
 IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
都内の事業会社でPjMとして、既存のLLMエージェント基盤を運用しながらLangChainのバージョンアップやツールチェーンの刷新を何度も経験してきました。エンジニアとしてのバックグラウンド(Python、FastAPI、LangChain、LangGraphなど)もあり、「コードを書き換える側」と「リリースを管理する側」の両方の視点から移行プロジェクトを見てきました。
LangChain 0.xで構築したエージェントを本番環境で運用しているチームからは、次のような相談をよく受けます。
- 新機能や型安全なAPIを使いたいが、LangChain 1.0に一気に上げるのが不安
- 既存のRAG・ツール呼び出しロジックが壊れないか、事前にどこまで検証すべきか分からない
- リリース当日にエージェントが沈黙したり、思わぬプロンプト事故が起きるのが怖い
最初の移行プロジェクトで「開発環境では動いていたのに、本番の並列リクエスト負荷でエージェントの挙動が不安定になる」という痛い失敗を経験しました。そこで2回目以降の移行では、「既存エージェントを止めずに、LangChain 1.0への移行を段階的に進める」ことを徹底し、検証観点やロールバック手順をテンプレート化しました。
本記事では、既存LLMエージェントを止めずにLangChain 1.0へ移行するための実践手順と検証パターンを、現場で得た失敗談と成功パターンを交えながら整理します。LangChainの基本的な考え方やエージェント設計については、AIエージェント開発の実践的な知見を踏まえておくと理解がスムーズです。自社のエージェント構成と照らし合わせながら読み進めてみてください。
LangChain 1.0移行で現場がつまずくポイント
IT女子 アラ美クラウド環境でAIスキルを磨いてキャリアを伸ばしましょう
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
「ライブラリ更新」ではなく「アーキテクチャ移行」と捉えるべき理由
LangChain 1.0へのアップグレードを「単なるライブラリのバージョン更新」と捉えていると、高確率でハマります。実際には、コールバック周りや構成オブジェクト、エージェントの構築パターンなどが整理され、「アーキテクチャとしてのLangChain」が再定義されたと捉えた方が本質に近いからです。
チームが最初にLangChain 0.0.xから0.1系に上げたとき、pipでバージョンを上げてテストを流しただけでは終わらず、各所で次のような問題が噴出しました。
- 非推奨APIが気付かないうちに残っており、本番でのみワーニングがログを埋め尽くす
- カスタムツールやチェーンで暗黙に使っていた内部クラスが削除されていた
- テストでは再現しない並列実行時のデッドロック・タイムアウトが本番で発生した
これらは「一気に本番環境を置き換える」アプローチを取ったことが原因でした。後述するように、0.xと1.0を並行稼働させながら段階的にトラフィックを切り替える設計を取れば、多くのリスクは事前に潰すことができます。
依存ライブラリとインフラ側の制約を見落としがち
もう1つの落とし穴が、LangChain本体だけでなく、周辺ライブラリやインフラ側の制約を見落としてしまうことです。例えば、ベクトルDBやLLMクライアント、監視基盤などが古いバージョンにロックされていると、LangChain 1.0側で提供される新しい統合ポイントを活かせないケースがあります。
