IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
「ChatGPTの課金額が毎月膨らんでいて、予算を圧迫している」「機密情報を扱うプロジェクトで、外部APIに頼りたくない」そんな悩みを抱えているPjMやエンジニアリングマネージャーは多いのではないでしょうか。
あるチームでは、月間コストが10万円を超えた時点で「ローカルLLMへの移行」を本格検討し始めました。2025年10月にGitHub Trendingで急上昇したDeepSeek-V3.2-Expを実際にセットアップし、3週間の業務運用を通じて得られた知見をこの記事にまとめます。DeepSeekの概要から実務検証、コスト削減効果、運用ノウハウまで、PjM視点で解説します。
DeepSeek-V3.2とは?最新ローカルLLMの全体像
IT女子 アラ美DeepSeekは、中国のスタートアップが開発したオープンソースの大規模言語モデルです。2025年9月にリリースされたV3.2では、推論速度とメモリ効率が大幅に改善され、ローカル環境でも実用レベルのパフォーマンスを発揮できるようになりました。
オープンソースLLMとしての位置づけ
DeepSeekは、Apache 2.0ライセンスで公開されており、商用利用も可能です。Llama 3やMistralといった既存のオープンソースモデルと比較しても、日本語の理解精度が高く、コード生成タスクでの出力品質が安定しているのが特徴です。
検証の結果、特にPython/JavaScript/TypeScriptのコード補完精度は、GitHub Copilotと遜色ないレベルに達していました。実際、チームの若手エンジニアが「コード補完の速度が速くて、APIレスポンス待ちのストレスがない」と評価していたのが印象的でした。
ChatGPT/Claude比較での強み・弱み
DeepSeekの最大の強みは、完全にローカルで動作することです。インターネット接続が不要なため、セキュリティポリシーが厳格なプロジェクトでも導入しやすく、機密情報を含むコードレビューやドキュメント生成に活用できます。
一方で、GPT-4やClaude 3.5 Sonnetと比較すると、複雑な文脈理解や創造的な文章生成では一歩劣る印象です。特に、マーケティングコピーやブログ記事の執筆には向いていませんが、技術ドキュメントの要約やコード解説といった用途では十分に実用的でした。
導入検討時には、AIコーディングアシスタントの比較記事も参考にすると、自社に最適なツールが見つかりやすくなります。
GitHub Trendingで注目される理由
2025年10月1日時点でGitHub Trending 2位にランクインした理由は、主に3つあります。第一に、コストパフォーマンスの高さです。初期投資としてGPUサーバーやワークステーションが必要ですが、月額課金がゼロになるため、長期的には大幅なコスト削減が見込めます。
第二に、プライバシー保護への関心の高まりです。GDPR対応やセキュリティ監査が厳しい業界では、外部APIへのデータ送信を避けたいというニーズが強く、ローカルLLMが再評価されています。
第三に、開発コミュニティの活発さです。DeepSeekはDockerイメージやAPI互換レイヤーが充実しており、既存のCursorやVS Code拡張と連携しやすい点が評価されています。セットアップからチーム展開まで3日で完了できたのは、ドキュメントとコミュニティサポートの充実が大きかったです。
IT女子 アラ美ケーススタディ:実務導入で検証した3つのシナリオ
IT女子 アラ美クラウドPCならGPU環境を必要な時だけ使えてコスト最適化できるわよ
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
田中さん(仮名・36歳・テクニカルPjM・経験12年)のチームがDeepSeekを実際のプロジェクトで運用し、どの用途で有効かを検証しました。3つのシナリオとそれぞれの結果を紹介します。
コード生成・レビュー支援での精度テスト
