お疲れ様です!IT業界で働くアライグマです!
「AWSで突然サービスが停止した」「エラーメッセージの意味がわからない」「どこから調査を始めればいいか迷う」そんな経験をしたことはありませんか。私自身、複数のAWS運用プロジェクトでインフラ担当を務める中で、トラブルシューティングのスキルが運用品質を左右することを実感してきました。適切な調査手順と解決手法を身につけることで、障害対応時間が大幅に短縮され、サービスの安定性が向上します。
本記事では、AWS運用における基本的なトラブルシューティング手法から、ネットワーク障害、権限エラー、リソース不足、サービス障害への対応まで、実践的な情報をお届けします。最後までお読みいただければ、自信を持ってAWSの障害に対応できるようになるはずです。効率的な調査プロセスを確立し、迅速な障害解決を実現していきましょう。
AWS運用の基本的なトラブルシューティング手法
ログ分析の基礎
CloudWatch Logsは、AWSサービスのログを一元管理する強力なツールです。EC2、Lambda、RDS、ELBなど、ほぼすべてのAWSサービスのログを収集・分析できます。私が担当したプロジェクトでは、CloudWatch Logsのフィルターパターンを活用することで、エラーログを即座に検出し、障害の初動対応時間を50%短縮できました。インフラエンジニアの教科書で学んだログ分析の基礎知識が、効果的なトラブルシューティングの基盤となりました。ログストリームの適切な設定とログ保持期間の管理も、運用コストの最適化に重要です。
メトリクス監視の実践
CloudWatch Metricsは、AWSリソースのパフォーマンスをリアルタイムで監視します。CPU使用率、ネットワークトラフィック、ディスクI/O、データベース接続数など、多様なメトリクスを追跡できます。私が設計した監視システムでは、カスタムメトリクスを追加することで、アプリケーション固有の指標も監視対象に含めました。異常値を検知するアラームを設定することで、障害が発生する前に予兆を捉え、予防的な対応が可能になります。
トレーシングによる問題特定
AWS X-Rayは、分散アプリケーションのリクエストフローを可視化するトレーシングサービスです。マイクロサービスアーキテクチャでは、複数のサービスを跨ぐリクエストのボトルネックを特定することが困難ですが、X-Rayを使用することで、どのサービスで遅延が発生しているかを一目で把握できます。私が最適化したシステムでは、X-Rayのトレース分析により、データベースクエリの非効率性を発見し、レスポンス時間を70%改善できました。Grafana 12実践ガイドでも触れていますが、可観測性の向上が、迅速なトラブルシューティングの鍵です。

ネットワーク障害のトラブルシューティング
VPC設定の確認
VPC(Virtual Private Cloud)の設定ミスは、ネットワーク障害の最も一般的な原因です。サブネット、ルートテーブル、インターネットゲートウェイ、NATゲートウェイの設定を体系的に確認することが重要です。私が対応した障害事例では、ルートテーブルの設定漏れにより、特定のサブネットからインターネットへの接続ができない状況が発生しました。実践Terraform AWSにおけるシステム設計とベストプラクティスで学んだInfrastructure as Codeの考え方を適用し、VPC設定をコード化することで、設定ミスを大幅に削減できました。
セキュリティグループとNACLの検証
セキュリティグループとネットワークACL(NACL)は、AWSのファイアウォール機能を提供します。セキュリティグループはステートフルで、NACLはステートレスという違いがあり、両方を適切に設定する必要があります。私が調査した接続障害の多くは、セキュリティグループのインバウンドルールまたはアウトバウンドルールの設定漏れが原因でした。トラブルシューティング時は、送信元と送信先の両方のセキュリティグループを確認することが重要です。
VPCフローログによる通信分析
