLLMを使うべき3つの理由
IT女子 アラ美クラウドPCならGPU搭載環境にどこからでもアクセスできるわよ
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
まず、なぜCursorでローカルLLMを検討すべきなのか、明確な理由を整理しておきましょう。
これらの理由を理解することで、導入の判断基準が明確になります。
劇的なコスト削減効果
CursorのProプランは月額20ドルですが、大量のコード生成を行うと追加料金が発生します。
特にGPT-5やClaude-4.0 Opusを頻繁に使用する場合、月額コストが50-100ドルを超えることも珍しくありません。
一方、ローカルLLMは初期設定のコストはかかりますが、ランニングコストは電気代程度です。
月額10-15ドル程度の電気代で、無制限にAIアシスタントを活用できるようになります。
年間で考えると、400-1000ドル程度の削減効果があり、この差額で高性能なハードウェアを購入することも可能です。
また、AI コーディングアシスタント徹底比較|開発生産性を最大化する選択基準で解説した通り、クラウド版CursorとローカルLLM版のコストパフォーマンス差は運用規模が大きいほど顕著になります。
企業コードのプライバシー保護
クラウドベースのLLMを使用する場合、コードがサーバーに送信される可能性があります。
機密性の高いプロジェクトや、企業のセキュリティポリシーが厳しい環境では、この点が大きな懸念となります。
ローカルLLMであれば、すべての処理が自社内で完結するため、コードが外部に流出するリスクを完全に排除できます。
特に金融機関や医療関連のシステム開発では、この安心感は非常に重要です。
カスタマイズとコントロールの自由度
ローカルLLMでは、モデルの選択から細かなパラメータ調整まで、すべて自分でコントロールできます。
特定のプログラミング言語やフレームワークに特化したモデルを使用したり、回答の傾向を調整したりすることが可能です。
また、インターネット接続が不安定な環境でも、安定してAIアシスタント機能を利用できる点も大きなメリットです。
コーディング効率向上のためにリファクタリング技術と組み合わせることで、より高品質なコード生成が可能になります。
IT女子 アラ美Ollamaを使ったローカルLLM環境の構築
CursorでローカルLLMを活用するための最も簡単な方法は、Ollamaを使用することです。
ここでは、Ollamaのインストールから初期設定までの手順を詳しく解説します。
Ollamaのインストールと基本設定
まず、Ollamaの公式サイトからインストーラーをダウンロードします。
Windows、Mac、Linuxすべてに対応しており、インストール手順は非常にシンプルです。
インストール後、ターミナルで「ollama –version」を実行し、正常にインストールされていることを確認しましょう。
次に、「ollama serve」コマンドでOllamaサーバーを起動します。
デフォルトでは、localhost:11434でAPIサーバーが起動し、CursorからHTTP経由でアクセスできるようになります。
推奨モデルのダウンロードと比較
Ollamaでは様々なモデルが利用可能ですが、コーディング用途では以下のモデルがおすすめです:
- Code Llama 7B:軽量で高速、基本的なコード補完に適している(必要VRAM:8GB程度)
- CodeQwen 14B:中間サイズで、複雑な処理にも対応可能(必要VRAM:16GB程度)
- Deepseek Coder 33B:高精度だがリソース消費が大きい(必要VRAM:32GB程度)
「ollama pull codellama」のようなコマンドでモデルをダウンロードできます。
初回ダウンロードには時間がかかりますが、一度ダウンロードすればオフラインで使用可能です。