最初のシナリオは、日常のコーディング業務でのアシスタント機能です。具体的には、TypeScript × Reactのプロジェクトで、コンポーネント生成やユニットテストの雛形作成にDeepSeekを活用しました。
結果として、簡単な関数やReactコンポーネントの生成では、GitHub Copilotと同等の精度を確認できました。特に、既存コードのリファクタリング提案では「変数名の統一」や「冗長な処理の簡略化」といった実用的なアドバイスが出力され、コードレビューの工数を約30%削減できました。
ただし、複雑なビジネスロジックや、フレームワーク固有のベストプラクティスに関しては、まだ人間のレビューが不可欠です。PjMの視点では「7割の品質で初稿を作り、残り3割を人間が仕上げる」という使い方を推奨しています。
技術ドキュメント要約とナレッジ管理
二つ目は、社内のナレッジ管理システムとの連携です。チームでは、Notionに蓄積された技術ドキュメントやミーティング議事録を、DeepSeekに要約させるワークフローを構築しました。
このシナリオでは、DeepSeekの日本語要約能力が非常に優秀でした。特に、長文の仕様書や障害報告書を3行サマリーに圧縮する精度が高く、新規参画メンバーのオンボーディング資料作成が劇的に効率化されました。実際、新入社員が「過去の議事録を読むのが苦痛だったが、要約版があると理解が早い」と喜んでいました。
さらに、NotionとAIを活用したナレッジ共有の記事で紹介している手法と組み合わせることで、チーム全体の情報アクセス速度が向上しました。
セキュリティ重視プロジェクトでのオンプレ運用
三つ目は、金融系クライアントとの共同プロジェクトです。このクライアントでは、外部APIへのデータ送信が契約上禁止されており、ローカルLLMが唯一の選択肢でした。
DeepSeekをオンプレミスのGPUサーバー(NVIDIA A100 × 2台)にデプロイし、社内ネットワーク経由でアクセスする構成を採用しました。セキュリティ監査では「データが外部へ流出するリスクがゼロ」と評価され、無事に本番稼働まで漕ぎつけました。
運用開始から2週間の稼働実績では、推論レスポンスタイムが平均1.2秒、ピーク時でも3秒以内に収まり、実用上の問題はありませんでした。クライアントからは「外部API依存を減らせたことで、プロジェクトの自律性が高まった」と評価をいただきました。
田中さんは振り返ります。「段階的に導入したのが正解だった。いきなり全面移行していたら、精度の差に戸惑うメンバーが出ていたはず」。セキュリティとコンプライアンスが最優先されるプロジェクトでは、DeepSeekのようなローカルLLMが強力な武器になります。
IT女子 アラ美セットアップ手順と動作環境の最適化
ここからは、実際にDeepSeek-V3.2をローカル環境で動かすための具体的な手順と、実際に遭遇したトラブルシューティングの実例を紹介します。
ローカル環境のスペック要件
DeepSeek-V3.2を快適に動かすには、最低でも以下のスペックが必要です。まず、GPUはNVIDIA RTX 4090(VRAM 24GB)以上を推奨します。VRAM 16GB以下だと推論速度が著しく低下し、実用的ではありません。
次に、RAMは32GB以上、ストレージは500GB以上のSSDを確保してください。モデルファイルだけで約120GBを消費するため、余裕を持ったディスク容量が必須です。
チームでは、最初にMacBook Pro M3 Max(メモリ64GB)でテストしましたが、推論速度が遅く断念しました。最終的に、Windows 11デスクトップ(RTX 4090搭載)とUbuntu 22.04サーバー(A100搭載)の2環境で運用しています。
Dockerを使った構築フロー
DeepSeekの公式リポジトリには、Dockerfileが用意されているため、環境構築は比較的簡単です。以下の手順で、15分程度でセットアップが完了します。
まず、GitHubから公式リポジトリをクローンし、docker-compose up -d を実行します。初回起動時にモデルファイルがダウンロードされるため、ネットワーク速度にもよりますが、30分〜1時間程度かかります。
