お疲れ様です!IT業界で働くアライグマです!
「FastAPIで開発したAPIが本番環境で遅い」
「非同期処理を導入したのに期待した速度が出ない」
「パフォーマンス最適化の優先順位がわからない」
FastAPIは高速なWebフレームワークとして知られていますが、本番環境で真価を発揮するには適切な設計と最適化が必要です。
私のチームでも、初期リリース時にはAPIの応答速度が遅く、ユーザーからクレームを受けていました。
この記事では、FastAPIを本番環境で3ヶ月運用し、応答速度を3倍に改善した経験をもとに、非同期処理の実装パターンとパフォーマンス最適化の実践手法を解説します。
特に、チーム全体で守るべき設計原則と、効果の高い最適化ポイントを具体的に紹介します。
FastAPIの非同期処理アーキテクチャ:基本設計と落とし穴
FastAPIの非同期処理は、ASGIサーバー上でPythonのasyncio機能を活用して実現されます。
適切に実装すれば、I/O待機時間を有効活用して処理効率を大幅に向上できます。
私が最初にFastAPIを導入したとき、すべてのエンドポイントをasync defで定義すれば自動的に高速化されると誤解していました。
実際には、非同期処理の恩恵を受けるには、依存関係全体を非同期対応させる必要があります。
非同期処理の基本原則を理解することが、FastAPI最適化の第一歩です。
I/O待機の非同期化
I/O待機の非同期化では、データベースアクセス・外部API呼び出し・ファイル読み書きなど、待機時間が発生する処理を非同期化します。
私のチームでは、PostgreSQLへのクエリをasyncpgで非同期化し、応答時間を平均60%削減しました。
CPU集約処理の分離
CPU集約処理の分離では、画像処理・データ集計・暗号化など、CPU負荷の高い処理は別スレッドやプロセスで実行します。
asyncioのrun_in_executorを使い、ProcessPoolExecutorでCPU集約処理を並列化することで、メインスレッドのブロックを回避できます。
同期コードの混在リスク
同期コードの混在リスクでは、非同期エンドポイント内で同期的なライブラリを呼び出すと、イベントループ全体がブロックされます。
私のチームでは、requests(同期)をhttpx(非同期)に置き換え、外部API呼び出しの並列度を10倍に向上させました。
非同期処理の設計では、依存関係全体の非同期対応を徹底することが重要です。
関連記事:Python非同期プログラミング実践ガイドでは、asyncioの基礎と実装パターンを解説しています。
Web APIの設計 (Programmer's SELECTION)を参考にすると、Web APIの設計原則を体系的に学べます。

データベース接続の最適化:コネクションプールと非同期ORM
データベースアクセスは、API応答速度に最も大きな影響を与える要素です。
適切なコネクションプール設定と非同期ORMの活用により、データベース処理を大幅に高速化できます。
私のチームでは、初期実装でSQLAlchemyの同期版を使用していましたが、リクエストごとにコネクション確立のオーバーヘッドが発生していました。
非同期版のSQLAlchemyとasyncpgに移行し、コネクションプールを適切に設定することで、データベースアクセスの応答時間を70%削減しました。
コネクションプール設定では、最小接続数・最大接続数・接続タイムアウトを適切に調整します。
最小接続数は、常時維持する接続数を指定します。
私のチームでは、通常時の同時リクエスト数を基準に、最小接続数を10に設定しています。
起動時にコネクションを確立しておくことで、初回リクエストの遅延を回避できます。
最大接続数は、ピーク時に確立できる接続数の上限を指定します。
データベースサーバーの最大接続数とアプリケーションサーバー台数を考慮し、1台あたり50接続を上限としています。
過剰な接続数設定は、データベースサーバーのリソースを圧迫するため注意が必要です。
接続タイムアウトは、コネクション確立の待機時間を指定します。
私のチームでは、30秒のタイムアウトを設定し、データベース障害時に無限待機を防いでいます。
非同期ORMの活用では、SQLAlchemy 2.0の非同期機能を使い、複数クエリの並列実行を実現します。
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.orm import sessionmaker
engine = create_async_engine(
