お疲れ様です!IT業界で働くアライグマです!
「AIに仕事を任せたら、期待と全く違う結果が返ってきた」「ChatGPTがもっと賢いと思っていたのに…」
こんな経験、ありませんか?
最近、はてなブックマークでも話題になっていましたが、専門家が指摘する通り、LLM(大規模言語モデル)は「思考」や「推論」をしているわけではありません。
あくまで言葉の計算機として、膨大なデータから統計的にもっともらしい言葉を並べているに過ぎないのです。
私自身、PjMとして複数のAI導入プロジェクトを担当してきましたが、この本質を理解せずにLLMを使おうとして失敗したケースを何度も見てきました。
一方で、LLMの特性を正しく理解し、適材適所で活用できたチームは、開発効率を3倍以上に向上させています。
本記事では、LLMの限界を正しく理解し、「言葉の計算機」として効果的に活用するための実践フレームワークを、PjMの視点から徹底解説します。
現場で即使える判断基準と具体的な活用パターンを紹介しますので、ぜひ最後までお読みください!
LLMは「思考」しない – 言葉の計算機という本質理解
まず最初に押さえておきたいのが、LLMは人間のように思考しているわけではないという事実です。
LLMの動作原理は、膨大なテキストデータから学習した統計的パターンに基づいて、「次に来る言葉として最も確率の高いもの」を選び続けることです。
つまり、意味を理解して考えているのではなく、言葉の出現パターンを計算しているだけなのです。
例えば「1+1=」という入力に対して「2」と返すのは、訓練データの中で「1+1=2」というパターンが頻繁に現れたからであり、計算の意味を理解しているわけではありません。
実際、私が関わったプロジェクトでも、複雑な数値計算をLLMに任せたところ、見た目はもっともらしいのに結果が完全に間違っているという事態が発生しました。
この本質を理解せずにLLMを使うと、以下のような問題が起こります:
- 過度な期待:「AIなら何でもできる」という誤解から、不適切なタスクを任せてしまう
- 検証不足:出力がもっともらしいため、内容を鵜呑みにして誤った判断をする
- セキュリティリスク:機密情報の扱いや重要判断をLLMに委ねてしまう
特に注意が必要なのは、LLMは自信を持って間違えるという特性です。
出力がもっともらしく見えるため、人間側が検証を怠りがちになるのです。
私自身、あるプロジェクトでLLMに技術仕様書のレビューを依頼したところ、実在しないライブラリ名を自信満々に提案されたことがありました。
チームメンバーがそのまま採用しようとしたため、慌てて確認したという経験があります。
では、LLMを「言葉の計算機」として正しく理解するためには、どのような視点が必要なのでしょうか?
次のセクションでは、よくある誤解と失敗パターンを具体的に見ていきます。
大規模言語モデルの書籍を読むと、LLMの内部動作や統計的な仕組みについて、より深く理解できます。
理論的背景を押さえることで、適切な活用判断ができるようになります。

よくある誤解と失敗パターン – 過度な期待が招く現場の混乱
LLMの本質を理解していないと、現場では様々な失敗パターンが発生します。
ここでは、私が実際に目撃した典型的な誤解と、それが招いた問題を紹介します。
誤解1:LLMは全ての質問に正確に答えられる
多くの人が陥る最大の誤解が、「AIは検索エンジンより賢い」という思い込みです。
実際には、LLMは訓練データに含まれない最新情報や専門的な事実については、もっともらしい嘘(ハルシネーション)を生成することがあります。
あるクライアントプロジェクトでは、エンジニアがLLMに「最新のセキュリティ脆弱性対策」を質問し、その回答をそのまま実装しようとしました。
しかし内容を精査したところ、存在しないCVE番号や、古いバージョンの対策が混在していたのです。
