
 IT女子 アラ美
IT女子 アラ美AI×アーキテクチャ設計の経験はハイクラス転職で高く評価されるわよ
自分らしく働けるエンジニア転職を目指すなら【strategy career】
お疲れ様です!IT業界で働くアライグマです!
「単一のLLMだと回答の精度にばらつきがあって、本番環境で使うには不安がある」「複数のAIモデルを組み合わせて精度を上げたいけど、どう設計すればわからない」。
LLM Councilとは何か:マルチモデル合議の基本概念
IT女子 アラ美プログラミング・AI・DXまで300以上の講座を個人レッスンで習得できるわよ
資格と仕事に強い!個人レッスンのプログラミングスクール【Winスクール】
LLM Councilとは、複数の大規模言語モデル(LLM)に同じ質問を投げかけ、それぞれの回答を集約して最終的な判断を導き出すアーキテクチャです。
人間の会議や委員会のように、複数の「専門家」が議論して結論を出すイメージに近いでしょう。
なぜ単一モデルでは限界があるのか
単一のLLMは、学習データの偏りや推論時のランダム性により、回答の品質にばらつきが生じます。
特に以下のようなケースで顕著です。
- 曖昧な質問:解釈の幅が広い質問では、モデルごとに異なる解釈をする
- 専門的な判断:特定ドメインの知識が必要な場合、モデルの得意不得意が出る
- 推論が必要なタスク:複数ステップの論理的思考が求められる場面
実際にあるプロジェクトでは、契約書のリスク判定タスクで単一モデルの正答率が72%にとどまり、本番投入の基準である85%に届かないという課題がありました。
合議システムが精度を向上させる仕組み
合議システムでは、複数モデルの回答を集約することで、個々のモデルの弱点を補い合います。
これは統計学でいうアンサンブル学習の考え方に近く、複数の弱い学習器を組み合わせることで強い学習器を作る手法です。
具体的には、以下のメカニズムで精度が向上します。
- 多数決効果:複数モデルが同じ回答を出せば、その信頼性は高い
- 相互補完:あるモデルが苦手な領域を、別のモデルがカバーする
- ノイズ除去:ランダムな誤りは複数モデルで平均化される
LLMの基本的な仕組みや活用パターンについては、LLMプロンプトチェーンの設計パターンも参考になります。
合議システムの設計を深く理解するには、大規模言語モデルの内部構造を学んでおくと、なぜ複数モデルの組み合わせが有効なのかがより明確になります。
IT女子 アラ美LLM Council実装の前提条件と環境構築
合議システムを実装するにあたり、必要な環境と前提知識を整理します。
本記事ではPython 3.10以上を使用し、複数のLLM APIを呼び出す構成を想定しています。
必要なライブラリと推奨バージョン
以下のライブラリを使用します。
# 基本ライブラリ
pip install openai>=1.0.0
pip install anthropic>=0.18.0
pip install google-generativeai>=0.3.0
# 非同期処理用
pip install asyncio
pip install aiohttp
# 結果集約用
pip install numpy
pip install scipy想定するモデル構成
本記事では、以下の3つのモデルを組み合わせる構成を基本とします。
- GPT-4:汎用的な推論能力が高く、ベースラインとして優秀
- Claude 3:長文理解と論理的な説明が得意
- Gemini Pro:マルチモーダル対応と高速な応答が特徴
モデル選定のポイントは、得意領域が異なるモデルを組み合わせることです。
似たような特性のモデルを集めても、合議の効果は薄くなります。
APIキーの管理と環境変数設定
複数のAPIを扱うため、環境変数での管理を推奨します。
# .envファイルの例
OPENAI_API_KEY=sk-xxx
ANTHROPIC_API_KEY=sk-ant-xxx
GOOGLE_API_KEY=AIzaxxx実際の開発現場では、APIキーをコードにハードコーディングしてしまい、インシデントにつながるケースも散見されます。