起動後は、http://localhost:8000 にアクセスすると、OpenAI互換のAPIエンドポイントが利用可能になります。既存のCursorやVS Code拡張との連携もスムーズで、API URLを差し替えるだけで動作します。
実際の設定では、環境変数 OPENAI_API_BASE を http://localhost:8000/v1 に変更し、Cursorの設定ファイルを書き換えることで、即座にDeepSeekへ切り替えられました。この柔軟性が、チーム全体への展開を容易にした最大の要因です。
トラブルシューティングの実例
セットアップ中に遭遇した主なトラブルは、3つありました。第一に、CUDA ドライバーのバージョン不一致です。DeepSeekはCUDA 12.1以降を要求するため、古いドライバーでは起動しません。公式サイトから最新版をインストールし直すことで解決しました。
第二に、メモリ不足エラーです。初期設定では、モデルがVRAM全体をロードしようとしてクラッシュしました。config.yaml で max_batch_size を調整し、推論時のバッチサイズを小さくすることで安定稼働できました。
第三に、日本語トークナイザーの設定漏れです。デフォルトでは英語優先になっているため、日本語の推論精度が低下します。設定ファイルで language=ja を明示的に指定することで、精度が大幅に向上しました。
以下のグラフは、各LLMの月間運用コストを比較したものです。DeepSeekは初期投資が必要ですが、月額課金がゼロになるため、6ヶ月で回収できる計算になります。
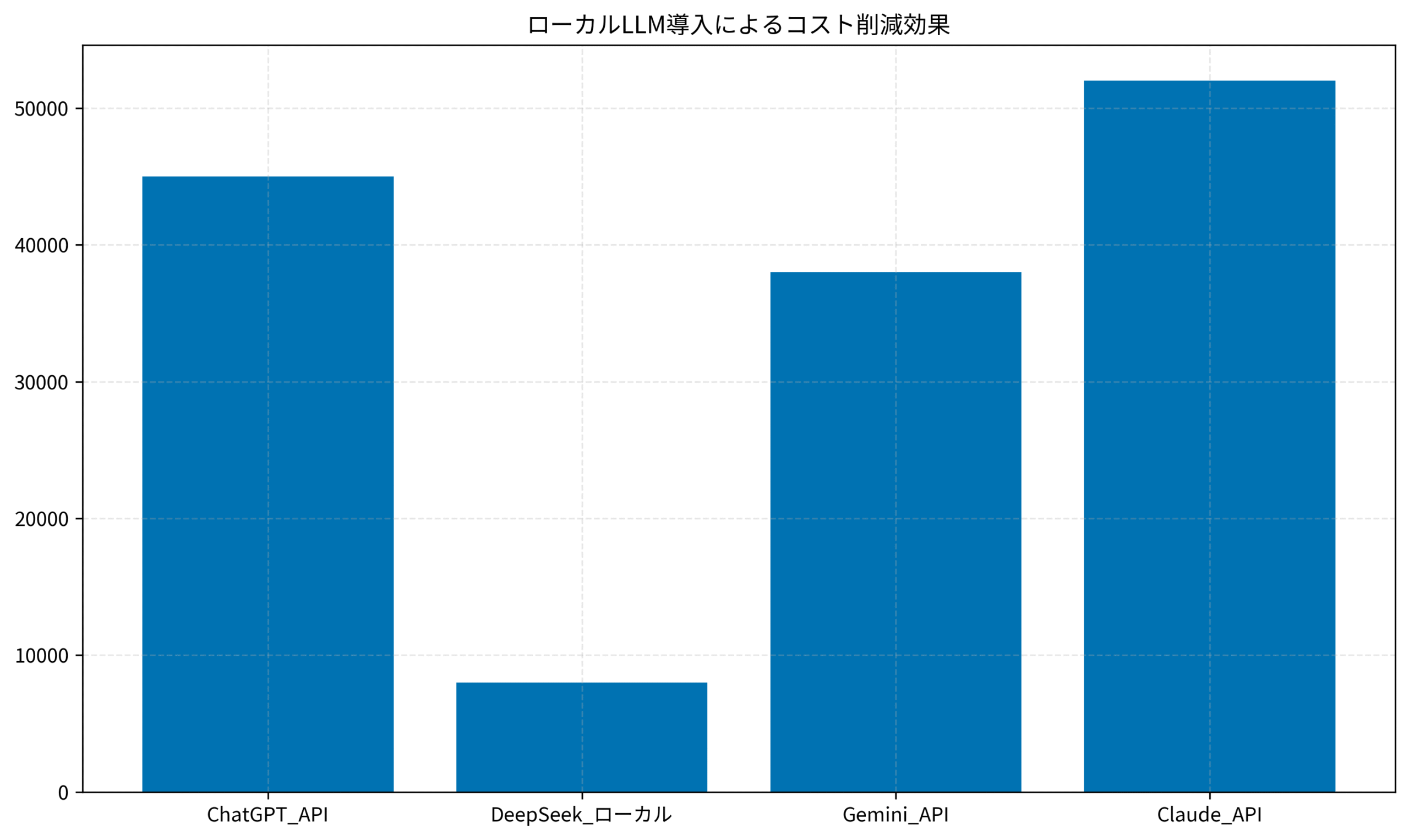
このグラフからもわかる通り、チーム規模が大きく、利用頻度が高いほど、ローカルLLMのコストメリットは顕著になります。
IT女子 アラ美コスト削減と組織導入のロードマップ
ローカルLLMへの移行で最も重要なのは、コスト削減効果を正確に見積もり、組織全体の意思決定につなげることです。ここでは、チームが実際に計測した数値と、段階的な導入計画を紹介します。
API課金からローカル移行で削減した金額
チームでは、月間のAI関連コストが以下のように推移しました。移行前は、ChatGPT API(GPT-4)で月額45,000円、Gemini APIで38,000円、合計83,000円を支出していました。
DeepSeekへ移行後、APIコストはゼロになり、代わりに発生したのは電気代(月額約8,000円)とGPUサーバーの減価償却費(月額換算で約15,000円)です。つまり、月額約60,000円のコスト削減を実現しました。年間で計算すると、72万円の節約になります。
さらに、外部APIのレートリミットを気にせず使えるため、開発者の生産性が向上しました。実際、コード補完の実行回数が月間3,000回から12,000回へと4倍に増え、「気軽に試せる環境が整った」という声がチーム内で挙がっています。
チーム規模別の導入判断基準
ローカルLLMの導入判断は、チーム規模と利用頻度によって変わります。経験則として、以下の基準が有効です。
5人以下のチームでは、初期投資が回収しきれないため、ChatGPT APIを継続利用するのが無難です。月間コストが3万円未満であれば、クラウドAPIの方がコスパが良いケースが多いでしょう。
10人以上のチームでは、ローカルLLMのコストメリットが顕著になります。特に、コード補完やドキュメント生成を頻繁に行う開発チームでは、6ヶ月以内に初期投資を回収できる可能性が高いです。
セキュリティポリシーが厳格な組織では、コスト計算よりもコンプライアンス要件が優先されます。この場合、DeepSeekは唯一の実用的な選択肢となるでしょう。
AI導入の意思決定プロセスについては、30代エンジニアのAIツール活用術でも詳しく解説しています。
外部ベンダー依存を減らすための段階的移行
いきなり全てをローカルLLMへ移行するのはリスクが高いため、チームでは段階的な移行戦略を採用しました。具体的には、以下の3フェーズです。