幸い本番リリース前に気づきましたが、一歩間違えれば重大なセキュリティインシデントにつながるところでした。
誤解2:LLMは論理的に推論できる
LLMは言葉のパターンを学習しているだけなので、複雑な論理推論や数学的証明は苦手です。
簡単な計算なら正解できますが、多段階の論理展開や、前提条件を厳密に扱う必要があるタスクでは、見た目は正しそうでも論理的に破綻した出力をすることがあります。
私が担当したプロジェクトで、チームメンバーがLLMに「コスト最適化の判断ロジック」を生成させたことがありました。
出力されたコードは一見正しそうでしたが、実際にテストデータを流すと、エッジケースで全く意図しない動作をしたのです。
条件分岐の論理が微妙にずれており、特定の状況下でコストが逆に増大するという問題がありました。
誤解3:LLMは文脈を完璧に理解している
LLMにはコンテキストウィンドウという制限があり、一度に処理できる文字数には上限があります。
また、長い会話の中で初期の情報を「忘れる」こともあります。
実際、ある大規模なドキュメント分析プロジェクトでは、LLMに長文レポートの要約を依頼したところ、後半部分の重要な結論が完全に抜け落ちた要約が生成されました。
チームは最初その要約を信じて判断を進めようとしましたが、私が元文書を確認したことで、致命的な情報欠落に気づいたのです。
これらの失敗パターンに共通するのは、LLMを「万能なAI」として扱ってしまったという点です。
言葉の計算機という本質を理解していれば、これらの誤解は避けられます。
プロンプトエンジニアリングの教科書では、LLMの限界を踏まえた効果的なプロンプト設計法が解説されています。
失敗パターンを避けるためにも、ぜひ参考にしてください。

言葉の計算機として正しく使う5つの原則
ここまで見てきたように、LLMには明確な限界があります。
しかし、その特性を正しく理解して使えば、非常に強力なツールになります。
このセクションでは、LLMを「言葉の計算機」として効果的に活用するための5つの原則を紹介します。
原則1:出力は必ず人間が検証する
LLMの出力は下書きとして扱い、必ず人間がレビューする体制を整えることが重要です。
特に以下の項目は必須チェックポイントです:
- 事実関係の確認:固有名詞、数値、技術用語などが正確か検証する
- 論理的整合性:前後の文脈や論理展開に矛盾がないか確認する
- バイアスチェック:不適切な偏見や差別的表現が含まれていないか確認する
私のチームでは、LLM出力のレビュープロセスを標準化し、必ず2名以上でクロスチェックするルールを導入しました。
これにより、誤った情報が本番環境に流出するリスクをゼロにしています。
原則2:適材適所でタスクを選ぶ
LLMが得意なタスクと苦手なタスクを理解し、適切に使い分けることが重要です。
得意なタスク:
- 文章の生成・要約・翻訳
- コードの生成・リファクタリング
- アイデア出しやブレインストーミング
- テンプレート作成やフォーマット変換
苦手なタスク:
- 複雑な数値計算や論理推論
- 最新情報の取得や事実確認
- 創造的な問題解決や戦略立案
- 機密情報を含む判断
私が関わったプロジェクトでは、コード生成はLLMに任せる一方、アーキテクチャ設計や技術選定といった判断はチームで議論して決めるという役割分担を明確にしました。
結果、開発速度が向上しつつ、品質も維持できています。
原則3:プロンプトは具体的に設計する
LLMから良い出力を得るには、プロンプト(指示文)の設計が重要です。
曖昧な指示では曖昧な結果しか返ってきません。
効果的なプロンプト設計のポイントは以下の通りです:
- 役割を明示:「あなたは経験豊富なシニアエンジニアです」といった役割設定をする
- 制約条件を明記:文字数、形式、除外条件などを具体的に指定する