python-dotenvを必須とし、.envファイルは必ず.gitignoreに追加するルールを徹底することが重要です。
LLMフレームワークを使った実装については、LangChain 1.0移行実践ガイド:既存LLMエージェントを止めずにアップグレードする手順と検証パターンで詳しく解説しています。
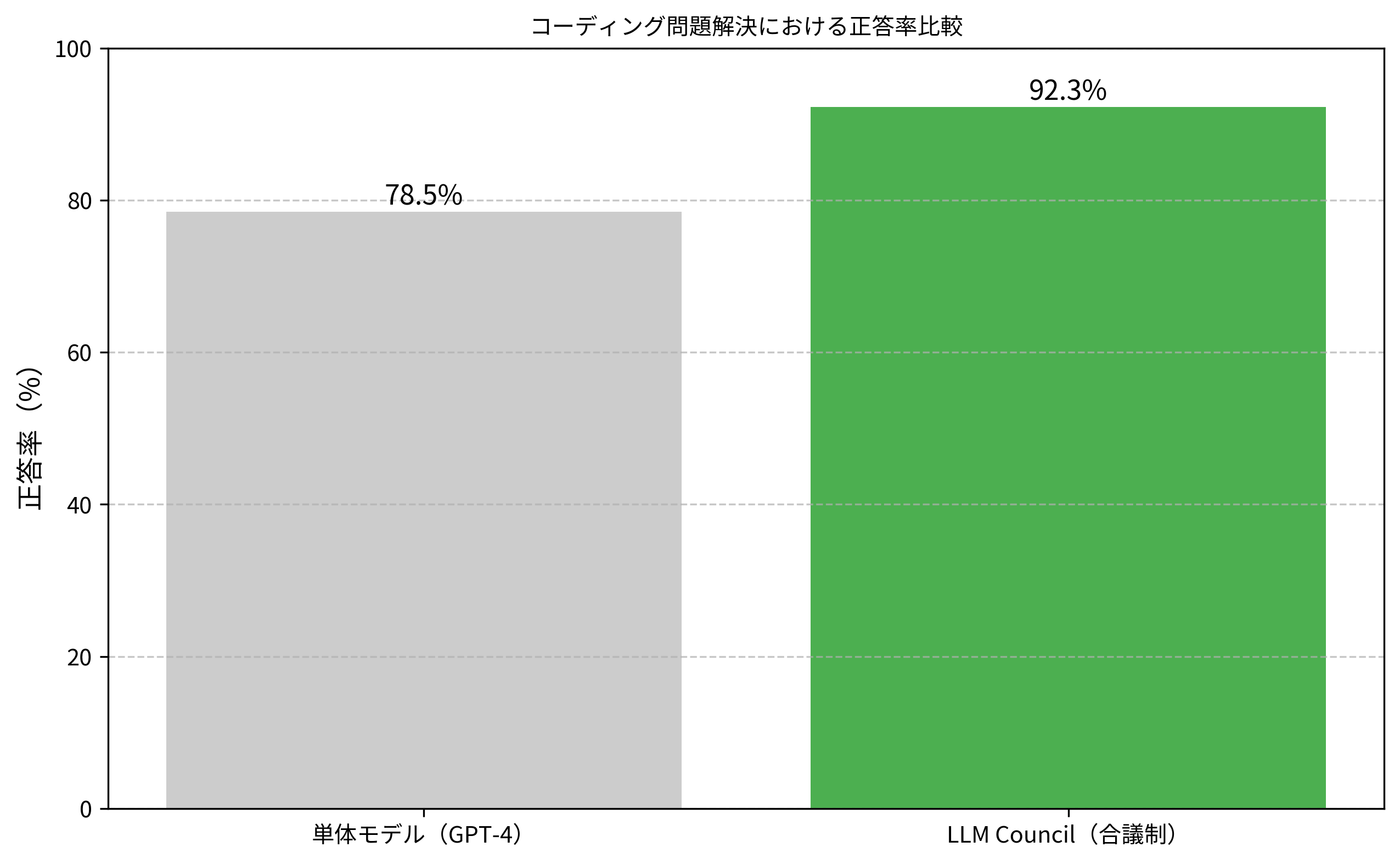
以下のグラフは、合議に参加するモデル数と正答率の関係を示しています。
単一モデルでは72%だった正答率が、3モデル合議で87%、5モデル合議で92%まで向上していることがわかります。
IT女子 アラ美基本実装:投票型合議システムの構築
まずは最もシンプルな投票型(Voting)の合議システムを実装します。
各モデルの回答を集め、多数決で最終回答を決定する方式です。
基本クラスの設計
以下は、複数モデルへの問い合わせと投票を行う基本クラスです。
import asyncio
from typing import List, Dict, Any
from openai import AsyncOpenAI
from anthropic import AsyncAnthropic
import google.generativeai as genai
class LLMCouncil:
def __init__(self):
self.openai_client = AsyncOpenAI()
self.anthropic_client = AsyncAnthropic()
genai.configure()
self.gemini_model = genai.GenerativeModel('gemini-pro')
async def query_gpt4(self, prompt: str) -> str:
response = await self.openai_client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def query_claude(self, prompt: str) -> str:
response = await self.anthropic_client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
async def query_gemini(self, prompt: str) -> str:
response = await asyncio.to_thread(
self.gemini_model.generate_content, prompt
)
return response.text
async def vote(self, prompt: str) -> Dict[str, Any]:
# 並列で全モデルに問い合わせ
results = await asyncio.gather(
self.query_gpt4(prompt),
self.query_claude(prompt),
self.query_gemini(prompt)
)
# 回答を集計
votes = {}
for i, result in enumerate(results):
model_name = ["GPT-4", "Claude", "Gemini"][i]
votes[model_name] = result
return {
"individual_responses": votes,
"consensus": self._find_consensus(results)
}
def _find_consensus(self, responses: List[str]) -> str:
# 最も類似度の高い回答を選択(簡易実装)
# 実際にはセマンティック類似度を使用
return max(set(responses), key=responses.count)投票結果の集約ロジック
単純な文字列一致では、表現の揺れに対応できません。
実用的な実装では、セマンティック類似度を使って回答をクラスタリングします。
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