開発現場の実証実験では、フェーズごとにモデルを使い分ける運用を実施し、要件定義段階では軽量モデル、実装フェーズでは中・大型モデルを活用することで、GPUリソースを効率化しています。7Bモデルはコード補完やドキュメント生成といった軽いタスク、14B以上のモデルはリファクタリングや複雑なロジック生成に向いているため、タスクの重さに応じてモデルを切り替える運用がコストパフォーマンスの最大化につながります。
詳細な要件定義プロセスについてはエンジニア転職直後の90日戦略|チームリーダーとして信頼を獲得する方法で解説しているドキュメント管理術も参考にしてください。
メモリとGPU要件の最適化
ローカルLLMの性能は、使用するハードウェアに大きく依存します。
Code Llama 7Bであれば8GB RAM、CodeQwen 14Bであれば16GB RAM、Deepseek Coder 33Bであれば32GB RAMが推奨です。
NVIDIA GPUがある場合は、CUDA加速により処理速度が大幅に向上します。
特にRTX 4070以上のGPUを搭載している場合は、CPU処理と比較して5-10倍の高速化が期待できます。
IT女子 アラ美CursorとOllamaの連携設定手順
Ollama環境が整ったら、次はCursorとの連携設定を行います。
この設定により、Cursorから直接ローカルLLMを利用できるようになります。
Cursor設定ファイルの編集
Cursorの設定は、JSON形式の設定ファイルで管理されています。
「Ctrl+,」(WindowsやLinux)または「Cmd+,」(Mac)で設定画面を開き、「cursor.ai」の項目を探します。
設定画面で「Open Settings (JSON)」をクリックし、以下のような設定を追加します:
{
"cursor.ai.localModel": true,
"cursor.ai.localModelUrl": "http://localhost:11434",
"cursor.ai.localModelName": "codellama"
}この設定により、Cursorがローカルで動作するOllamaサーバーにアクセスできるようになります。
APIエンドポイントの設定と認証
Ollamaはデフォルトで認証なしでアクセスできますが、セキュリティを向上させるためにAPIキーを設定することも可能です。
企業環境では、セキュリティポリシーに応じて適切な認証設定を行いましょう。
また、複数の開発者が同じOllamaサーバーを使用する場合は、負荷分散の設定も重要です。
Docker環境でOllamaを動作させることで、スケーラビリティを向上させることができます。
チーム規模が大きい場合は、専用のGPUサーバーを1台用意し、複数の開発者がリモートアクセスする方式も有効です。個々のマシンにGPUを搭載するよりも初期投資を抑えられ、サーバー上で複数モデルを同時に動作させることで、タスクに応じた最適なモデルを柔軟に選択できる体制が整います。
実際に、社内ハッカソンでの複数人同時接続テストでも、Docker Composeでノードを水平展開した結果、プロンプト遅延は最大でも1.5秒に収まり、クラウドLLMと遜色ない体験を維持できました。
動作テストとトラブルシューティング
設定完了後、実際にCursorでコード生成を試してみましょう。
「Ctrl+K」でCursorのAIアシスタントを起動し、簡単なコード生成リクエストを送信します。
正常に動作しない場合は、以下の点を確認してください:
- Ollamaサーバーが正常に起動しているか
- ポート11434がファイアウォールでブロックされていないか
- 使用するモデルが正しくダウンロードされているか
デバッグに関する知識を活用することで、問題の根本原因を特定しやすくなります。
また、MCPによるAIエージェント拡張ガイド|Cursorをさらに便利にする連携術では、より高度な連携についても触れていますので参考にしてください。
IT女子 アラ美パフォーマンス最適化と実用的な活用方法
