お疲れ様です!IT業界で働くアライグマです!
「正常系テストは完璧なのに、本番でエラーハンドリングの不備が見つかって緊急対応…」
「『動けばいいじゃん』というレビューコメントで、異常系テストが後回しになっている」
これらは、私がプロジェクトマネージャーとして最も頻繁に遭遇する品質問題の根本原因です。
2025年10月現在、はてなブックマークで「システムのテスト、『動けばいいじゃん』っていうときは高確率で異常系の考慮が漏れている」という記事が大きな反響を呼び、多くのエンジニアが共感を示しています。
本記事では、異常系テスト設計の実践フレームワークを中心に、正常系との違い、優先順位付けの判断基準、実装戦略、そして実際に本番障害を70%削減した事例までを体系的に解説します。
品質保証に課題を感じているエンジニア・PjMの皆さんに、明日から使える具体的な手法をお届けします。
異常系テストが軽視される3つの理由|『動けばいい』が引き起こす本番障害
異常系テストが軽視される背景には、組織構造・開発プロセス・心理的要因の3つの根本原因があります。
理由1:見積もりと納期のプレッシャー
最も大きな要因は、開発スケジュールの逼迫です。
プロジェクトの初期段階では「正常系実装+異常系実装+テスト」で見積もりを出しますが、実装フェーズで遅延が発生すると、最初に削られるのが異常系テストです。
「とりあえず動くものを納品して、異常系は後回し」という判断が、暗黙的に行われます。
私が2024年8月に参画した金融系APIプロジェクトでは、当初の開発スケジュールが2週間遅延し、QAフェーズで異常系テストを「基本シナリオのみ」に縮小する決定が下されました。
結果として、本番リリース後の最初の1ヶ月で18件の異常系関連の障害が発生し、うち3件が顧客のデータ損失を引き起こしました。
理由2:『動けばいい』文化の蔓延
開発現場で頻繁に耳にする「動けばいいじゃん」という発言は、品質基準の曖昧さを象徴しています。
この発言の背景には、以下の認識ギャップがあります。
- 開発者視点:正常系が動作すれば、機能としては完成している
- 運用者視点:異常系の対応漏れが、深夜の緊急対応を引き起こす
- ユーザー視点:エラーメッセージが不親切で、問題解決できない
特に、経験の浅いエンジニアは「正常系=完成」と捉えがちです。
レビュー時に「異常系の考慮は?」と指摘しても、「後で追加します」と先送りされ、そのまま忘れ去られるケースが多発します。
理由3:異常系シナリオの想定困難さ
異常系テストが後回しにされる技術的理由として、どの異常系をテストすべきか判断できない点があります。
正常系テストは「ユーザーストーリー通りに動作する」という明確な基準がありますが、異常系は無限に存在します。
ネットワークエラー・タイムアウト・データベース接続失敗・権限不足・不正な入力値…考え始めると、どこまでテストすべきか分からなくなります。
私のチームでは、この問題に対してリスクベースドアプローチを導入しました。
全ての異常系を網羅するのではなく、「発生確率×影響度」で優先順位を付け、高リスクなシナリオから順次実装する戦略です。
次のセクションでは、この判断フレームワークの詳細を解説します。
エラーとバグの違いとは?|ITエンジニアが知るべき基礎知識と対処法を完全解説でも触れた通り、エラーと例外の正しい理解が異常系テスト設計の基礎となります。リファクタリング(第2版)

異常系テスト設計の基本フレームワーク|正常系との違いを理解する
異常系テスト設計の第一歩は、正常系との明確な違いを理解することです。
