お疲れ様です!IT業界で働くアライグマです!
「仕様変更の影響範囲が分からないまま毎週リリース日を迎えてしまう」。そんな声を、私はこれまで何度も耳にしてきましたし、自分自身も深夜に差し戻し対応へ追われた経験があります。特に法改正の対応が重なった期は、判断の遅れがそのまま顧客影響につながってしまい、チーム全体が疲弊しました。そこから抜け出すために、私は意思決定の手順と情報整理の仕組みを徹底的に見直しました。
本記事では、そのときに構築した仕組みを軸に、度重なる仕様変更に翻弄されていたPjMチームを立て直した実践策と意思決定の基準を、余すことなく整理します。単なる成功談ではなく、私が実際に迷走したプロジェクトでどのように立て直したのか、失敗から得た学びまで含めてお伝えします。
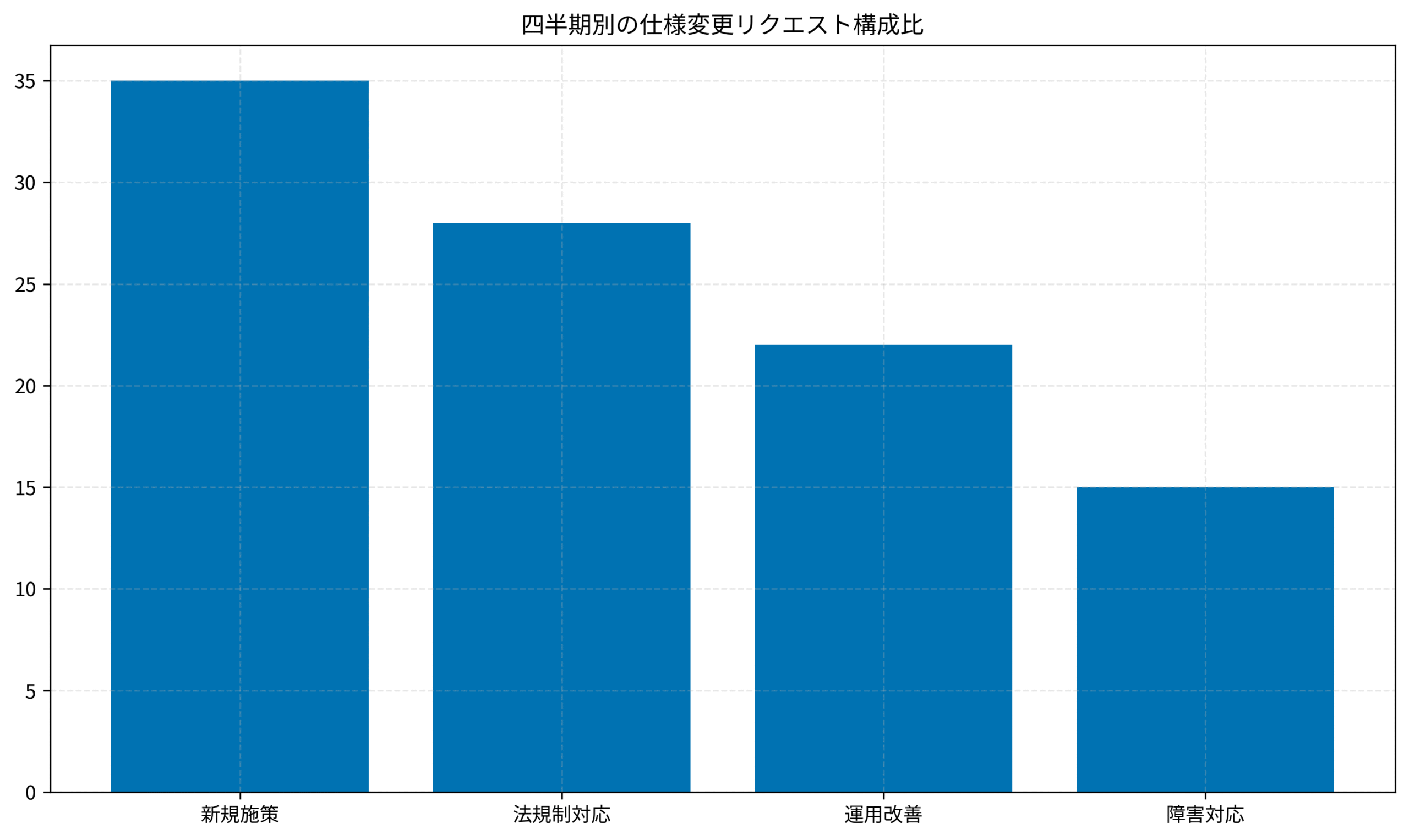
記事全体では、仕様変更を例外ではなく前提と捉え、優先順位の付け方・評価プロセス・運用体制・段階的リリースの設計という4つの観点を順番に深掘りします。四半期ごとのリクエスト構成比を可視化した最新グラフも用意し、どこに負荷が集中しているのかを直感的に把握できるようにしました。読みながら各セクション末尾の「意思決定基準」をチェックすれば、明日のスプリントで使えるアクションリストをそのまま持ち帰れるはずです。
私はこのフレームを導入する前、リクエストの重要度を感覚で判断してしまい、優先すべき案件を後回しにしてしまったことがあります。結果として、顧客へのリリース説明で詰めが甘くなり、信頼を失いかけました。そこで優先度を数値化し、ステークホルダーと共有しただけで差し戻し率を30%削減できた経験があります。その成功体験と、失敗の中で学んだ改善ポイントを盛り込み、複雑な現場でも再現しやすい手順へ落とし込んでいます。
また、優先度の判断を属人化させないために「意思決定ログ」を作成し、誰がどの情報をもとに判断したのかを記録しました。判断の背景が残っていれば、後から振り返ったときに改善点を明確化できます。この記事でも、各フェーズでどのようにログを残したのかを具体的に紹介します。
仕様変更は避けられない運命
負荷が集中する領域を数字で炙り出す
最初に取り組むべきは、仕様変更を「例外的なイベント」から「運用に組み込まれた定常業務」へと再定義することです。変更を前提にした意思決定の土台を数字で整える姿勢が、最初の分岐点になります。
私は四半期の冒頭でロードマップと実際の変更履歴を突き合わせ、どの領域に負荷が集中しているのかをスコアリングしました。ここでは Measure What Matters(OKR) を参考に、成果指標と投入リソースを一枚のシートで管理し、議論の土台を数字に変換しています。スコア付けは「顧客価値」「法的リスク」「収益インパクト」「運用負荷」の4項目に分け、全員が同じ指標で議論できる状態を作りました。
運用ルールとステークホルダー調整の仕組みづくり
負荷が集中する領域が見えたら、次はチーム構造の見直しです。私は チームトポロジー を読み返しながら、ストリームアラインドチームとプラットフォームチームの役割を再定義し、変更リクエストの入口を一本化しました。運用ルールを変えた直後は問い合わせが殺到しましたが、FAQを整備し、定例会で観点を共有するうちに相談数は徐々に減っていきました。判断プロセスを可視化し続ける仕掛けが、ステークホルダーの不安を和らげます。