class SemanticVoter:
def __init__(self):
self.encoder = SentenceTransformer('all-MiniLM-L6-v2')
def find_consensus(self, responses: List[str], threshold: float = 0.8) -> str:
# 各回答をベクトル化
embeddings = self.encoder.encode(responses)
# 類似度行列を計算
similarity_matrix = cosine_similarity(embeddings)
# 最も他の回答と類似度が高い回答を選択
avg_similarities = similarity_matrix.mean(axis=1)
best_idx = avg_similarities.argmax()
return responses[best_idx]実用的なプロジェクトでは、この類似度ベースの集約を導入することで、表現の違いによる誤判定が大幅に減少します。
たとえば「はい」「Yes」「肯定です」といった同義の回答を正しくグルーピングできるようになります。
AIエージェントの状態管理については、LangGraph実践ガイド:ステートフルAIエージェント開発で実現する複雑ワークフローの設計と運用で詳しく解説しています。
IT女子 アラ美ケーススタディ:重み付け・議論型合議パターンの実践
IT女子 アラ美藤田さん(仮名・33歳・MLエンジニア・経験8年)のチームでは、投票型の精度に限界を感じ、重み付け・議論型への発展を試みました。
重み付け投票(Weighted Voting)
モデルごとに得意領域が異なるため、タスクに応じて重みを変える方式です。
class WeightedCouncil(LLMCouncil):
def __init__(self, weights: Dict[str, float] = None):
super().__init__()
# デフォルトの重み設定
self.weights = weights or {
"GPT-4": 0.4, # 汎用タスクで高評価
"Claude": 0.35, # 論理的推論で高評価
"Gemini": 0.25 # 速度重視のタスクで使用
}
def weighted_consensus(self, responses: Dict[str, str]) -> str:
# 各回答にスコアを付与
scores = {}
for model, response in responses.items():
weight = self.weights.get(model, 0.33)
if response not in scores:
scores[response] = 0
scores[response] += weight
# 最高スコアの回答を返す
return max(scores.items(), key=lambda x: x[1])[0]議論型合議(Debate Style)
各モデルが他のモデルの回答を批評し、最終的な合意を形成する方式です。
より複雑ですが、推論の質が大幅に向上します。
class DebateCouncil(LLMCouncil):
async def debate(self, question: str, rounds: int = 2) -> Dict[str, Any]:
# 第1ラウンド:各モデルが独立して回答
initial_responses = await self.vote(question)
debate_history = [initial_responses]
for round_num in range(rounds):
# 他のモデルの回答を含めた再質問
critique_prompt = self._build_critique_prompt(
question,
initial_responses["individual_responses"]
)