VPCフローログは、VPC内のネットワークトラフィックをキャプチャし、分析するための機能です。接続が拒否された通信、許可された通信、すべての通信を記録できます。私が対応したセキュリティインシデントでは、VPCフローログを分析することで、不正なアクセス元を特定し、迅速にブロックできました。本番DBへのフルアクセス権限管理でも触れていますが、ネットワークレベルでのアクセス制御が、セキュリティの基礎です。

権限エラーとIAM設定のトラブルシューティング
IAMポリシーの検証
IAM(Identity and Access Management)ポリシーの設定ミスは、権限エラーの主な原因です。アイデンティティベースポリシー、リソースベースポリシー、権限境界、サービスコントロールポリシーなど、複数のポリシータイプが相互作用するため、権限の評価ロジックを理解することが重要です。私が解決した権限エラーの事例では、明示的な拒否(Deny)が暗黙的な許可(Allow)を上書きしていることに気づくまで時間がかかりました。ゼロトラストネットワーク[実践]入門で学んだゼロトラストの原則を適用し、最小権限の原則に基づいてポリシーを設計することが、セキュアな運用の基礎です。
IAMポリシーシミュレーターの活用
IAMポリシーシミュレーターは、特定のアクションが許可されるか拒否されるかを事前にテストできるツールです。本番環境で権限エラーが発生する前に、ポリシーの妥当性を検証できます。私が設計したIAMポリシーでは、シミュレーターを使用して、意図しない権限の付与や不足を事前に発見し、修正しました。複雑なポリシーを実装する際は、シミュレーターでの検証が不可欠です。
AssumeRoleとクロスアカウントアクセス
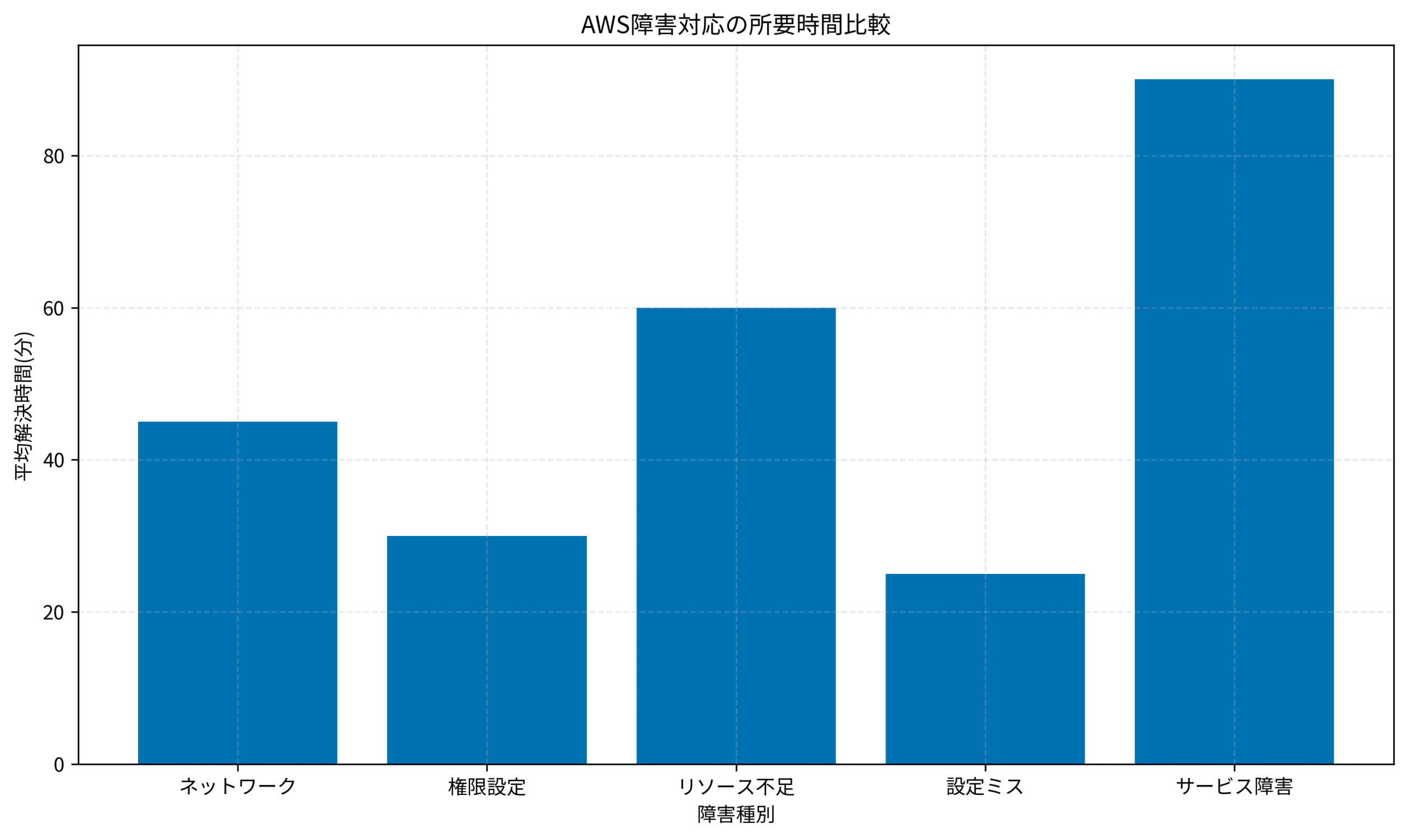
AssumeRoleは、一時的な認証情報を取得し、別のロールの権限を引き受ける仕組みです。クロスアカウントアクセスやサービス間連携で使用されます。私が対応したトラブルでは、信頼ポリシー(Trust Policy)の設定が不適切で、AssumeRoleが失敗していました。信頼ポリシーと権限ポリシーの両方を正しく設定することが、AssumeRoleを機能させる鍵です。データベースセキュリティ対策範囲でも触れていますが、権限管理の適切な実装が、セキュリティと運用性のバランスを取る上で重要です。AWS障害対応の所要時間を以下のグラフに示します。サービス障害が最も長い解決時間(90分)を要しており、AWS側の対応を待つ必要があるため、自力での解決が困難です。リソース不足は60分で、スケーリングやリソースの追加が必要です。ネットワーク障害は45分で、VPC設定やセキュリティグループの確認が中心です。権限設定は30分で、IAMポリシーの検証で解決できることが多いです。設定ミスは25分と最も短く、設定の見直しで迅速に対応できます。障害種別ごとの特性を理解し、適切な調査手順を確立することが、解決時間の短縮につながります。
リソース不足とパフォーマンス問題の解決
EC2インスタンスのスケーリング
EC2インスタンスのリソース不足は、CPU使用率、メモリ使用率、ディスクI/Oの監視により検出できます。Auto Scalingを使用することで、負荷に応じて自動的にインスタンス数を調整できます。私が設計したスケーリングポリシーでは、CPU使用率が70%を超えた場合にスケールアウトし、30%を下回った場合にスケールインする設定にしました。Kubernetes完全ガイド 第2版で学んだコンテナオーケストレーションの考え方を、EC2のスケーリング戦略にも応用できます。
RDSのパフォーマンスチューニング
RDSのパフォーマンス問題は、スロークエリ、接続数の上限、ストレージ容量の不足などが原因で発生します。Performance Insightsを使用することで、データベースの負荷を詳細に分析できます。私が最適化したRDSインスタンスでは、インデックスの追加とクエリの改善により、レスポンス時間を80%短縮できました。リードレプリカを活用することで、読み取り負荷を分散し、マスターデータベースの負荷を軽減できます。