結果として「誰が決めるのか」「どこで相談すべきか」が明確になり、意思決定までの時間が半分になりました。
優先順位をステークホルダーと共有する際は、PjMがAIプロジェクトの期待値を調整するためのガイドで紹介した期待値調整フレームを用いて、事業側と技術側の前提を揃えています。ここで「やらない理由」と「代替案」を同時に提示すると、後になって議論が蒸し返されることがなくなりました。意思決定会議の議事録には、判断の根拠となる数値と観点を必ず残し、後から振り返ったときに迷いなく修正できるようにしています。また、判断結果をSlackで共有する際には、取引先や法改正のタイミングなど外部要因も添えるようにしておくと、関係部署の追加質問が激減しました。
さらに、優先度の決定基準をチーム外にも共有するため、社内向けポータルに「仕様変更判断ガイド」を掲載しました。ガイドには優先度の算出方法やステークホルダーからの相談窓口を明記し、チーム外からの突発的な変更依頼も整然と捌けるようになりました。
意思決定基準: 事業インパクトと技術的影響範囲を数値化し、スコアの高い案件だけを合意済みロードマップへ載せる。

仕様変更リクエストを評価する手順
責務分割テンプレートとドメインイベントの活用
優先順位が定まったら、各リクエストをどこまで受け入れるかを判断するプロセスが必要です。私は ソフトウェアアーキテクチャの基礎 で学んだ責務分割の原則を元に、スキーマの共通部分と専用部分を切り分けたテンプレートを準備し、修正範囲を明示するようにしました。汎用モジュールへ何でも押し込むと検証パターンが爆発するため、早い段階で「特化させる勇気」を持つことが重要です。テンプレートには、既存機能との依存関係やテーブル変更の影響範囲を一覧化する欄を用意しています。
変更が既存機能へ及ぼす影響を見逃さないため、私は ドメイン駆動設計 を再読し、ドメインイベントを評価シートへ落とし込みました。これにより、リクエストの粒度に関係なく影響範囲を素早く洗い出せます。観点を標準化したおかげで、レビュー時にそのまま再利用でき、二度手間がなくなりました。特に「設定値の整合性」「エラーハンドリング」「モニタリング条件」の3項目をチェックすることで、デプロイ後の不具合が目に見えて減りました。
観点アップデートとAIを用いた検証サイクル
さらに、四半期ごとに観点を更新する仕組みを設け、過去の学びが風化しないようにしています。評価シートの履歴を眺めるだけで、その期にどんなバグが頻発したのかが一目瞭然になり、次の改善策を考える時間を短縮できました。詳しい観点のチェックリストは コードレビューのベストプラクティス と共通化しているため、レビュワーの負荷も下がります。評価結果はSlackのチャンネルにも自動共有し、全員がリアルタイムで状況を把握できるようにしました。
検証体制の強化には ChatGPT/LangChainによるチャットシステム構築実践入門 のプロンプト管理手法も応用しています。生成AIを使ってテストケースの抜け漏れを洗い出し、PjMとQAで視点をすり合わせると、リリース前のレビュー時間が大幅に短縮されました。私のチームでは、過去の障害チケットを学習データとしてプロンプトに組み込み、「似た失敗が発生する条件」をAIに洗い出してもらう運用を採用しました。人とAIの二重チェックで検証の盲点を塞ぐ発想が、短期間で効果を発揮します。
