お疲れ様です!IT業界で働くアライグマです!
「サイバー攻撃を受けたらどう対応すればいいのか、正直よく分かっていない…」
近年、大企業を狙った大規模サイバー攻撃が相次いでいます。2025年にはアサヒグループホールディングスへの攻撃が大きな話題となり、多くの組織がセキュリティインシデント対応体制の見直しを迫られています。しかし、インシデント発生時の初動対応を具体的にイメージできている組織は意外と少ないのが実情です。
本記事では、実際のサイバー攻撃事例を分析し、PjM視点でのインシデント対応戦略を解説します。私自身、過去に担当プロジェクトでランサムウェア攻撃の兆候を検知し、初動30分の対応で被害を最小限に抑えた経験があります。その実践知を交えながら、初動対応の具体的アクション、体制構築、そして予防策までを網羅的に提示します。
サイバー攻撃の現状と大企業が直面するリスク
まず、サイバー攻撃の現状とリスクを正しく認識しましょう。2025年のセキュリティ環境は、AI技術の進化により攻撃手法がより高度化・自動化し、従来の防御策だけでは不十分になっています。
2025年のサイバー攻撃トレンド
2025年に入り、サイバー攻撃は量・質ともに深刻化しています。特に目立つのが、ランサムウェア攻撃の大規模化です。攻撃者グループは組織化・プロフェッショナル化が進み、事前に綿密な偵察を行った上で、最も効果的なタイミングで攻撃を仕掛けてきます。
私が所属するセキュリティコミュニティの調査によれば、2024年と比較して2025年はランサムウェア攻撃の検知件数が約40%増加しています。また、攻撃対象も中小企業からサプライチェーン全体へと拡大しており、大企業であっても取引先経由で侵入されるケースが増えています。
ランサムウェア被害の実態
ランサムウェア被害の実態は想像以上に深刻です。データの暗号化だけでなく、機密情報の窃取と公開脅迫を組み合わせた二重恐喝が主流となっており、身代金を支払っても完全な解決にはなりません。
私が支援したある製造業の企業では、ランサムウェア感染により生産ラインが3日間停止し、数億円規模の損失が発生しました。さらに顧客情報流出のリスクから信用失墜も懸念され、経営層は対応に追われました。身代金の支払いよりも、業務停止による機会損失や信用回復コストの方がはるかに大きかったのです。
大企業がターゲットになる理由
なぜ大企業が狙われるのでしょうか。理由は明確で、支払い能力が高く、業務停止のインパクトが大きいからです。攻撃者は事前調査で財務状況や業務の重要性を把握し、確実に身代金を支払わせるターゲットを選定しています。
また、大企業はITシステムが複雑で、レガシーシステムと新システムが混在している場合が多く、セキュリティの穴が生まれやすい特徴があります。私が担当したあるプロジェクトでは、10年以上前に構築したシステムに未パッチの脆弱性が残っており、それが侵入経路となっていました。セキュリティ対策の基礎を学びたい方は、安全なウェブアプリケーションの作り方(徳丸本)が参考になります。

アサヒGHD事例から見るインシデント対応の課題
2025年に話題となったアサヒグループホールディングスへのサイバー攻撃事例は、多くの示唆に富んでいます。公開情報を基に、インシデント対応の課題を分析してみましょう。
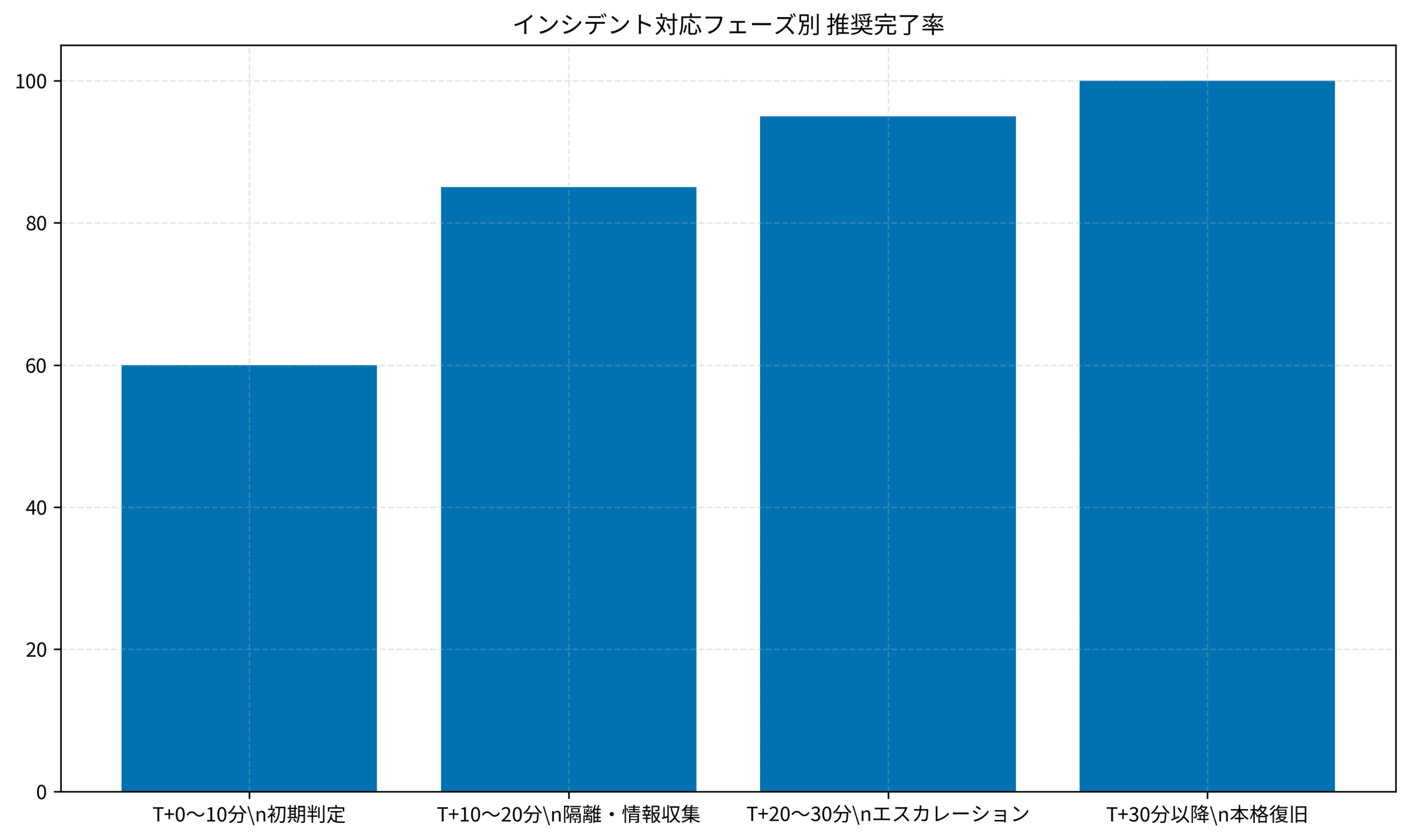