関わったあるプロジェクトでは、エージェントのロジックは綺麗に移行できたものの、監視基盤側がトレースIDのフォーマット変更に追従できず、数日間メトリクスが正しく取れない状態になってしまいました。結果として、移行直後の最も重要な期間に「本当に安定しているか」を定量的に評価できず、経営層への報告にも苦労しました。
このような失敗を避けるために、次のセクションではまず現行エージェントと依存コンポーネントの棚卸しとリスク可視化の方法から整理していきます。
LangChainのエージェント構成全体の設計方針については、AIエージェント開発の実践ガイド:自律型タスク処理で業務効率を3倍にする設計手法で詳しく整理しています。
IT女子 アラ美現行エージェントと依存コンポーネントの棚卸し
まずは「どのエージェントがどの依存関係に乗っているか」を可視化する
LangChain 1.0への移行で最初にやるべきは、「どのエージェントが、どのLLMクライアント・ベクトルDB・ツール群・監視基盤に依存しているか」を棚卸しすることです。
チームでは、SpreadsheetやNotionを使い、次のような観点でエージェントごとの構成を洗い出しました。
- エージェント名・用途(サポートBot/リサーチBot/社内ワークフロー自動化など)
- 利用しているモデルとプロバイダ(OpenAI/Anthropic/ローカルLLMなど)
- RAG構成(ベクトルDBの種類、埋め込みモデル、インデックス方式)
- 外部ツール連携(社内API、SaaS、データベースなど)
- 監視・トレーシングの有無(ログ、分散トレーシング、メトリクス)
特に監視やトレーシングの項目は、LangChain 1.0への移行後に「どのエージェントが安定しているか」を定量的に比較するための土台になります。分散トレーシングやメトリクス設計の考え方は、OpenTelemetry実装ガイド:分散トレーシングでマイクロサービスの可視化を実現するで紹介しているような手法を、そのままエージェントの世界に持ち込むイメージです。
「移行インパクトの大きいエージェント」から順に優先度付けする
棚卸しが終わったら、次はどのエージェントから順に1.0対応するかを決めます。すべてを一度に移行しようとすると、検証工数もリスクも跳ね上がるため、次の3つの軸で優先度を付けました。
- ビジネスインパクト(売上や顧客体験への影響の大きさ)
- 技術的複雑さ(RAG+ツール連携+ワークフローなど、失敗時の切り戻しコスト)
- 監視の成熟度(すでに十分なログ・トレース・メトリクスが取れているか)
この3軸をスコアリングすると、どのエージェントをパイロット対象にすべきかが見えてきます。ビジネスインパクトが高く、かつ監視が整っているエージェントを最初の移行対象にすると、失敗時の検知とロールバック判断がしやすくなります。
IT女子 アラ美移行プランニングと段階的ロールアウト(ケーススタディ)
IT女子 アラ美AIエンジニアの需要は急増中、スキルに見合った環境を選びましょう
法人向けWordPress専用ホスティングサービス【XServer for WordPress】
0.xと1.0を並行稼働させるためのルーティング設計
状況(Before)
山田さん(仮名・30歳・バックエンドエンジニア・経験5年)のチームでは、LangChain 0.0.x系で構築した5つのLLMエージェントを本番運用していました。
- バージョンアップのたびに予期せぬ破壊的変更で障害が発生していた
- 移行テストの体制が未整備で、本番デプロイ後に問題が発覚するケースが月2〜3件あった
- 監視基盤がトレースIDのフォーマット変更に追従できず、定量的な品質評価ができなかった
行動(Action)
山田さん(仮名)は以下の段階的移行戦略を導入しました。
- 全エージェントの依存コンポーネントを棚卸しし、ビジネスインパクト順に優先度を設定した