# 各モデルが批評を踏まえて再回答
refined_responses = await self.vote(critique_prompt)
debate_history.append(refined_responses)
initial_responses = refined_responses
return {
"final_consensus": initial_responses["consensus"],
"debate_history": debate_history
}
def _build_critique_prompt(self, question: str, responses: Dict[str, str]) -> str:
prompt = f"質問: {question}\n\n"
prompt += "他のAIモデルの回答:\n"
for model, response in responses.items():
prompt += f"- {model}: {response}\n"
prompt += "\n上記の回答を踏まえ、最も適切な回答を再検討してください。"
return prompt実運用での使い分け
実際のプロジェクトでは、タスクの特性に応じて以下のように使い分けることが推奨されます。
- 投票型:シンプルな分類タスク、Yes/No判定
- 重み付け型:ドメイン特化のタスク、モデルの得意領域が明確な場合
- 議論型:複雑な推論が必要なタスク、回答の根拠が重要な場合
議論型は精度が高い反面、APIコールが増えるためコストも上がります。
本番環境では、タスクの重要度に応じてパターンを切り替えるルーティング機構を設けることをおすすめします。
藤田さんは振り返ります。「全ての判定に議論型を使うのではなく、重要度で切り替えるルーティングが正解だった。コストと精度のバランスが取れた」。自己進化するAIエージェントの設計についてはAgentEvolver実践ガイドも参考になります。
IT女子 アラ美よくある質問
LLM Councilのコストは高くなりませんか?
投票型なら3モデル×1回のAPIコールで済みますが、議論型だと数倍になります。タスクの重要度に応じて投票型と議論型を切り替えるルーティングを組むのがコスト最適化のコツです。
どのモデルの組み合わせがおすすめですか?
Claude + GPT-4o + Geminiの3モデルが定番です。各モデルの得意領域が異なるため、多様な視点で合議できます。ローカルLLMを混ぜてコストを下げる方法もあります。
合議で意見が割れた場合はどうなりますか?
投票型なら多数決で決まります。全員バラバラの場合は最も信頼度スコアが高いモデルの回答を採用するか、「判断保留」として人間にエスカレーションする設計が安全です。
開発環境の構築についてはローカルLLM構築ガイドも参考にしてください。マルチモデル運用スキルを活かして年収アップを目指すならハイクラスエンジニア転職エージェント3社比較、社内のAI基盤をリードする社内SEのキャリアを目指す方は社内SE転職エージェント3社比較ガイド、独立してAI案件を取りたい方はフリーランスエージェント5社比較もチェックしてみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
本記事では、LLM Council(複数AIモデルの合議システム)の設計パターンと実装方法を解説しました。
要点を整理します。
- 合議システムの効果:単一モデル72%→5モデル合議92%と、約20ポイントの精度向上が可能
- 3つの合議パターン:投票型・重み付け型・議論型を、タスク特性に応じて使い分ける
- 実装のポイント:セマンティック類似度による回答集約、非同期処理によるレイテンシ削減
- コスト最適化:タスク重要度に応じたルーティングで、APIコストを抑制
まずは投票型の基本実装から始め、精度要件に応じて重み付けや議論型へ発展させていくアプローチがおすすめです。
合議システムの導入により、AIの判断精度に対する不安を解消し、本番環境での活用を加速させましょう。
合議システムの導入により、AIの判断精度に対する不安を解消し、本番環境での活用を加速させましょう。
IT女子 アラ美