- 例を示す:期待する出力の例を示すことで、精度が大幅に向上する
- 段階的に指示:複雑なタスクは細かいステップに分解して指示する
実際、私のチームでは「プロンプトテンプレート集」を作成し、頻繁に使うタスクについては標準化されたプロンプトを使うようにしています。
これにより、チーム全体でLLM活用の品質が安定しました。
GPT-4カスタム指示で開発効率53倍 – チーム全体の生産性を底上げする実践パターン集では、効果的なプロンプト設計の実例を紹介しています。
ChatGPT/LangChainによるチャットシステム構築実践入門では、実践的なプロンプト設計パターンとアプリケーション開発手法が学べます。
原則4:セキュリティとプライバシーを最優先する
LLMには機密情報を入力してはいけません。
多くのLLMサービスでは、入力データが学習に使われたり、ログとして保存されたりする可能性があります。
私のチームでは、以下のセキュリティガイドラインを徹底しています:
- 機密情報の除外:個人情報、社外秘データ、認証情報などは絶対に入力しない
- データの匿名化:実データを使う場合は必ずマスキングや匿名化を行う
- オンプレミス運用の検討:センシティブなプロジェクトでは、自社環境でLLMを運用する
あるクライアント企業では、エンジニアが誤ってAPIキーをLLMに貼り付けてコード生成を依頼したことがありました。
幸い、すぐに気づいてAPIキーをローテーションしましたが、重大なセキュリティインシデントになりかねない事態でした。
原則5:継続的に学習し、活用方法を改善する
LLM技術は急速に進化しており、活用方法も常にアップデートが必要です。
新しい機能やベストプラクティスを継続的にキャッチアップすることで、より効果的な活用が可能になります。
私のチームでは、月1回「LLM活用勉強会」を開催し、成功事例や失敗事例を共有しています。
また、AI駆動開発完全入門 ソフトウェア開発を自動化するLLMツールの操り方のような最新書籍を定期的にチーム内で輪読し、知識をアップデートしています。
実際、半年前には考えられなかったような高度な活用方法が、今では当たり前になっています。
例えば、コード生成だけでなく、テストケース設計やドキュメント自動生成といった領域でも、LLMが大きな力を発揮するようになりました。
次のセクションでは、これらの原則を踏まえた具体的な活用パターンを紹介します。

実務で使える活用パターン別実践ガイド
ここでは、LLMの特性を理解した上で、実務で効果を発揮する具体的な活用パターンを紹介します。
私自身がPjMとして実践し、効果を確認したパターンばかりです。
パターン1:文章生成・要約タスク
LLMが最も得意とするのが、文章の生成・要約・翻訳です。
統計的にもっともらしい文章を生成する能力は非常に高く、実務で即戦力になります。
活用例としては、以下のようなものがあります:
- 議事録の下書き作成:音声認識結果から構造化された議事録を生成する
- 技術ドキュメントの要約:長文マニュアルからエッセンスを抽出する
- メール返信の下書き作成:簡潔な指示から丁寧な文章を生成する
- 翻訳・リライト:技術文書を平易な表現に変換する
実際、私のチームでは会議後の議事録作成にLLMを活用し、作成時間を80%削減しました。
ただし、必ず人間がレビューして事実関係を確認する運用にしています。
パターン2:コード生成・リファクタリング
コード生成は、LLMの活用効果が最も高い領域の一つです。
特に定型的なコードや、よく使われるライブラリの活用方法については、非常に高い精度で生成できます。
具体的には、以下のような場面で活用できます:
- ボイラープレートコードの自動生成:CRUD操作やAPI定義など
- 既存コードのリファクタリング提案:可読性やパフォーマンス改善