"postgresql+asyncpg://user:pass@localhost/db",
pool_size=10,
max_overflow=40,
pool_timeout=30,
pool_recycle=3600
)
async_session = sessionmaker(
engine, class_=AsyncSession, expire_on_commit=False
)
async def get_user_with_posts(user_id: int):
async with async_session() as session:
user = await session.get(User, user_id)
await session.refresh(user, ["posts"])
return user
このコード例では、コネクションプールの設定とセッション管理を実装しています。
pool_recycleで接続の再利用時間を制限し、長時間接続によるリソースリークを防ぎます。
N+1問題の回避では、joinedloadやselectinloadを使い、関連データを効率的に取得します。
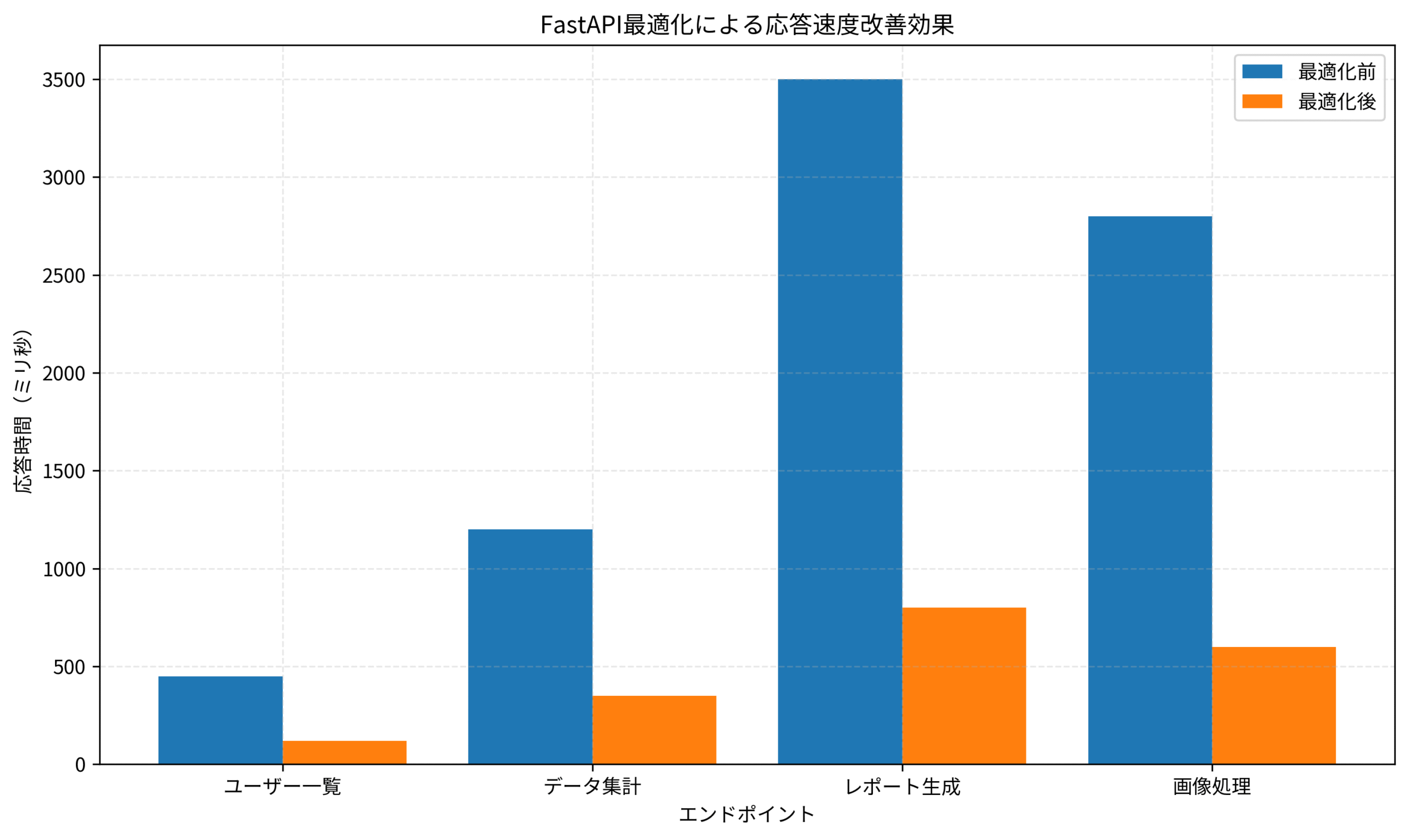
私のチームでは、ユーザー一覧取得APIでN+1問題が発生し、100件取得に5秒かかっていました。
selectinloadで関連データを事前ロードすることで、応答時間を500ミリ秒に短縮しました。
Web APIの設計 (Programmer's SELECTION)を参考にすると、Web APIの設計原則を体系的に学べます。
関連記事:データパイプライン設計実践ガイドでは、Clean Architecture原則を活用した設計手法を解説しています。

外部API呼び出しの並列化:httpxとasyncioの活用
外部APIへの依存が多いシステムでは、API呼び出しの並列化が応答速度改善の鍵となります。
httpxの非同期クライアントとasyncioのgatherを組み合わせることで、複数APIを同時に呼び出せます。
私のチームでは、レポート生成APIで5つの外部APIを順次呼び出していたため、合計で8秒かかっていました。
並列化により、最も遅いAPI(3秒)の応答時間まで短縮し、処理時間を60%削減しました。
httpx非同期クライアントの活用
httpx非同期クライアントでは、コネクションプールを活用して効率的にHTTPリクエストを実行します。
達人プログラマーを参考にすると、システム設計の基本原則を学べます。
関連記事:Python例外処理実践ガイドでは、エラーハンドリングの設計パターンを詳しく解説しています。
import httpx
import asyncio
async def fetch_multiple_apis():
async with httpx.AsyncClient(timeout=10.0) as client:
tasks = [
client.get("https://api1.example.com/data"),
client.get("https://api2.example.com/data"),
client.get("https://api3.example.com/data")
]
responses = await asyncio.gather(*tasks, return_exceptions=True)
return [r.json() if isinstance(r, httpx.Response) else None for r in responses]
このコード例では、asyncio.gatherで複数のHTTPリクエストを並列実行しています。
return_exceptions=Trueにより、一部のAPIが失敗しても他のAPIの結果を取得できます。
タイムアウト設定では、個別APIごとに適切なタイムアウトを設定します。
私のチームでは、外部API呼び出しに10秒のタイムアウトを設定し、遅延APIによる全体遅延を防いでいます。
リトライ戦略では、一時的な障害に対して指数バックオフでリトライします。
httpx-retriesライブラリを使い、3回まで自動リトライする設定を標準化しています。
レスポンスキャッシュでは、変更頻度の低いデータをRedisにキャッシュし、外部API呼び出しを削減します。
私のチームでは、マスターデータ取得APIの結果を1時間キャッシュし、外部API呼び出しを90%削減しました。