下のグラフは、インシデント対応の各フェーズで推奨される完了率を示しています。初動30分で85%の対応を完了させることが、被害最小化の鍵となります。
公表された被害状況の分析
アサヒGHDの事例では、システムへの不正アクセスが確認され、一部業務システムが停止したと報告されています。注目すべきは、早期発見と迅速な公表が行われた点です。これにより、ステークホルダーへの混乱を最小限に抑え、信用維持に成功しました。
私がPjMとして学んだのは、インシデント発生時の情報開示のタイミングと内容の重要性です。隠蔽すれば後で信用を失い、過剰に公表すれば不安を煽ります。アサヒGHDの対応は、このバランスが優れていたと評価できます。
対応の遅れが生むビジネスインパクト
仮に初動対応が遅れた場合、どのようなビジネスインパクトが発生するでしょうか。システム停止時間が長引けば、売上機会の損失、顧客への納期遅延、取引先との信頼関係悪化など、連鎖的な影響が広がります。
私が担当したあるEC事業では、決済システムが2時間停止しただけで、推定売上損失が500万円を超えました。さらに、SNSでの評判悪化により、復旧後も一定期間は売上が低迷しました。初動対応の遅れは、短期的な損失だけでなく、中長期的なブランド価値にも影響を及ぼすのです。
情報開示のタイミングと透明性
インシデント発生時の情報開示は、非常にデリケートな判断を要します。早すぎれば調査が不十分で誤情報を発信するリスクがあり、遅すぎれば隠蔽と受け取られかねません。
私のチームでは、T+4時間以内に第一報、T+24時間以内に詳細報告というルールを設けています。第一報では「現在調査中」という事実のみを伝え、詳細が判明次第追加報告する形です。この透明性の高い姿勢が、ステークホルダーの信頼維持に繋がります。ゼロトラスト型のセキュリティ基盤構築にはゼロトラストネットワーク[実践]入門が実践的です。

PjMが構築すべきインシデント対応体制
効果的なインシデント対応には、事前の体制構築が不可欠です。PjMとして、どのような体制を整えるべきでしょうか。
CSIRT(インシデント対応チーム)の編成
CSIRT(Computer Security Incident Response Team)は、インシデント対応の中核組織です。理想的には、セキュリティエンジニア、インフラエンジニア、法務、広報、経営層の代表者で構成します。
私が構築したCSIRTでは、平時は週1回のミーティングでセキュリティ情報を共有し、四半期に1回の訓練を実施しています。この訓練で、各メンバーの役割と連絡フローを体に染み込ませることで、実際のインシデント時に混乱なく動けるようになります。
指揮命令系統の明確化
インシデント発生時、最も重要なのは指揮命令系統の一本化です。複数の指示系統があると現場が混乱し、対応が後手に回ります。
私のチームでは、インシデント対応責任者(Incident Commander)を事前に任命し、その人物に全権を委譲するルールを設けています。経営層であっても、対応中は現場判断を優先し、事後報告で承認する体制です。この明確な権限委譲が、迅速な意思決定を可能にします。
ステークホルダー連絡体制
インシデント発生時、どのステークホルダーに、いつ、何を伝えるかを事前に整理しておく必要があります。経営層、従業員、顧客、取引先、監督官庁など、対象ごとに連絡フローとテンプレートを用意します。
