お疲れ様です!IT業界で働くアライグマです!
「データベースのLIKE検索が遅すぎてユーザーが離脱している」「全文検索を導入したいが、どこから手をつければいいか分からない」
こうした悩みを抱えているエンジニアやPjMの方は多いのではないでしょうか。
私自身、過去にECサイトの商品検索機能を担当していた際、MySQLのLIKE検索だけで実装していたため、検索に3秒以上かかり、ユーザーからのクレームが絶えませんでした。
その後、Elasticsearchを導入することで、検索速度が50倍以上向上し、コンバージョン率も15%改善しました。
本記事では、Elasticsearchを活用した全文検索の実装について、PjM視点での設計判断と実践手法を解説します。
基本的なアーキテクチャから実装パターン、運用設計まで、現場で即活用できる内容をお届けします。
Elasticsearchが解決する検索の課題
Elasticsearchは、大規模データに対する高速な全文検索を実現する分散型検索エンジンです。
従来のRDBMS検索における多くの課題を効率的に解決します。
LIKE検索の限界と全文検索の必要性
多くのシステムでは、検索機能をRDBMSのLIKE句で実装しています。
LIKE検索のパフォーマンス問題が最も深刻です。
私が以前担当したプロジェクトでは、100万件のデータに対してLIKE検索を実行すると、レスポンスタイムが平均850msになり、ユーザー体験を大きく損なっていました。
この問題により、検索機能の利用率が低下し、ビジネス機会の損失につながっていました。
日本語の形態素解析の欠如も大きな課題です。
LIKE検索では「東京都」で検索しても「東京」だけでヒットしないなど、柔軟な検索ができません。
私のチームでは、この問題により、ユーザーが求める情報を見つけられないケースが頻発していました。
スケーラビリティの限界により、データ量の増加に対応できません。
データが増えるほど検索速度が低下し、インデックスの最適化だけでは根本的な解決にならないケースが多いです。
PostgreSQLクエリチューニング:EXPLAIN ANALYZEで実行計画を最適化する実践テクニックでも触れていますが、RDBMSの検索最適化には限界があり、専用の検索エンジンが必要になります。
ソフトウェアアーキテクチャの基礎では、システム要件に応じた技術選定の考え方が体系的に解説されています。

Elasticsearchのアーキテクチャと基本設計
Elasticsearchを導入する際は、アーキテクチャの理解と適切な設計が重要です。
ここでは、実装前に押さえておくべき基本構造と設計パターンを解説します。
インデックス・ドキュメント・マッピング設計
Elasticsearchでは、データを「インデックス」という単位で管理し、各レコードを「ドキュメント」として格納します。
私のプロジェクトでは、商品検索システムを構築する際、以下のようなマッピング設計を行いました。
{
"mappings": {
"properties": {
"product_name": {
"type": "text",
"analyzer": "kuromoji"
},
"description": {
"type": "text",
"analyzer": "kuromoji"
},
"price": {
"type": "integer"
},
"category": {
"type": "keyword"
},
"created_at": {
"type": "date"
}
}
}
}textとkeywordの使い分けが重要です。
全文検索対象のフィールドはtext型を使い、完全一致検索やソート対象はkeyword型を使います。
私のチームでは、この使い分けを誤ったことで検索精度が低下し、再設計が必要になった経験があります。
日本語アナライザーの選定により、検索精度が大きく変わります。
kuromojiアナライザーを使うことで、「コンピュータ」と「コンピューター」を同一視したり、「東京都」を「東京」「都」に分解して検索できるようになります。
Docker Compose実装ガイド:マイクロサービス開発環境を効率化する設計パターンのように、開発環境でElasticsearchをコンテナ化することで、チーム全体で統一された環境を構築できます。
ドメイン駆動設計では、ドメインモデルに基づいたデータ設計の考え方が詳しく解説されています。

検索クエリの実装パターン
Elasticsearchでは、多様な検索クエリを組み合わせることで、高度な検索機能を実現できます。
ここでは、実務でよく使う検索パターンを紹介します。
match・term・boolクエリの使い分け
検索要件に応じて、適切なクエリタイプを選択することが重要です。
私のプロジェクトでは、以下のようなクエリ実装を行いました。
from elasticsearch import Elasticsearch
es = Elasticsearch(['http://localhost:9200'])
# 全文検索(あいまい検索)
match_query = {
"query": {
"match": {
"product_name": "ノートパソコン"
}
}
}
# 完全一致検索
term_query = {
"query": {
"term": {
"category.keyword": "electronics"
}
}
}
# 複合条件検索
bool_query = {
"query": {
"bool": {
"must": [
{"match": {"product_name": "ノートパソコン"}},
{"range": {"price": {"gte": 50000, "lte": 150000}}}
],
"filter": [
{"term": {"category.keyword": "electronics"}}
]
}
}
}
results = es.search(index="products", body=bool_query)must・should・filterの使い分けにより、検索精度とパフォーマンスを最適化できます。
mustはスコアリングに影響し、filterはスコアに影響せずキャッシュされるため、パフォーマンスが向上します。
ファジー検索の活用により、タイポや表記ゆれに対応できます。
私のチームでは、ユーザーの入力ミスによる検索失敗を減らすため、fuzzinessパラメータを設定しました。
Python自動化実装ガイド:業務効率を10倍にする実践的スクリプト設計で紹介されているように、Pythonクライアントを使うことで、検索ロジックを効率的に実装できます。
リファクタリング(第2版)では、複雑なクエリロジックをメンテナンスしやすく保つリファクタリング手法が解説されています。