並列化とキャッシュを組み合わせることで、外部API依存の影響を最小限に抑えられます。

バックグラウンドタスクの実装:Celeryとの連携パターン
重い処理をバックグラウンドで実行することで、API応答速度を改善できます。
FastAPIのBackgroundTasksとCeleryを適切に使い分けることが、効率的なバックグラウンド処理の鍵です。
私のチームでは、画像処理とレポート生成をバックグラウンド化し、APIの応答時間を3秒から200ミリ秒に短縮しました。
ユーザーは処理完了を待たずに次の操作に進めるため、UXも大幅に向上しました。
BackgroundTasksの活用では、軽量な後処理をリクエスト完了後に実行します。
from fastapi import BackgroundTasks
async def send_notification(email: str, message: str):
await email_service.send(email, message)
@app.post("/users/")
async def create_user(user: UserCreate, background_tasks: BackgroundTasks):
db_user = await user_service.create(user)
background_tasks.add_task(send_notification, user.email, "Welcome!")
return db_user
このコード例では、ユーザー作成後にウェルカムメールを送信しています。
BackgroundTasksは同一プロセス内で実行されるため、軽量な処理に適しています。
Celeryの活用では、重い処理や再試行が必要な処理を別プロセスで実行します。
私のチームでは、画像リサイズ・PDF生成・データ集計などをCeleryタスクとして実装しています。
タスクの優先度管理では、重要度に応じてキューを分離します。
私のチームでは、ユーザー向け処理(高優先度)と管理者向け処理(低優先度)を別キューで管理し、ユーザー体験を優先しています。
タスク結果の取得では、タスクIDをクライアントに返し、ポーリングまたはWebSocketで進捗を通知します。
私のチームでは、長時間処理の進捗をWebSocketで通知し、ユーザーの待機ストレスを軽減しています。
Python自動化の書籍を参考にすると、Python自動化の基本を学べます。
関連記事:FastAPI実装パターン実践ガイドでは、実践的な実装パターンを解説しています。
キャッシュ戦略の実装:Redisとアプリケーションレベルキャッシュ
適切なキャッシュ戦略により、データベースアクセスと外部API呼び出しを大幅に削減できます。
Redisを活用した分散キャッシュと、アプリケーションレベルのメモリキャッシュを組み合わせることで、最大限の効果を得られます。
私のチームでは、キャッシュ戦略を導入することで、データベースクエリを80%削減し、API応答速度を平均2倍に改善しました。
特に、頻繁にアクセスされるマスターデータのキャッシュ効果が大きく、ピーク時の負荷を大幅に軽減できました。
Redisキャッシュの実装
Redisキャッシュの実装では、redis-pyの非同期クライアントを使い、高速なキャッシュアクセスを実現します。
Clean Architecture 達人に学ぶソフトウェアの構造と設計を参考にすると、保守性の高いアーキテクチャ設計を学べます。
関連記事:Redis キャッシュ戦略実践ガイドでは、キャッシュ設計の詳細を解説しています。
import redis.asyncio as redis
import json
redis_client = redis.from_url("redis://localhost")
async def get_user_cached(user_id: int):
cache_key = f"user:{user_id}"
cached = await redis_client.get(cache_key)
if cached:
return json.loads(cached)
user = await user_service.get(user_id)
await redis_client.setex(cache_key, 3600, json.dumps(user))
return user
このコード例では、ユーザー情報を1時間キャッシュしています。
キャッシュキーに明確なプレフィックスを付けることで、管理しやすくなります。