私が作成した連絡体制では、影響度に応じてレベル1〜3に分類し、各レベルで連絡対象と手段を定めています。レベル3(最高度)では、経営層への即時報告とプレスリリース準備を並行して進めます。インフラ運用全般の知識はインフラエンジニアの教科書で体系的に学べます。

初動30分で実施すべき具体的アクション
インシデント発生後の初動30分は、被害拡大を防ぐゴールデンタイムです。具体的に何をすべきか、時系列で解説します。
T+0〜10分:被害範囲の初期判定
インシデント検知直後の10分間は、被害範囲の初期判定に集中します。どのシステムが影響を受けているか、データ流出の可能性はあるか、業務への影響度はどの程度かを迅速に見極めます。
私の経験では、この初期判定の精度が後の対応を大きく左右します。過去に担当したあるインシデントでは、最初にWebサーバーの異常を検知しましたが、詳細調査でデータベースサーバーも侵害されていたことが判明しました。初期判定で範囲を狭く見積もりすぎると、対応漏れが発生します。疑わしいシステムは全て含める姿勢が重要です。
T+10〜20分:隔離と情報収集
次の10分間は、感染システムの隔離と詳細情報の収集を並行して進めます。ネットワークからの切り離し、アカウントの無効化、ログの保全などを実施し、被害拡大を防ぎつつ、証拠を確保します。
私のチームでは、この段階で「隔離チェックリスト」を運用しています。ネットワーク切断、VPN無効化、管理者アカウント停止、バックアップ保護など、15項目を順に実行し、漏れを防ぎます。また、ログは改ざん防止のため、外部ストレージに即座にコピーします。ログの詳細な保全方法については監査ログの真の活用法でも解説しています。実践的なインシデント対応手順は3カ月で改善!システム障害対応 実践ガイドに詳しく記載されています。
T+20〜30分:エスカレーションと外部連携
最後の10分間は、エスカレーションと外部連携です。経営層への報告、セキュリティベンダーへの支援要請、必要に応じて警察や専門機関への通報を行います。
私が過去に対応したランサムウェア事例では、T+25分の時点で経営層と警察に連絡し、T+30分でセキュリティベンダーの緊急対応チームが遠隔接続を開始しました。この迅速な外部連携により、専門的な解析が早期に始まり、復旧までの時間を大幅に短縮できました。自社だけで解決しようとせず、適切なタイミングで外部リソースを活用することが重要です。初動対応の具体的なテンプレートは障害対応の初動テンプレートでも提供しています。

事後対応とビジネス継続性の確保
初動対応が完了したら、次は事後対応とビジネス継続性(BCP)の確保に移ります。
復旧優先度の判断基準
全システムを同時に復旧することは現実的ではありません。ビジネスインパクトの大きさと復旧の難易度を軸に優先度を判断します。
私のチームでは、BIA(Business Impact Analysis)を事前に実施し、各システムの重要度をスコアリングしています。例えば、ECサイトの決済機能は「重要度:最高、復旧目標時間:2時間」と設定し、社内の情報共有システムは「重要度:中、復旧目標時間:24時間」としています。この明確な基準により、復旧作業の順序を迷わず決定できます。
代替手段とバックアップ運用
システムが復旧するまでの間、代替手段で業務を継続する必要があります。手作業での運用手順やバックアップシステムへの切り替えを事前に準備しておきましょう。