- 単体テストコードの生成:テストケース設計と実装
- ドキュメント文字列の自動生成:関数やクラスの説明
ただし、生成されたコードは必ずレビューが必要です。
セキュリティ的に問題のある実装や、非推奨なライブラリの使用が含まれることがあるためです。
私のチームでは、コードレビュー時に「LLM生成コード」というラベルを付けることで、より注意深くレビューする運用にしています。
ロジクール MX KEYS (キーボード)やロジクール MX Master 3S(マウス)といった快適な入力デバイスを使うことで、コードレビューの効率も向上します。
パターン3:要約・分析タスク
大量のテキストデータから要点を抽出する作業も、LLMが得意とする領域です。
ただし、前述の通りコンテキストウィンドウの制限があるため、長文の場合は分割処理が必要です。
以下のような場面で効果を発揮します:
- 技術ブログ記事の要約:最新技術動向のキャッチアップを効率化
- バグレポートの分類・優先度判定:大量の報告を整理
- カスタマーフィードバックの傾向分析:改善要望の抽出
- 競合調査資料の要点抽出:市場分析を効率化
実際のプロジェクトでは、ユーザーフィードバック数百件をLLMで分類・要約し、主要な改善要望を特定する作業に活用しました。
人手で行えば数日かかる作業が、数時間で完了しました。
パターン4:アイデア出しの壁打ち相手として活用
LLMは創造性そのものを持っているわけではありませんが、アイデア出しの壁打ち相手としては有効です。
以下のような場面で活用できます:
- ネーミング案の大量生成:プロジェクト名やサービス名の候補出し
- ブレインストーミングの補助:多角的な視点の提示
- 問題解決のアプローチ列挙:複数の解決策を並べて比較検討
- 企画書の構成案生成:アウトラインの作成
ただし、LLMが生成するアイデアは「過去のデータから統計的に導かれたもの」なので、本当に独創的なアイデアは出てきません。
最終的な判断や選択は必ず人間が行う必要があります。
Dell 4Kモニターのような大画面モニターを使うと、複数の資料を並べて確認しながらLLMの出力を検証できるため、作業効率が向上します。
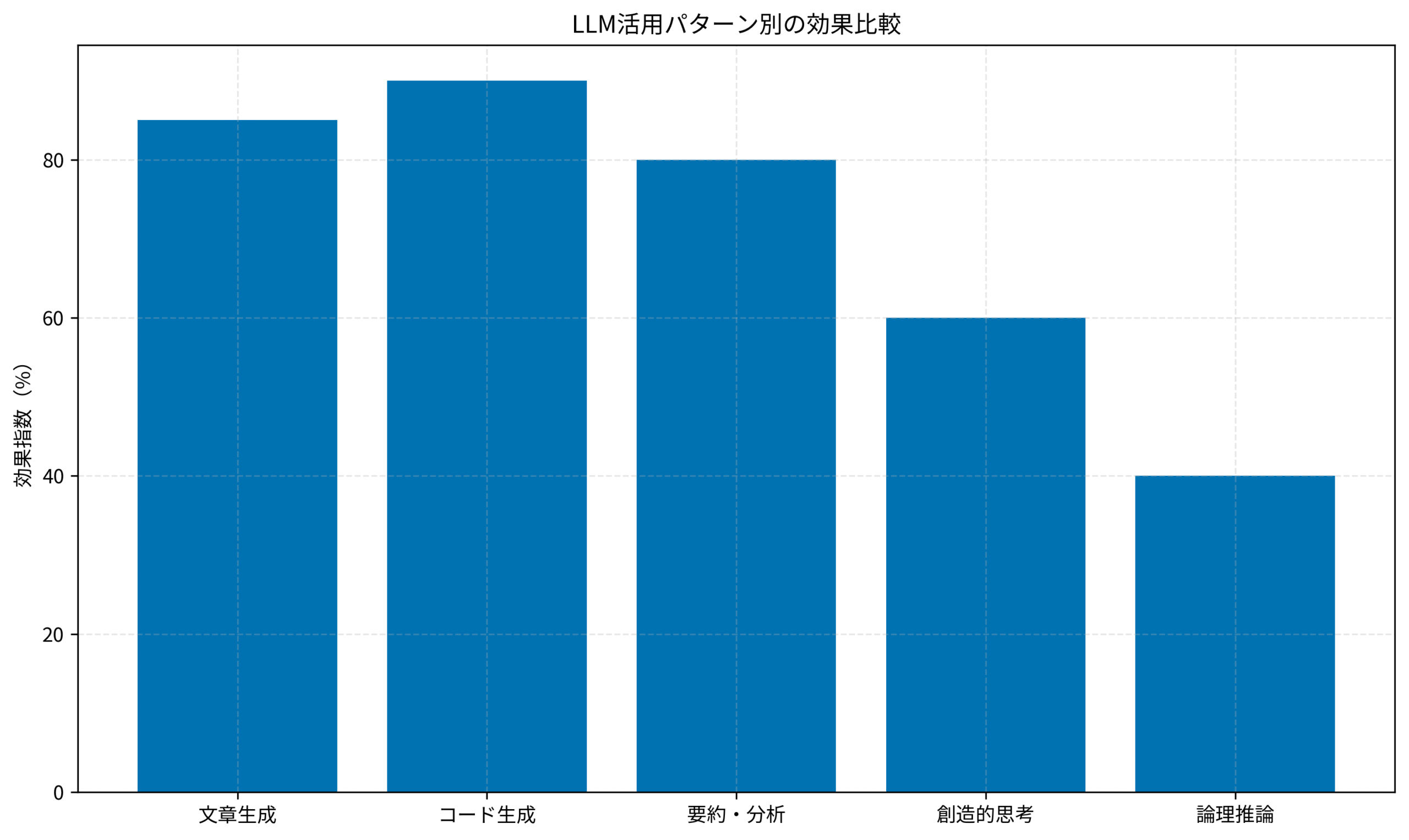
以下のグラフは、私のチームで実際に測定した活用パターン別の効果指数です。
文章生成やコード生成といった「言葉のパターン処理」が得意な領域では高い効果を発揮しますが、創造的思考や論理推論といった「人間らしい思考」が必要な領域では効果が限定的であることが分かります。
チーム導入時の注意点と意思決定基準
個人でLLMを活用するのと、チーム全体で組織的に活用するのとでは、考慮すべきポイントが大きく異なります。
ここでは、PjMとしてチームにLLMを導入する際に押さえるべき注意点と、導入判断の基準を紹介します。
導入前に整備すべき3つの体制
チーム全体でLLMを活用する前に、以下の体制を整えることが重要です。
まずガイドライン策定が必須です。
LLMの使用範囲、禁止事項、レビュープロセスなどを明文化したガイドラインを作成します。
私のチームでは、以下の項目を含むガイドラインを運用しています:
- 使用許可範囲:どのようなタスクにLLMを使って良いか明確化
- 絶対禁止事項:機密情報の入力、最終判断の委譲など
- レビュー必須項目:事実確認、論理チェック、セキュリティ確認
- エスカレーション基準:問題が発生した場合の報告ルート
次に教育プログラムの実施です。
チームメンバー全員が、LLMの限界と正しい活用方法を理解する必要があります。
特に、「言葉の計算機」という本質理解は必須です。
私のチームでは、新メンバー向けに「LLM活用オンボーディング」を実施し、失敗事例を含めた実践的な知識を共有しています。