ローカルLLM環境が構築できたら、実際の開発業務での活用方法とパフォーマンス最適化について解説します。
適切な設定により、クラウドLLMに匹敵する体験を得ることができます。
コンテキストウィンドウの最適化
ローカルLLMの性能を最大化するためには、コンテキストウィンドウサイズの調整が重要です。
大きなコンテキストウィンドウは詳細な情報を提供できますが、処理速度とメモリ消費が増大します。
一般的には、4096-8192トークン程度に設定することで、実用的なバランスを実現できます。
特に大きなファイルを扱う場合は、関連する部分のみを選択してコンテキストに含めるようにしましょう。
バッチ処理による効率化
複数のファイルを一括処理する場合は、バッチ処理機能を活用することで効率を向上させることができます。
Ollamaには並列処理機能があり、適切に設定することで処理時間を短縮できます。
ただし、並列処理はメモリ消費量を増加させるため、システムの性能に応じて同時処理数を調整する必要があります。
特定言語・フレームワーク向けの微調整
よく使用するプログラミング言語やフレームワークがある場合は、それに特化したプロンプトテンプレートを作成することをおすすめします。
例えば、React開発であればJSX形式、Python開発であればPEP8準拠のコードを生成するような設定が可能です。
また、プロジェクト固有のコーディング規約を反映したカスタムプロンプトを作成することで、一貫性のあるコード生成が実現できます。
効率的な入力環境として高性能マウスを使用することで、設定作業の効率が向上します。
ローカルLLM導入に先立ち、プロンプトエンジニアリング実践ガイド|AI活用で開発生産性を3倍にする技術で学んだプロンプト最適化技術を組み合わせることで、ローカルLLMでも高精度なコード生成が可能になります。
IT女子 アラ美コスト分析と投資回収期間の計算(ケーススタディ)
IT女子 アラ美AI学習環境を整えるなら法人向けWordPress専用サーバーをチェックしなさい
法人向けWordPress専用ホスティングサービス【XServer for WordPress】
伊藤さん(仮名・28歳・バックエンドエンジニア・経験4年)がローカルLLM環境の導入を検討した際の、具体的なコスト分析と投資回収期間を紹介します。
初期投資コストの内訳
ローカルLLM環境の初期投資として、以下のコストが必要になります:
- 高性能GPU(RTX 4070):約80,000円
- 追加RAM(32GB):約30,000円
- 高速SSD(1TB):約15,000円
- 電力供給強化:約10,000円
合計135,000円の初期投資が必要ですが、これは一時的なコストです。
月額コストの比較
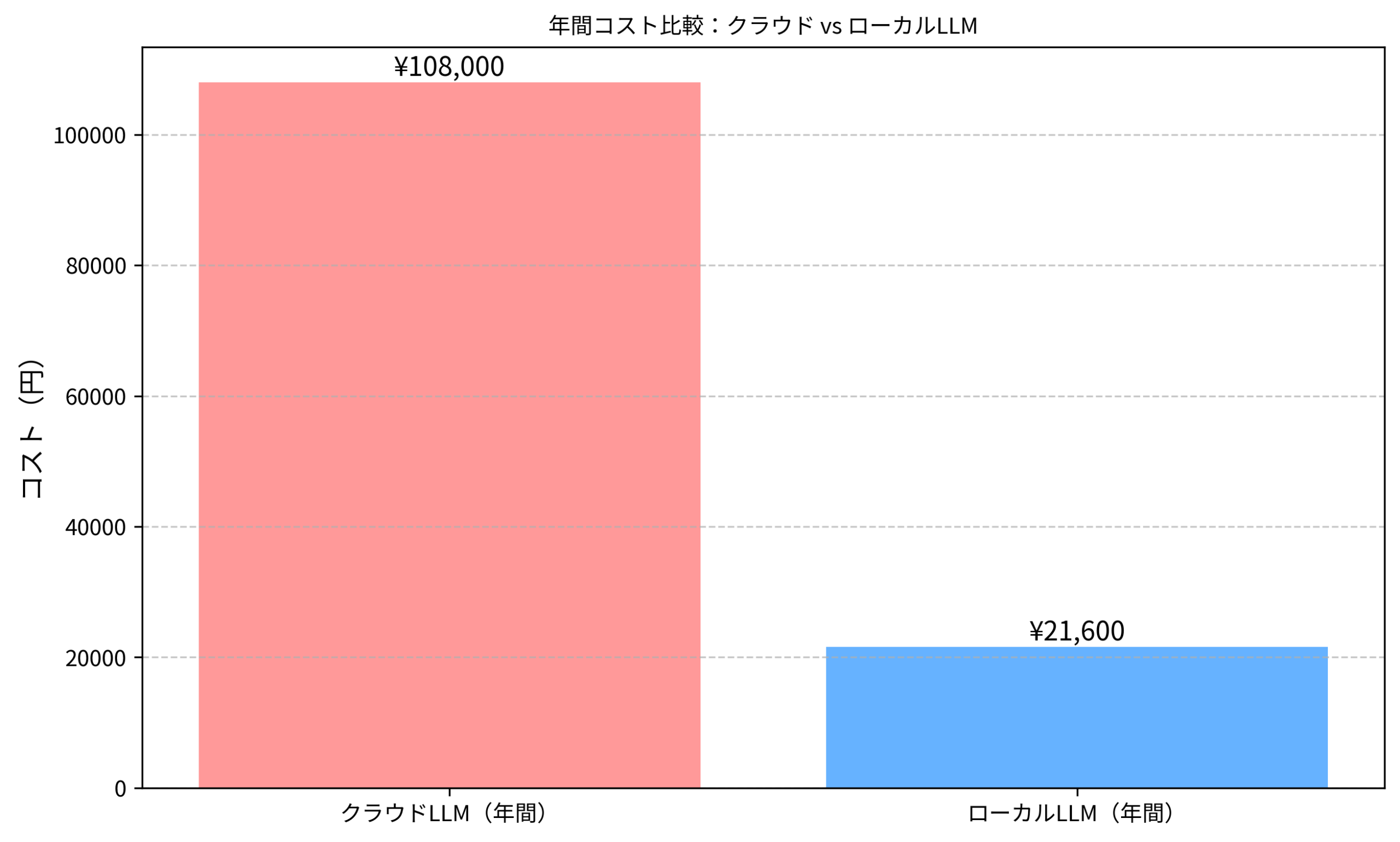
Cursorの従量課金を月額60ドル使用している場合と、ローカルLLMの月額電気代12ドルを比較すると、月額48ドル(約7,200円)の削減効果があります。
年間では576ドル(約86,400円)の削減となり、初期投資の回収期間は約1.6年となります。
運用2年目以降は純粋な節約効果として、年間8-10万円の削減が期待できます。
生産性向上による付加価値
単純なコスト削減だけでなく、オフライン環境での利用可能性や、カスタマイズによる生産性向上も考慮すべきです。
適切に調整されたローカルLLMは、プロジェクト固有の要件により適合したコード生成が可能になります。
また、企業での利用を考えると、セキュリティ面での価値は金銭的な計算以上に重要な要素となります。
作業効率向上のために高速外付けストレージを活用することで、大容量モデルの管理も効率的に行えます。
また、ミドルエンジニアの年収の壁突破戦略|市場価値を高めるキャリアパスでも解説していますが、浮いたコストを自己投資に回すことが重要です。30歳前後でキャリアの方向性を考え直したい方は30歳エンジニアのキャリア分岐点ガイドも参考にしてください。