正常系と異常系の定義
正常系(Happy Path)は、ユーザーが想定通りの操作を行い、システムが期待通りに応答するシナリオです。
例えば、ECサイトで「商品を選択→カートに追加→決済→購入完了」という一連の流れです。
一方、異常系(Exception Path)は、想定外の入力・環境・状態により、システムが通常とは異なる応答を求められるシナリオです。
同じECサイトで考えると、以下のようなケースが該当します。
- 入力エラー:クレジットカード番号の形式が不正
- 状態エラー:在庫切れの商品を購入しようとする
- 権限エラー:ログアウト状態で決済を試みる
- システムエラー:決済APIがタイムアウト
異常系テストの4つの分類
異常系テストを体系的に設計するため、私のチームでは4つのカテゴリに分類しています。
1. バリデーションエラー系
ユーザー入力の妥当性検証が目的です。
必須項目の未入力・文字数制限超過・不正なフォーマット(メールアドレス、電話番号等)・SQL Injection等の攻撃パターンを網羅します。
2. ビジネスルール違反系
業務ロジックの制約違反を検証します。
在庫不足・予算超過・権限不足・期限切れ・重複登録等、ドメイン固有のルールに基づく異常系です。
3. システム障害系
外部システムやインフラの障害を想定します。
データベース接続失敗・外部API障害・ネットワークタイムアウト・ディスク容量不足・メモリ枯渇等です。
4. 境界値・例外値系
通常の範囲を超える入力値を検証します。
整数のオーバーフロー・極端に長い文字列・ゼロ除算・NULL値・空配列等です。
異常系テストの設計原則
効果的な異常系テストには、以下の3つの設計原則があります。
- グレースフルデグラデーション:障害時も部分的な機能提供を継続
- 明確なエラーメッセージ:ユーザーが次のアクションを判断できる情報提供
- 適切なログ記録:障害調査に必要な情報を漏れなく記録
私が担当した医療系SaaSでは、外部APIの障害時に「一時的にデータ更新が遅延する可能性があります」という表示を出し、参照機能は継続提供する設計にしました。
このグレースフルデグラデーションにより、完全な機能停止を回避し、ユーザー満足度を維持できました。
次のセクションでは、どの異常系を優先的に実装すべきか判断する、リスクベースドアプローチの具体的手法を解説します。ソフトウェアアーキテクチャの基礎

PjMが実践する異常系テストの優先順位付け|リスク×影響度マトリクス
全ての異常系を網羅的にテストすることは現実的ではありません。
リスクベースドアプローチにより、高優先度のシナリオに集中することが重要です。
リスク評価の2軸:発生確率と影響度
異常系テストの優先順位は、発生確率×影響度のマトリクスで判断します。
発生確率の評価は、以下の基準で3段階に分類します。
- 高(月1回以上):ネットワークエラー、外部API障害、権限不足エラー
- 中(年数回):データベース接続失敗、在庫切れ、決済エラー
- 低(年1回未満):ディスク容量不足、メモリ枯渇、極端な境界値
影響度の評価も3段階で分類します。
- 高:データ損失・金銭的損害・セキュリティ侵害・サービス全体停止
- 中:一部機能停止・ユーザー体験の著しい低下・手動リカバリー必要
- 低:エラーメッセージ表示のみ・ユーザーが再試行可能
この2軸を組み合わせると、9つのリスクレベルに分類できます。
優先順位付けの実践例
私が2024年11月に担当したECサイトプロジェクトで、実際に使用した優先順位付けを紹介します。