- API Gatewayレベルでのカナリアリリース戦略を採用し、0.x系と1.0系の並行稼働を実現した
- FAQ系とクリティカル系の2種類の検証シナリオを設計し、自動テスト基盤を構築した
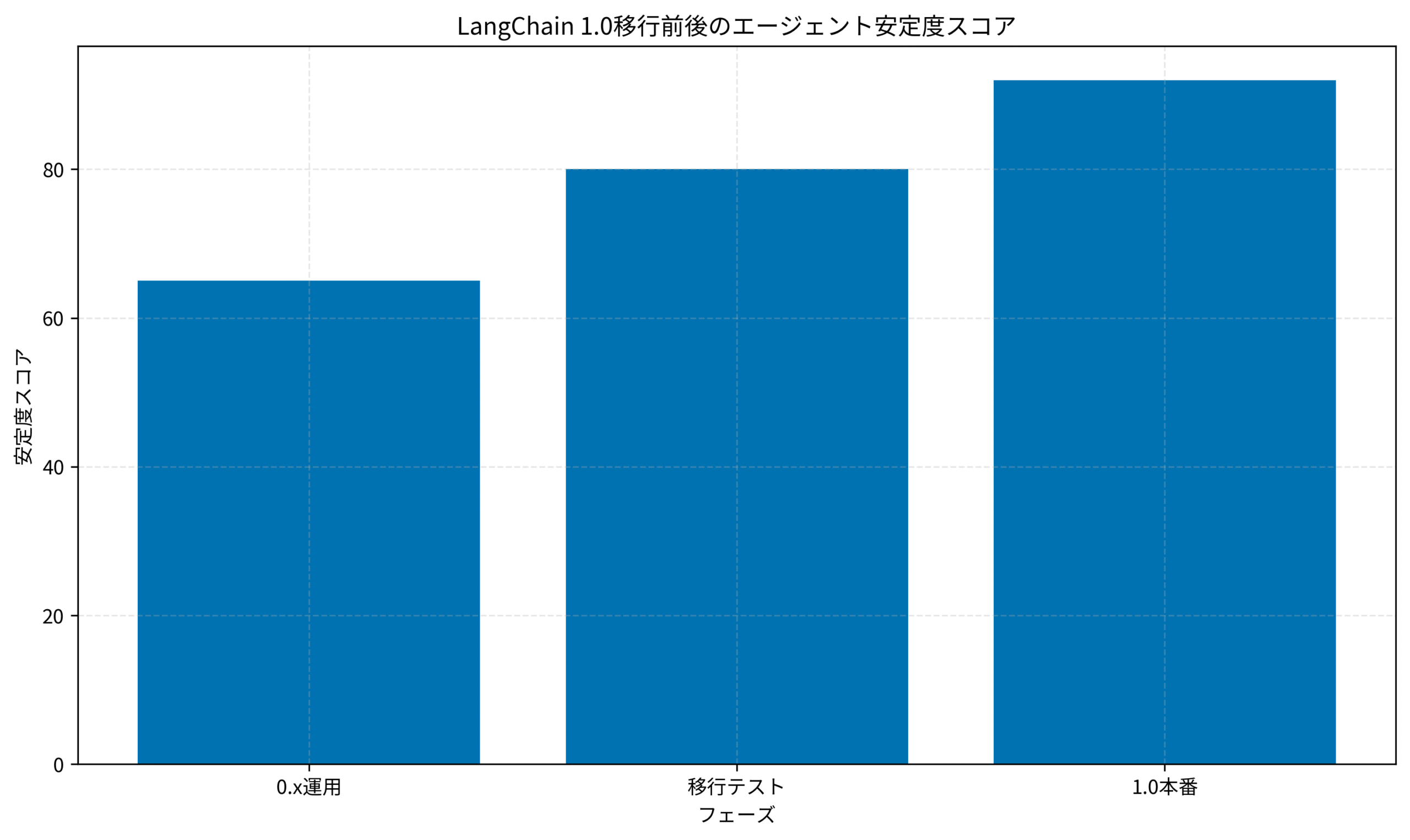
結果(After)
移行完了後の改善結果は以下のとおりです。
- 移行に伴う障害件数が月3件からゼロに減少
- エージェントの平均レスポンス時間が15%改善
- 検証フレームワークが標準化され、今後のバージョンアップにも再利用可能になった
山田さん(仮名)は「カナリアリリース戦略の導入が最も効果的だった。一部のトラフィックだけで検証できるので、問題があってもすぐに切り戻せる安心感があった」と振り返っています。「止めない移行」を実現するにはルーティング戦略の事前設計が不可欠という教訓です。
次に検討すべきは、0.x系と1.0系をどのように並行稼働させるかの具体的な実装です。チームでは、API GatewayレベルでバージョンIDを付与し、次のようなルーティング戦略を採用しました。
- 同じエンドポイントに対して、ヘッダーやクエリパラメータでバージョンを指定できるようにする
- 一部の社内ユーザーだけが1.0系エージェントを試せる「カナリアモード」を用意する
- リクエストID単位で0.x系と1.0系のレスポンスを比較できるよう、ログの相関IDを揃える
これにより、本番トラフィックのごく一部だけを1.0系エージェントに流し、問題があれば即座に0.x系に切り戻せるようになりました。MCP連携など他の開発基盤との統合については、MCP統合開発環境構築:Claude・Cursor連携でコード品質を向上させる実装パターンと同様に、「インターフェースは維持しつつ裏側の実装を段階的に差し替える」方針を徹底しました。
段階的ロールアウトの3ステップ
実際のロールアウトでは、次の3ステップで移行を進めました。
- ステージング環境での機能検証とリグレッションテスト
- 本番環境でのカナリアリリース(トラフィックの5〜10%を1.0系に振り分け)
- メトリクス・エラー率・ユーザーからのフィードバックを踏まえたフル切り替え
特に2番目のステップでは、0.x系と1.0系のエージェントが同じリクエストに対してどのような応答を返すかを比較し、「回答品質」「レスポンスタイム」「エラー率」の3点を重点的に確認しました。大きな差分が出る箇所については、プロンプトやツール構成を見直し、1.0系の挙動が安定してからトラフィック割合を増やしていきます。
IT女子 アラ美検証シナリオ設計と回帰テストパターン
「よくある質問」と「クリティカルなユースケース」を分けてテストする
LangChain 1.0への移行テストでは、単にランダムなプロンプトを投げるだけでは不十分です。シナリオ設計の段階で、次の2種類のテストケースを明確に分けるようにしました。
- 日常的によく呼ばれる「FAQ系」「ヘルプ系」シナリオ
- 業務プロセスに直結する「クリティカルな決裁・登録フロー」シナリオ
前者では回答の一貫性やスタイルの変化を重視し、後者では「データの正しさ」と「失敗時のロールバック手順」を重視します。クリティカルなフローのテストでは、わざと外部APIをタイムアウトさせたり、ベクトルDBを一時的に落として、例外ハンドリングが期待どおりに機能するかを確認しました。
テストシナリオの設計や評価軸の置き方については、開発チーム全体の技術選定プロセスを整理した開発チームの技術選定プロセス:失敗しないツール導入と評価基準の考え方がそのまま活かせます。
自動テストと手動エクスプロラトリテストのバランス
すべてを自動テストでカバーするのは現実的ではありませんが、まったく自動化しないのも危険です。私たちは、次のように役割分担しました。