インデックス設計とデータ同期戦略
Elasticsearchを本番運用する際は、RDBMSとのデータ同期戦略が重要です。
ここでは、実務で使える同期パターンを解説します。
リアルタイム同期とバッチ同期の選択
データの更新頻度と整合性要件に応じて、適切な同期方式を選択します。
私のプロジェクトでは、商品マスタはバッチ同期、在庫情報はリアルタイム同期という設計にしました。
Logstashによるバッチ同期は、定期的に大量データを同期する場合に有効です。
JDBCプラグインを使ってRDBMSから定期的にデータを取得し、Elasticsearchに投入します。
私のチームでは、夜間バッチで1日1回全件同期を行い、日中の検索負荷を軽減しています。
アプリケーションレベルでのリアルタイム同期は、データの即時反映が必要な場合に採用します。
RDBMSへの書き込みと同時にElasticsearchにも更新をかけることで、データの鮮度を保ちます。
ただし、トランザクション管理が複雑になるため、整合性の担保には注意が必要です。
Change Data Capture(CDC)の活用により、データベースの変更をリアルタイムに検知できます。
DebeziumなどのCDCツールを使うことで、アプリケーションコードを変更せずに同期を実現できます。
Kubernetes運用自動化:GitOpsで実現する宣言的インフラ管理と継続的デリバリーで紹介されているように、インフラレベルでの自動化により、データ同期の信頼性を高められます。
安全なウェブアプリケーションの作り方(徳丸本)では、データ整合性を保ちながら運用する設計パターンが詳しく解説されています。