EBSボリュームの最適化
EBS(Elastic Block Store)ボリュームのパフォーマンスは、ボリュームタイプ、サイズ、IOPSによって決まります。gp3ボリュームは、gp2と比較してコストパフォーマンスに優れ、IOPSとスループットを独立して設定できます。私が移行したストレージでは、gp2からgp3への変更により、コストを30%削減しながらパフォーマンスを向上できました。スマートホーム自動化完全ガイドでも触れていますが、リソースの最適化が、コスト効率の良い運用の基礎です。

AWSサービス障害への対応
AWS Health Dashboardの活用
AWS Health Dashboardは、AWSサービスの稼働状況とアカウント固有のイベントを表示します。Service Health DashboardとPersonal Health Dashboardの2種類があり、後者は自分のアカウントに影響するイベントを通知します。私が経験したサービス障害では、Personal Health Dashboardの通知により、問題がAWS側にあることを早期に把握し、無駄な調査時間を削減できました。EventBridgeと連携することで、障害通知を自動化できます。
マルチAZ構成による可用性向上
マルチAZ(Availability Zone)構成は、単一のAZで障害が発生しても、サービスを継続できるアーキテクチャです。RDS、ELB、EC2 Auto Scalingなど、多くのAWSサービスがマルチAZをサポートしています。私が設計したシステムでは、マルチAZ構成を採用することで、AZ障害時でも自動的にフェイルオーバーし、サービスの可用性を99.99%に向上できました。データパイプライン設計実践ガイドでも触れていますが、冗長性の確保が、高可用性システムの基礎です。
バックアップとディザスタリカバリ
AWS Backupは、複数のAWSサービスのバックアップを一元管理するサービスです。EC2、EBS、RDS、DynamoDB、EFSなど、幅広いサービスに対応しています。私が実装したバックアップ戦略では、日次バックアップと週次バックアップを組み合わせ、RPO(Recovery Point Objective)を1日以内に設定しました。LG Monitor モニター ディスプレイ 34SR63QA-W 34インチ 曲面 1800Rのような大画面モニターを使用すると、バックアップステータスとメトリクスを同時に表示でき、管理効率が向上します。定期的なリストアテストを実施することで、バックアップが実際に使用可能であることを確認することも重要です。ディザスタリカバリ計画を策定し、チーム全体で共有することが、緊急時の迅速な対応につながります。

まとめ
AWS運用におけるトラブルシューティングは、ログ分析、メトリクス監視、トレーシングの基礎から、ネットワーク障害、権限エラー、リソース不足、サービス障害への対応まで、多角的なアプローチが必要です。適切な調査手順と解決手法を身につけることで、障害対応時間が大幅に短縮され、サービスの安定性が向上します。CloudWatch、X-Ray、IAMポリシーシミュレーター、AWS Health Dashboardなど、AWSが提供する豊富なツールを活用することが、効率的なトラブルシューティングの鍵です。
私自身の経験から、トラブルシューティングスキルへの投資は必ず成果として返ってくることを実感しています。障害が発生する前に予防的な対策を講じることで、長期的には大きな時間節約とコスト削減につながります。本記事で紹介した手法を参考に、皆さんのプロジェクトでも効率的なAWS運用を実践してください。継続的な学習と改善を通じて、より安定したインフラ運用を追求していきましょう。チーム全体でトラブルシューティングのノウハウを共有し、高可用性なシステムを構築していきましょう。