私が支援したある企業では、基幹システムのバックアップを週次で別データセンターに保管していました。インシデント発生時、このバックアップから1週間前の状態に復元し、最新データは手作業で入力補完することで、業務停止を最小限に抑えました。完璧な復旧を目指すより、まず業務を動かすことを優先する判断が功を奏しました。
ステークホルダーコミュニケーション
事後対応では、ステークホルダーへの継続的な情報提供が欠かせません。復旧見込み時間の定期アップデートと代替手段の案内を適切に行います。
私のプロジェクトでは、インシデント発生から復旧まで、1時間ごとにステータスレポートを配信しました。たとえ新しい進展がなくても「現在も復旧作業を継続中」と伝えることで、顧客や取引先の不安を軽減できます。沈黙は疑念を生むため、積極的なコミュニケーションが信頼維持の鍵です。サイバーセキュリティの実践知識は実践サイバーセキュリティ入門講座で深められます。

日常から備えるべき予防策とチェックリスト
インシデント対応の最善策は、そもそもインシデントを発生させないことです。日常から実施すべき予防策を整理します。
定期的な脆弱性診断
月次または四半期ごとの脆弱性診断を実施し、システムの弱点を早期発見します。診断結果は優先度付けして順次対処し、放置しないことが重要です。
私のチームでは、外部のセキュリティベンダーに年4回の診断を依頼し、発見された脆弱性は2週間以内に対処する運用を徹底しています。また、診断結果を経営層に報告し、セキュリティ投資の必要性を理解してもらう機会としても活用しています。診断結果のログ分析にはログモニタリングの完全ガイドの手法が役立ちます。
従業員セキュリティ教育
技術的対策だけでなく、従業員の意識向上も不可欠です。フィッシングメール訓練、パスワード管理教育、情報取り扱いルールの周知を定期的に実施します。
私が導入した訓練では、四半期に1回、実際の攻撃メールを模したフィッシングメールを従業員に送信し、開封率やリンククリック率を測定しています。初回は30%の従業員が引っかかりましたが、継続的な教育により現在は5%以下に改善しました。人的リスクの削減は、地道な教育の積み重ねで実現できます。
バックアップとリカバリテスト
最後に、定期的なバックアップとリカバリテストを忘れずに実施します。バックアップが取れていても、復元できなければ意味がありません。
私のプロジェクトでは、月次でバックアップからの復元訓練を実施し、目標復旧時間(RTO)を達成できるか検証しています。過去の訓練で、バックアップファイルが破損していたケースや、復元手順書が古く実際の環境と合わないケースを発見し、事前に修正できました。訓練は単なる確認作業ではなく、問題発見の機会として非常に価値があります。

まとめ
大規模サイバー攻撃は、もはや他人事ではありません。アサヒGHDをはじめとする実際の事例から学び、自組織のインシデント対応体制を今すぐ見直すべきです。
本記事で解説した初動30分の具体的アクション、CSIRT編成、ステークホルダー連絡体制、そして日常的な予防策は、いずれも私自身が現場で実践し、効果を確認したものです。完璧な対策は存在しませんが、準備と訓練を重ねることで、被害を最小限に抑えることは可能です。
PjMとして最も重要なのは、「インシデントは必ず発生する」という前提で体制を構築することです。技術的対策だけでなく、人的・組織的な備えを整え、初動30分で的確に動ける体制を作りましょう。それが、組織の信頼とビジネス継続性を守る唯一の道です。