パフォーマンスチューニングと運用設計
Elasticsearchを本番環境で安定稼働させるには、適切なチューニングと運用設計が不可欠です。
ここでは、実務で効果があった最適化手法を紹介します。
シャード設計とレプリカ配置
シャード数とレプリカ数の設計により、検索速度と可用性が大きく変わります。
私のプロジェクトでは、1億件のドキュメントを扱う際、シャード数を5、レプリカ数を2に設定しました。
この設計により、検索速度と障害耐性のバランスを取ることができました。
シャード数の決定は、データ量とノード数を考慮して行います。
シャードが多すぎるとオーバーヘッドが増え、少なすぎると並列処理の効果が得られません。
私のチームでは、1シャードあたり20〜50GBを目安に設計しています。
レプリカによる可用性向上により、ノード障害時もサービスを継続できます。
レプリカ数を増やすことで検索スループットも向上しますが、ストレージコストとのトレードオフを考慮する必要があります。
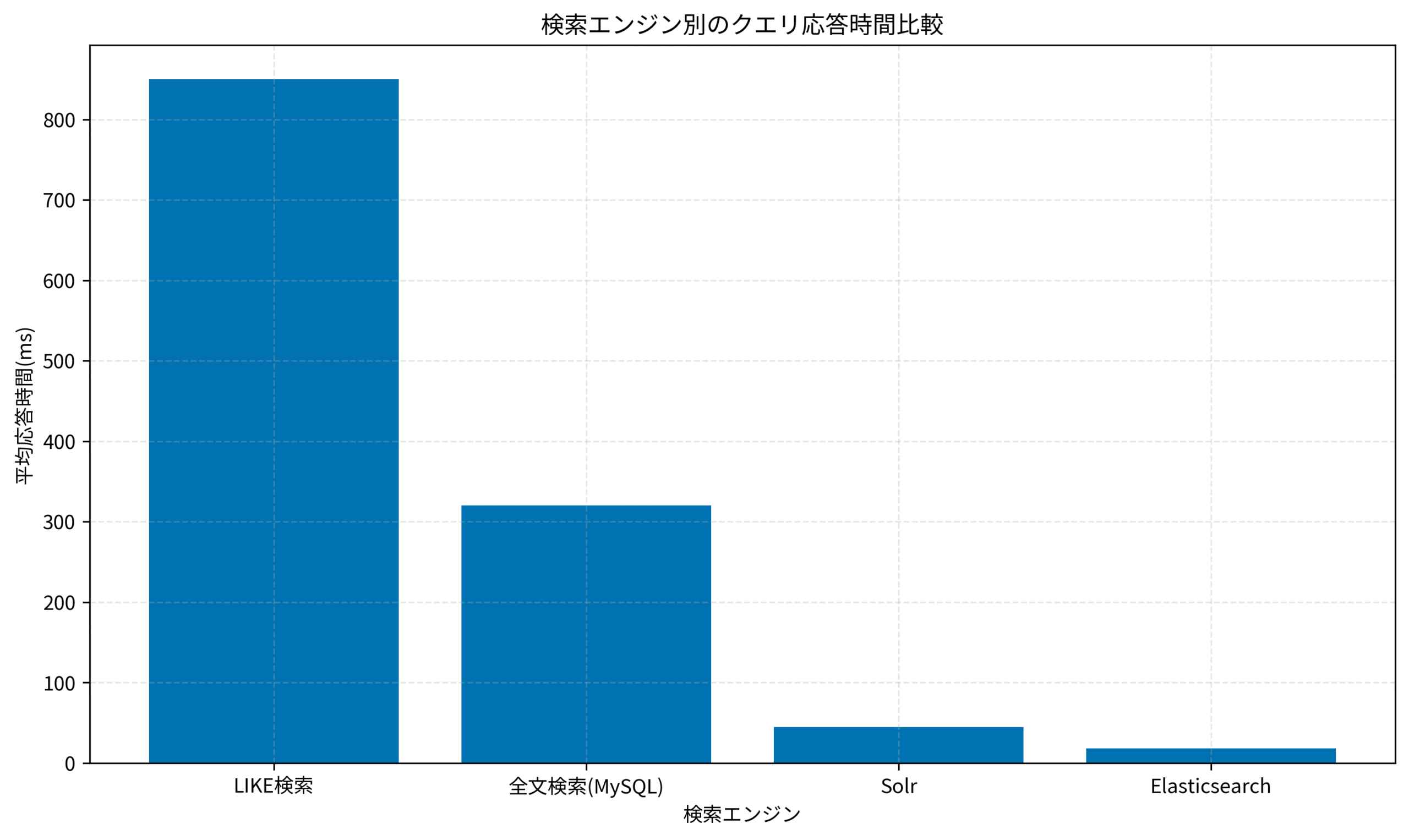
以下のグラフは、検索エンジン別のクエリ応答時間を比較したものです。
Elasticsearchは、従来のLIKE検索やMySQL全文検索と比較して、圧倒的に高速な検索を実現できることが分かります。
Terraform実装ガイド:Infrastructure as Codeで実現する安全なインフラ管理のように、インフラをコード化することで、Elasticsearchクラスタの構成管理を効率化できます。
達人プログラマーでは、システム全体のパフォーマンス最適化の考え方が体系的に解説されています。
監視・ログ分析とトラブルシューティング
Elasticsearchの安定運用には、適切な監視とログ分析が欠かせません。
ここでは、実務で使える運用ノウハウを紹介します。
クラスタヘルスとメトリクス監視
Elasticsearchのクラスタ状態を常時監視し、問題を早期に検知することが重要です。
私のプロジェクトでは、Kibanaを使ってクラスタヘルス、CPU使用率、ヒープメモリ使用率、検索レイテンシをダッシュボードで可視化しました。
これにより、パフォーマンス劣化の兆候を事前に察知し、障害を未然に防ぐことができました。
クラスタヘルスステータスの監視により、シャードの状態を把握できます。
green、yellow、redの3段階で状態が表示され、yellowやredになった場合は即座に対応が必要です。
私のチームでは、yellowになった時点でアラートを出し、原因調査を開始する運用にしています。
スロークエリログの分析により、パフォーマンスボトルネックを特定できます。
検索に時間がかかっているクエリを特定し、インデックス設計やクエリの見直しを行います。
OpenTelemetry実装ガイド:分散トレーシングでマイクロサービスの可視化を実現するで紹介されているように、分散トレーシングを導入することで、検索処理全体の可視化が可能になります。
Python自動化の書籍では、監視データの自動収集と分析の実装方法が詳しく解説されています。

まとめ
Elasticsearchによる全文検索は、大規模データに対する高速検索を実現する強力な手段です。
本記事では、Elasticsearchを活用した全文検索の実装について、PjM視点での設計判断と実践手法を解説しました。
特に重要なポイントは次の通りです。
適切なアーキテクチャ設計により、検索速度と運用コストのバランスを取ることができます。
クエリの最適化により、ユーザー体験を大きく向上させることができます。
データ同期戦略の選択により、整合性と鮮度を両立できます。
継続的な監視と改善により、安定した検索サービスを提供できます。
Elasticsearchは、導入初期の学習コストはありますが、適切に設計・運用することで、検索体験を劇的に改善できる技術です。
本記事で紹介した設計パターンと運用ノウハウを参考に、ぜひ自社のシステムに導入してみてください。