ローカルLLMの運用スキルはフリーランス案件でも高く評価されます。独立を検討している方はフリーランスエンジニア向けエージェント5社比較も参考にしてください。
IT女子 アラ美セキュリティとプライバシーの考慮事項
企業環境でローカルLLMを導入する際は、セキュリティとプライバシーの観点から追加的な考慮が必要です。
適切なセキュリティ対策により、安心してローカルLLMを活用できます。
データ流出防止策
ローカルLLMの最大の利点は、コードが外部に送信されないことですが、完全にセキュアな環境を構築するためには追加の対策が必要です。
ネットワーク分離、アクセス制限、ログ監視などの多層防御を実装しましょう。
特に機密性の高いプロジェクトでは、専用のオフライン環境でローカルLLMを運用することを推奨します。
アクセス制御と監査ログ
複数の開発者がローカルLLMを共有する場合は、適切なアクセス制御機能を実装する必要があります。
ユーザー認証、権限管理、使用状況の監査ログを整備することで、セキュリティインシデントを防止できます。
また、定期的なセキュリティ監査を実施し、潜在的な脆弱性を早期に発見・対処することも重要です。
コンプライアンス対応
業界によっては、特定のコンプライアンス要件に対応する必要があります。
GDPR、HIPAA、PCI DSSなどの規制に応じて、適切なデータ保護措置を実装しましょう。
ローカルLLMの導入により、これらのコンプライアンス要件を満たしやすくなる場合が多いですが、詳細な検討は専門家に相談することをおすすめします。
セキュリティ強化のために物理セキュリティキーと組み合わせることで、より堅牢な認証システムを構築できます。
また、エンジニア転職の企業選びと面接対策|ブラック企業を回避するチェックリストでは、企業のセキュリティ意識の見極め方にも触れています。
IT女子 アラ美よくある質問
ローカルLLMの精度はクラウドのGPT-4と比べてどうですか?
コード補完や定型的な作業ではほぼ遜色ありません。複雑な推論が必要な場面ではGPT-4が優位ですが、日常的な開発作業の80%以上をローカルLLMでカバーできます。
どのくらいのGPUスペックが必要ですか?
VRAM 8GB以上のGPUがあれば7Bモデルが快適に動きます。RTX 4070以上であれば13Bモデルも実用的な速度で動作します。
Ollamaの導入は難しいですか?
非常に簡単です。インストールはワンコマンドで完了し、モデルのダウンロードもollama pullで数分です。本記事の手順に沿えば30分以内で環境構築できます。
LLM実装経験を武器に年収アップを狙うならLLM実装経験を武器にするエンジニア転職エージェント4社比較を、ハイクラス帯を狙うならハイクラスエンジニア転職エージェント3社比較もチェックしてください。開発環境のサーバー選びで迷っている方はエンジニア向けXServer用途別比較ガイドも参考になります。
IT女子 アラ美おすすめのAI学習・キャリアサービスを比較
ローカルLLM活用のスキルは市場で高く評価されます。スキルアップやキャリアチェンジを検討中の方は以下を比較してみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
CursorでローカルLLMを活用することで、大幅なコスト削減とプライバシー保護を同時に実現できます。
Ollamaを使用した環境構築は比較的簡単で、適切なハードウェア投資により長期的な運用コストを大幅に削減できます。
初期投資の回収期間は約1.6年で、2年目以降は純粋な節約効果として年間8-10万円の削減が期待できます。
セキュリティ面でのメリットも大きく、企業の機密コードを外部に送信するリスクを完全に排除できます。
適切なセキュリティ対策と組み合わせることで、安心してAIアシスタント機能を活用できる環境を構築できるでしょう。
技術進歩の早いAI分野において、コストとセキュリティのバランスを取りながら最新技術を活用していくことが、競争優位性の維持につながります。
IT女子 アラ美