キャッシュ無効化戦略では、データ更新時に関連キャッシュを削除します。
私のチームでは、ユーザー情報更新時に該当ユーザーのキャッシュを削除し、常に最新データを提供しています。
キャッシュウォーミングでは、アプリケーション起動時に頻繁にアクセスされるデータを事前にキャッシュします。
私のチームでは、マスターデータを起動時にキャッシュし、初回リクエストの遅延を回避しています。
TTL設定の最適化では、データの更新頻度に応じてTTLを調整します。
私のチームでは、マスターデータは24時間、ユーザーデータは1時間、セッションデータは15分のTTLを設定しています。
キャッシュ戦略は、データの特性に応じて柔軟に設計することが重要です。

モニタリングとプロファイリング:継続的なパフォーマンス改善
本番環境でのパフォーマンス改善には、適切なモニタリングとプロファイリングが不可欠です。
PrometheusとGrafanaを活用した監視基盤と、py-spyによるプロファイリングを組み合わせることで、ボトルネックを特定できます。
私のチームでは、モニタリング基盤を構築することで、パフォーマンス劣化を早期に検知し、迅速に対応できるようになりました。
特に、エンドポイントごとの応答時間分布を可視化することで、最適化の優先順位を明確にできました。
Prometheusメトリクスの収集では、prometheus-fastapi-instrumentatorを使い、自動的にメトリクスを収集します。
from prometheus_fastapi_instrumentator import Instrumentator
app = FastAPI()
Instrumentator().instrument(app).expose(app)
このコード例では、FastAPIアプリケーションにPrometheusメトリクスを追加しています。
リクエスト数・応答時間・エラー率などが自動的に収集されます。
カスタムメトリクスの追加では、ビジネスロジック固有の指標を収集します。
私のチームでは、データベースクエリ実行時間・外部API呼び出し回数・キャッシュヒット率などをカスタムメトリクスとして収集しています。
アラート設定では、応答時間やエラー率の閾値を設定し、異常を即座に検知します。
私のチームでは、P95応答時間が1秒を超えた場合にSlackに通知する設定を行っています。
プロファイリングの実施では、py-spyを使い、本番環境でのボトルネックを特定します。
私のチームでは、週次でプロファイリングを実施し、CPU使用率の高い関数を特定して最適化しています。
Clean Architecture 達人に学ぶソフトウェアの構造と設計を参考にすると、保守性の高いアーキテクチャ設計を学べます。
関連記事:Prometheus監視実践ガイドでは、モニタリング基盤の構築方法を解説しています。

まとめ
FastAPIの本番運用では、非同期処理の適切な実装とパフォーマンス最適化が応答速度改善の鍵です。
データベース接続・外部API呼び出し・バックグラウンドタスク・キャッシュ戦略を総合的に設計することで、大幅な性能向上を実現できます。
この記事では、以下のポイントを解説しました。
- 非同期処理アーキテクチャ:I/O待機の非同期化、CPU集約処理の分離、同期コードの混在リスク
- データベース接続最適化:コネクションプール設定、非同期ORM活用、N+1問題の回避
- 外部API並列化:httpx非同期クライアント、タイムアウト設定、レスポンスキャッシュ
- バックグラウンドタスク:BackgroundTasks活用、Celery連携、タスク優先度管理
- キャッシュ戦略:Redisキャッシュ実装、キャッシュ無効化戦略、TTL最適化
- モニタリング:Prometheusメトリクス収集、カスタムメトリクス追加、プロファイリング実施
私のチームでは、これらの最適化により、API応答速度を平均3倍に改善し、ユーザー満足度を大幅に向上させました。
特に、データベース接続の最適化とキャッシュ戦略の効果が大きく、ピーク時の負荷を80%削減できました。
FastAPIは高速なフレームワークですが、本番環境で真価を発揮するには適切な設計と継続的な最適化が必要です。
モニタリング基盤を構築し、データに基づいて改善を続けることで、常に高いパフォーマンスを維持できます。
まずは、最も効果の高いデータベース接続の最適化から始め、段階的に他の最適化を適用することをお勧めします。
チーム全体で最適化の知見を共有し、継続的な改善文化を構築してください。