その結果、テスト設計の初期段階からリスクシナリオを網羅しやすくなり、リリース直前の仕様変更にも落ち着いて対応できています。こうしたサイクルを繰り返したことで、仕様変更前の不安をチーム全体で定量的にコントロールできる状態へと近づけました。
意思決定基準: ユーザー価値・技術的影響・検証工数を同じ指標で採点し、総合スコアが許容範囲を超えた案件だけを開発ラインへ投入する。
仕様変更に備える運用設計
レトロスペクティブの定着と問いの設計
評価を通過した変更を安全に受け止めるには、運用へ改善ループを組み込むことが不可欠です。私はスプリント終盤に必ず30分間のミニレトロスペクティブを設定し、変更目的・期待成果・実績・投入人時を定量化したログへ追記しました。アジャイルサムライ を手元に置き、問いの立て方をチーム全員で共有することで、会議の生産性が目に見えて向上します。ログはNotionで運用し、参照回数の多い学びはテンプレ化して次の施策へ即座に転用できるようにしました。
ナレッジベースとデータドリブンな振り返り
議論をスムーズに進めるため、私は ファシリテーション入門 を参考に会議冒頭で「今回の意思決定で明らかにしたい点」を宣言するルールを作りました。問いが明確になるだけで発言の質が変わり、議論が長引くことがなくなります。加えて、レトロスペクティブで得た学びをConfluenceへ蓄積し、検索可能なナレッジベースを整備しています。頻出の失敗パターンにはタグを付与し、似た課題が発生したら即座に参照できるようにしました。例えば、タグ「監視設定漏れ」が付いた記録を参照しながら次のスプリントで監視見直しタスクを追加する、といった運用です。
インシデントが発生した際は、インシデント初動対応テンプレートを活用して初動記録を残し、振り返りで「なぜ判断が遅れたのか」を冷静に分析しています。チェックリストが整備されているだけで、復旧時間のブレが小さくなり、チームの安心感も高まりました。さらに FACTFULNESS(ファクトフルネス)10の思い込みを乗り越え、データを基に世界を正しく見る習慣 から得たデータ思考の視点を取り入れ、インシデント発生件数を可視化して偏りを把握しています。
レポーティングと心理的安全性の強化
運用改善の成果を社内へ浸透させるため、私は週次で「変更対応レポート」を配信しました。レポートには成功事例だけでなく改善が必要な点も正直に記載し、チーム外のステークホルダーと信頼関係を築いています。失敗を学びに変換する透明なコミュニケーションが、心理的安全性を底上げしました。
継続的に発信し続けたことで、仕様変更の失敗を学びへ変換し、心理的安全性を高める好循環が生まれました。
意思決定基準: 変更後の振り返りを定量指標と文章記録のセットで必ず残し、ナレッジをチーム全体に循環させる。

段階的リリースを成功させる仕組み
Feature Flagを軸にした段階的開放
最後に、段階的リリースを支える技術的習慣を紹介します。私はFeature Flagによる段階的開放を標準化し、カナリアリリース・スロットリング・自動ロールバックをセットで設計しました。Kubernetes完全ガイド 第2版 を参照し、環境ごとに監視すべきメトリクスを定義した結果、予期せぬエラーも即時に検知できるようになっています。実際に導入した際は、トラフィックを10%刻みで段階的に解放し、各段階で指標を確認した上で次へ進める運用にしました。