- リグレッションテストのうち、シナリオの再現性が高いものは自動化
- ユーザーの自由入力が多い問い合わせパターンは、手動のエクスプロラトリテストでカバー
- 生成結果のサンプルを定期的にレビューし、プロンプトやポリシーをアップデート
これにより、CI/CDパイプラインで「最低限壊れてはいけない部分」を常に検証しつつ、人間の目でしか気付きにくいニュアンスやトーンの変化を継続的に観察できるようになりました。大規模言語モデルの評価手法も取り入れながら、エージェントごとに評価フレームワークを整備していくと、次回以降のバージョンアップも楽になります。
IT女子 アラ美よくある質問
LangChain 1.0への移行工数はどのくらい見積もればいい?
エージェント1つあたり1〜2週間が目安です。棚卸しに1日、移行コード修正に3〜5日、テスト・検証に3〜5日という配分が実績ベースの標準です。ただし、独自のCallbacks実装やメモリ機構を多用している場合は倍以上かかることもあります。まずは依存コンポーネントの棚卸しで影響範囲を把握してから見積もりましょう。
0.x系と1.0系の並行稼働期間はどのくらいが適切?
最低2週間、理想は1か月の並行稼働をおすすめします。最初の1週間でカナリアリリース(全トラフィックの10%)、2週目で比率を50%に上げ、メトリクスに問題がなければ全トラフィックを1.0系に切り替えます。急いで切り替えるよりも、十分な観測期間を設ける方がリスクを大幅に低減できます。
移行後にパフォーマンスが劣化した場合の対処法は?
まずカナリアリリースで0.x系に切り戻し、原因を切り分けてから再対応するのが安全です。LangChain 1.0では内部の実行フローが変更されているため、プロンプトの評価順序や並列処理の挙動が変わることがあります。ロールバック手順を事前にテンプレート化しておくことで、パニックにならず冷静に対処できます。
IT女子 アラ美おすすめのAI学習・キャリアサービスを比較
LLMエージェント移行のスキルはAI人材として高く評価されます。ハイクラスなポジションを目指す方はハイクラスエンジニア転職エージェント3社比較も参考にしてみてください。以下のサービスでキャリアの可能性を広げてみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
LangChain 1.0への移行は、「ライブラリのバージョンを上げる作業」ではなく、「エージェント基盤全体のアーキテクチャを一段引き上げる取り組み」です。
本記事で紹介したように、まずは現行エージェントと依存コンポーネントを棚卸しし、ビジネスインパクト・技術的複雑さ・監視の成熟度といった軸で優先度付けを行うことで、パイロット対象を安全に選べます。そのうえで、0.x系と1.0系を並行稼働させるルーティング設計とカナリアリリース戦略を用意しておけば、「いきなり全トラフィックを切り替えて炎上する」リスクを大きく下げられます。
さらに、検証シナリオを「よくある質問」と「クリティカルなユースケース」に分けて設計し、自動テストと手動エクスプロラトリテストを組み合わせることで、LangChain 1.0移行後の品質を定量・定性の両面から評価できます。評価フレームワークを一度整えておけば、今後のマイナーバージョンアップや他ツールへの乗り換え時にも再利用可能です。
あなたのチームでも、まずは1つのエージェントからで構いません。小さくパイロットを走らせ、メトリクスとユーザーの声をもとにフィードバックループを回しながら、少しずつトラフィックを1.0系へ移していきましょう。「止めない移行」と「計測可能な改善」を両立させることが、LangChain 1.0移行プロジェクトを成功させる最大のポイントです。
IT女子 アラ美