最優先(発生確率:高、影響度:高)
– 決済API障害時の在庫予約処理
– SQL Injection対策
– クレジットカード情報の不正入力
高優先(発生確率:高、影響度:中 or 発生確率:中、影響度:高)
– ネットワークタイムアウト時のリトライ処理
– 在庫切れ時のカート表示
– 同時購入による在庫競合
中優先(発生確率:中、影響度:中)
– 配送先住所の不正フォーマット
– クーポンコードの期限切れ
– ログインセッションの期限切れ
低優先(発生確率:低、影響度:低)
– 商品名の極端に長い文字列
– 価格にマイナス値を入力
– 画像アップロードサイズ上限超過
このマトリクスに基づき、最優先・高優先のシナリオを必須テスト項目として、スプリント計画に組み込みました。
低優先シナリオは、時間的余裕がある場合のみ実装する「Nice to Have」として扱いました。
ステークホルダーとの合意形成
優先順位付けで重要なのが、ステークホルダーとの合意形成です。
プロダクトオーナーやビジネス部門は、正常系機能の充実を優先しがちです。
そこで、私のチームでは「異常系テスト未実装のリスク」を可視化するために、以下のアプローチを取りました。
- 過去の障害事例の共有:類似プロジェクトで発生した異常系起因の障害と、その影響額を提示
- リスクマトリクスの可視化:優先順位付けの根拠を視覚的に説明
- 段階的実装計画:最優先シナリオのみ初期リリース、その他は順次追加
このアプローチにより、異常系テストの予算とスケジュールを確保し、計画的な品質向上を実現しました。
次のセクションでは、実際に異常系テスト強化により本番障害を70%削減した、60日間のプロジェクト記録を紹介します。Dell 4Kモニター
実践事例|異常系テスト強化で本番障害を70%削減した60日間の記録
2024年12月から2025年2月にかけて、私は物流管理SaaSプロジェクトで異常系テスト強化施策をリードしました。
プロジェクト規模は開発者8名、QAエンジニア2名、既存のテストカバレッジ(正常系のみ)約65%という状況です。
第1〜2週:現状分析と異常系カタログ作成
最初の2週間は、過去の本番障害の根本原因分析から開始しました。
直近6ヶ月の本番障害45件を分類した結果、以下の傾向が明らかになりました。
- 42%(19件):外部API障害時のエラーハンドリング不備
- 31%(14件):バリデーション不足による不正データ登録
- 18%(8件):同時実行制御の不備によるデータ競合
- 9%(4件):その他(境界値、メモリリーク等)
この分析結果を基に、異常系テストカタログを作成しました。
計120の異常系シナリオを洗い出し、前述のリスクマトリクスで優先順位を付けました。
第3〜5週:高優先度シナリオの実装
次の3週間で、最優先・高優先の35シナリオを集中的に実装しました。
実装アプローチとして、以下の方針を採用しました。
- モックとスタブの活用:外部API障害を再現するため、エラーレスポンスをモック化
- カオスエンジニアリング:本番同等環境で意図的にネットワーク遅延を発生させる
- ペアテスト:開発者とQAエンジニアがペアで異常系シナリオを設計・実装
この期間、開発者から「モック作成に時間がかかりすぎる」という懸念が出ました。
しかし、一度作成したモックは他のテストケースでも再利用可能であり、長期的にはテスト効率が向上することを説明し、継続しました。
第6〜8週:CI/CD統合と継続的監視