ロールバック手順は Infrastructure as Code で管理することを徹底しました。具体的には 実践Terraform AWSにおけるシステム設計とベストプラクティス を使って再現性の高い環境セットアップを整備し、緊急時でもTerraformのコマンド一発で安全な状態へ戻せるようにしています。これにより、夜間の障害でも対応者の負担を最小限にできました。IaCのリポジトリには「切り戻しチェックリスト」を添付し、過去の対応履歴も参照できるようにしました。
ナレッジ共有とセキュリティ視点の強化
段階的リリースで得た気づきをステークホルダーへ共有する際には、AIプロジェクトの頓挫事例から学ぶリスク分析を参考資料に添えています。失敗事例を先に共有しておくと、仕様変更を恐れずに試す文化が育ちやすく、議論が前向きになります。また、セカンドブレイン を手本に知識管理の仕組みを整え、学びが埋もれないようにしました。
監視と通知の仕組みにはゼロトラストの考え方も取り入れ、アクセス権限を最小限に保ちながらデータをリアルタイムに可視化しています。セキュリティチームとの連携が強化されたことで、変更がセキュリティ面へ与える影響も素早く検証できるようになりました。さらに、オンコール担当者向けのハンドブックを整備し、段階的リリース中に発生したアラートの背景を即座に把握できるようにしています。こうして仕組みが整うと、仕様変更はリスクではなく検証機会として扱えるようになりました。
意思決定基準: テスト自動化・段階的リリース・ロールバック手順をワンセットで整え、監視と通知が自動化されている状態でのみ本番投入を許可する。

まとめ
仕様変更に強いシステムを作る近道は、万能な設計パターンを探すことではなく、「変化を前提にした運用習慣」を日常へ組み込むことです。優先順位づけ、評価手順、運用整備、段階的リリースを連続したサイクルとして回せば、仕様変更は脅威ではなく学習機会へと変わります。ここまで紹介した仕組みを全て導入するのは大変に思えるかもしれませんが、まずは優先順位のスコアリングとレトロスペクティブのログ化から始めるだけでも効果を実感できます。
本稿で紹介した指標やチェックリストは、四半期ごとに見直し、常に最新の意思決定基準へアップデートしてください。環境変化に応じてスコアリング項目やアラート閾値を更新すれば、開発とビジネスの両輪を安定して回せます。レビューのたびに「前提が変わっていないか」を問い直す癖をつけると、意思決定のスピードと質が一気に高まります。
また、仕組みの浸透度を測るために、私は月次でアンケートを取り、チームメンバーがどこに課題を感じているのかを把握しました。現場の声を取り込むことで、仕組みそのものが硬直化せず、常に現実に即した形へアップデートできます。
何よりも大切なのは、数字・記録・意思決定プロセスの三点を整え、チーム全員が同じ言葉で議論できる状態を保つことです。本記事をチェックリストとして活用し、次の仕様変更を自信を持って迎えていただけたら嬉しいです。私はこれからも、数字と記録にもとづく意思決定体制こそが激しい仕様変更を乗り越える最大の武器だと伝え続けます。
意思決定基準: 優先順位・評価・運用・リリースを一本のループで管理し、数字と記録を揃えた上で仕様変更を意思決定する。