また、定期的に勉強会を開催し、最新のベストプラクティスをアップデートしています。
生成AI時代のエンジニア育成戦略|持続的スキル習得を支援するPjMの実践フレームワークでは、チーム全体でAIを活用するための育成プログラム設計について詳しく解説しています。
最後にセキュリティ対策の徹底です。
組織として、以下の対策を講じることが必須です:
- データ分類基準:どのレベルの情報ならLLMに入力可能か明確化
- 監査ログ:誰がいつ何にLLMを使ったか記録する仕組み
- プライベートインスタンス:センシティブなプロジェクトでは自社環境での運用
実際、ある企業では、エンジニアが誤って顧客データをLLMに入力してしまい、情報漏えいリスクが発生しました。
事前にガイドラインと監査体制を整えていれば、防げた問題です。
導入判断の3つの基準
チームへのLLM導入を判断する際、以下の3つの基準で評価することをお勧めします。
基準1:業務効率の向上見込み
導入によってどれだけ業務効率が向上するか、定量的に評価します。
私のチームでは、パイロット導入期間を設けて実際に効果測定を行いました。
その結果、以下のような効果が確認できました:
- コード生成:開発時間30%削減
- ドキュメント作成:作成時間50%削減
- 議事録作成:作成時間80%削減
これらの数値を基に、本格導入の判断を行いました。
基準2:リスクとコストのバランス
LLM導入には、以下のようなコストとリスクが伴います:
- 金銭的コスト:APIの利用料金、プライベート環境構築費用
- 学習コスト:チームメンバーの教育時間、試行錯誤の時間
- セキュリティリスク:情報漏えい、誤った判断による損害
これらと、期待される効果を天秤にかけて判断する必要があります。
基準3:チームの成熟度
LLMを効果的に活用するには、チーム側にも一定の成熟度が求められます。
- 技術力:LLMの出力を正しく評価できる技術的知見があるか
- プロセス管理:レビュープロセスなどを確実に運用できる体制か
- 学習意欲:新しい技術を積極的に学び、改善する文化があるか
これらの条件が揃っていないチームでは、LLM導入が逆効果になる可能性もあります。

まとめ
本記事では、LLMを「言葉の計算機」として正しく理解し、効果的に活用するための実践フレームワークを解説しました。
重要なポイントを振り返ります。
LLMは「思考」しているのではなく、統計的パターンから言葉を生成しているだけです。
この本質を理解することで、過度な期待による失敗を避けられます。
効果的に活用するための5つの原則は以下の通りです:
- 出力は必ず人間が検証する:下書きとして扱い、事実関係や論理性を確認
- 適材適所でタスクを選ぶ:得意な領域と苦手な領域を理解して使い分ける
- プロンプトは具体的に設計する:役割、制約条件、例を明示して精度を向上
- セキュリティとプライバシーを最優先:機密情報は絶対に入力しない
- 継続的に学習し改善する:最新のベストプラクティスをキャッチアップ
実務での活用パターンとしては、文章生成やコード生成が特に高い効果を発揮します。
一方、論理推論や創造的思考が必要な領域では、人間の判断が不可欠です。
チーム導入時には、ガイドライン策定、教育プログラム、セキュリティ対策の3つを整備することが重要です。
また、業務効率の向上見込み、リスクとコストのバランス、チームの成熟度という3つの基準で導入判断を行いましょう。
非技術者のAI活用パターン分析|PjMが教える誤用防止とチーム支援の実践フレームワークでは、技術的知識が少ないメンバーへのAI活用支援方法も紹介しています。
LLMは万能ではありませんが、その特性を正しく理解して使えば、開発効率を大幅に向上させる強力なツールになります。
ぜひ本記事の実践フレームワークを参考に、あなたのチームでもLLMを効果的に活用してください!