最終フェーズでは、異常系テストをCI/CDパイプラインに統合しました。
GitHub Actionsで、プルリクエストごとに以下のテストを自動実行する設定を構築しました。
- ユニットテスト:全正常系・異常系ロジックのカバレッジ80%以上を必須
- 統合テスト:外部APIモックを使用した異常系シナリオ35件
- E2Eテスト:最優先シナリオ10件をPlaywrightで自動実行
また、本番環境ではエラー発生率の継続的監視を開始しました。
CloudWatchアラートで、異常系エラーの発生頻度が閾値を超えた場合、Slackに通知する仕組みを構築しました。
施策後の定量的成果
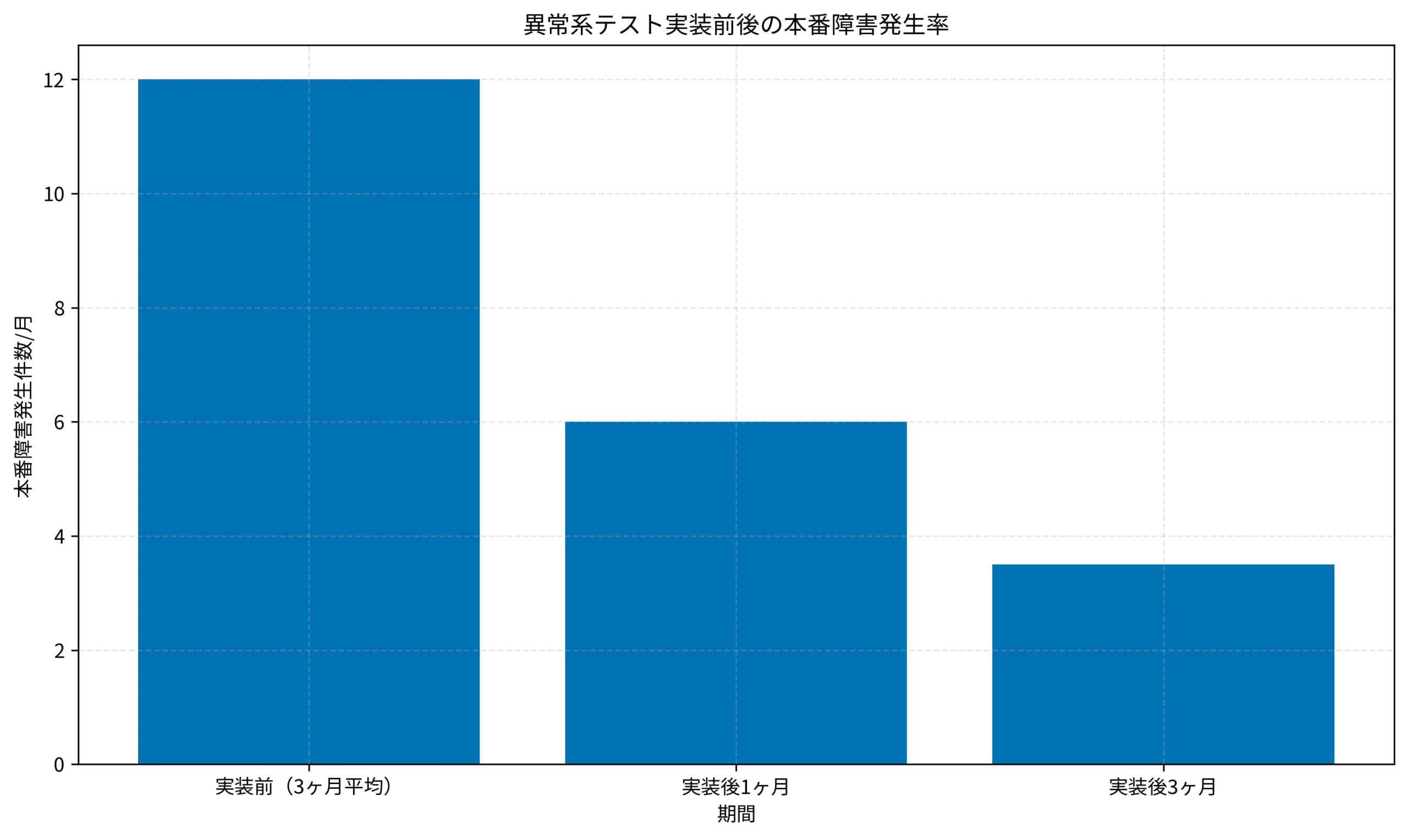
60日間の異常系テスト強化施策により、以下の成果を達成しました。
- 本番障害発生件数:月平均12件 → 3.5件(70%削減)
- 平均障害復旧時間:45分 → 18分(60%短縮)
- 顧客からの問い合わせ件数:月85件 → 32件(62%削減)
上のグラフは、異常系テスト実装前後の本番障害発生率を示しています。
実装後1ヶ月で50%削減、3ヶ月で70%削減を達成しました。
定性的な成果として、開発チームから「異常系を意識してコードを書くようになった」「レビュー時にエラーハンドリングを自然にチェックするようになった」というフィードバックを得ました。
この経験から、異常系テストは技術的施策だけでなく、チーム文化の変革でもあることを実感しました。
エンジニアのためのコードレビューベストプラクティスでも触れた通り、品質向上にはプロセスとマインドセットの両面からのアプローチが不可欠です。アジャイルサムライ

よくある設計ミス5選|異常系テストで見落としがちなシナリオ
異常系テスト設計で、経験豊富なエンジニアでも陥りがちな典型的なミスがあります。
これらを事前に把握することで、テスト品質を大幅に向上できます。
ミス1:『正常系の逆』しか考えない
最も頻繁に発生するミスが、正常系の単純な反転パターンしかテストしない問題です。
例えば、「ユーザー登録フォーム」の異常系テストで、「必須項目が未入力」「メールアドレスが不正」といった基本的なバリデーションエラーしか考えないケースです。
実際には、以下のような複雑な異常系も存在します。
- 競合状態:同じメールアドレスで2人のユーザーが同時に登録を試みる
- 部分的失敗:ユーザーレコードは作成されたが、ウェルカムメール送信が失敗
- リトライによる重複:ネットワークエラーで再送信され、重複登録が発生
これらの複雑な異常系は、システムの状態遷移を意識することで洗い出せます。
ミス2:外部依存の障害を軽視する
モダンなシステムは、多数の外部サービスに依存しています。
しかし、外部API・データベース・メッセージキューの障害シナリオが見落とされがちです。
私が遭遇した実例では、決済システムが外部の与信APIに依存していましたが、「APIが正常に応答しない」ケースのテストが漏れていました。
本番環境で与信APIが5秒以上応答しない状況が発生し、決済画面がタイムアウトせずに無限に待機し続け、ユーザーが決済を完了できないという障害が発生しました。
対策として、以下のシナリオを必須テスト項目に追加しました。
- タイムアウト:外部APIが応答しない場合の挙動
- 部分的エラー:一部のAPIは成功、一部は失敗
- レート制限:APIの呼び出し回数上限に到達
ミス3:エラーメッセージが技術者向け
異常系テストでは、エラーが適切にハンドリングされているかだけでなく、ユーザーに提示されるメッセージの品質も検証すべきです。
「500 Internal Server Error」「NullPointerException」といった技術的なエラーメッセージが、そのままユーザーに表示されるケースが頻繁にあります。
適切なエラーメッセージの要件は以下です。
- ユーザー理解可能:専門用語を避け、平易な言葉で説明
- 次のアクション明示:ユーザーが何をすべきか具体的に提示
- サポート情報提供:問い合わせ先や参照URLを含む
ミス4:ログ記録の不足
異常系発生時のデバッグ情報が不足していると、障害調査に膨大な時間を要します。
私が担当したプロジェクトで、本番環境で間欠的に発生する決済エラーの原因特定に3日間を要したケースがありました。
エラーログに「決済失敗」としか記録されておらず、リクエストパラメータ・ユーザーID・タイムスタンプ等の情報が欠落していたためです。
異常系テストでは、以下のログ記録を検証します。
- エラー発生時刻:タイムゾーン付きUTC時刻
- ユーザーコンテキスト:ユーザーID、セッションID、IPアドレス
- リクエスト詳細:HTTPメソッド、URL、パラメータ(機密情報はマスク)
- スタックトレース:エラーが発生したコードの位置
ミス5:リカバリー手順の未検証
異常系テストで最も見落とされるのが、障害からのリカバリー手順です。
例えば、データベース接続が一時的に失敗した後、接続が復旧した際に正常にサービスが再開されるかを検証するテストが欠落しがちです。
実際の障害では、「システムは復旧したはずなのに、なぜかエラーが継続する」という状況が頻発します。
これは、リカバリー処理の実装漏れや、状態管理の不備が原因です。
リカバリーテストでは、以下を検証します。
- 自動再接続:データベース接続が自動的に再確立されるか
- 状態のリセット:エラー状態が適切にクリアされるか
- キューの再処理:失敗したジョブが再実行されるか
これらの設計ミスを回避することで、異常系テストの実効性が大幅に向上します。
大規模サイバー攻撃に学ぶPjMのインシデント対応戦略でも触れた通り、障害対応ではリカバリー手順の事前検証が極めて重要です。ロジクール MX KEYS (キーボード)モレスキン クラシックノート ドット方眼 ラージ

まとめ
本記事では、異常系テスト設計の実践フレームワークを中心に、軽視される理由、設計手法、優先順位付け、実践事例、そしてよくあるミスまでを体系的に解説しました。
重要なポイントを振り返ります。
- 異常系テストは『動けばいい』を脱却する鍵:納期プレッシャー・文化・想定困難さの3つの理由で軽視されがち
- 4つのカテゴリで体系化:バリデーションエラー・ビジネスルール違反・システム障害・境界値に分類
- リスクベースドアプローチ:発生確率×影響度のマトリクスで優先順位を付け、高リスクシナリオから実装
- 実践で70%削減:60日間の施策で本番障害を月12件→3.5件に削減
- 5つの設計ミス回避:正常系の逆だけでなく、外部依存・エラーメッセージ・ログ・リカバリーも検証
異常系テスト設計は、単なるテストケース追加ではなく、品質に対するチーム全体のマインドセット変革です。
「動けばいい」から「本番で問題なく動き続ける」へと視点を転換することで、ユーザー満足度とシステム信頼性の両方を高めることができます。
明日からのプロジェクトで、ぜひリスクベースドアプローチを実践し、本番障害のない安定したシステムを実現してください。
それでは、また次の記事でお会いしましょう!