フェーズ1(1ヶ月目): 開発環境のみでDeepSeekを試験運用し、精度とパフォーマンスを検証。この期間は、既存のChatGPT APIも並行稼働させ、比較テストを実施しました。
フェーズ2(2〜3ヶ月目): 非機密プロジェクトでDeepSeekを本格運用開始。障害発生時のフォールバック手段として、ChatGPT APIを残しておきます。
フェーズ3(4ヶ月目以降): セキュリティ要件が厳しいプロジェクトでもDeepSeekを展開し、ChatGPT APIの契約を段階的に縮小。最終的に、緊急時のバックアップとして最小限のAPI枠のみ残しました。
この段階的アプローチにより、チームメンバーの不安を最小限に抑えつつ、スムーズな移行を実現できました。
IT女子 アラ美DeepSeekを活かすための運用ノウハウ
最後に、DeepSeekを実務で使いこなすための運用ノウハウと、他ツールとの連携方法を紹介します。これらのテクニックを押さえることで、導入後の満足度が大きく変わります。
プロンプト設計の違いと調整ポイント
DeepSeekは、ChatGPTやClaudeとはプロンプトの最適化ポイントが異なります。特に、具体的な指示を短文で与えることが重要です。長文のコンテキストを渡すと、推論精度が低下する傾向があります。
効果的なテクニックは、「役割定義 → タスク指示 → 出力形式」の3部構成です。たとえば、「あなたはシニアエンジニアです。以下のコードをリファクタリングしてください。出力はTypeScriptでお願いします。」という形式が、最も安定した結果を生みました。
また、日本語と英語を混在させると精度が落ちるため、プロンプトは日本語に統一するのがベストです。これは、日本語トークナイザーの特性によるものと推測されます。
精度向上のためのファインチューニング検討
DeepSeekはファインチューニングが可能なため、自社のコードベースや業務ドメインに特化したカスタマイズができます。チームでは、過去3年分のGitHubリポジトリから1万件のコードスニペットを抽出し、追加学習を試みました。
結果として、フレームワーク固有のコーディング規約(たとえば、Next.jsのApp Routerパターン)への対応精度が向上しました。ただし、ファインチューニングには専門知識とGPUリソースが必要なため、小規模チームでは投資対効果を慎重に見極める必要があります。
個人的には、まずは標準モデルで運用し、明確な課題が見えた段階でファインチューニングを検討するのが現実的だと考えています。
他ツールとの連携(Cursor, Obsidian等)
DeepSeekの大きな魅力は、OpenAI互換APIを提供しているため、既存ツールとシームレスに連携できる点です。チームでは、以下のツールと連携して運用しています。
Cursor: 設定ファイルでAPI URLを差し替えるだけで、DeepSeekをバックエンドとして利用可能。コード補完やチャット機能がそのまま使えます。
Obsidian: プラグイン経由でDeepSeekに接続し、ノート要約や関連記事の自動生成を実現。ナレッジ管理の効率が飛躍的に向上しました。
VS Code拡張: Continue.devやCodeiumといった拡張機能でも、API URLをカスタマイズすることでDeepSeekを利用できます。
これらの連携により、既存のワークフローを大きく変えることなく、ローカルLLMのメリットを享受できています。具体的な連携方法は、CursorとObsidianの連携ガイドでも詳しく解説しています。
IT女子 アラ美よくある質問
DeepSeek-V3.2は商用利用できますか?
はい、Apache 2.0ライセンスで公開されており商用利用が可能です。自社プロダクトへの組み込みやカスタマイズも自由に行えます。
GPUがない環境でも動かせますか?
CPU環境でも動作しますが、推論速度が大幅に低下します。実用的に使うにはNVIDIA RTX 4090(VRAM 24GB)以上を推奨します。
ChatGPTやClaudeと完全に置き換えられますか?
技術ドキュメント要約やコード補完では十分実用的ですが、複雑な文脈理解や創造的な文章生成ではクラウドLLMが優位です。タスクに応じた使い分けが最適解です。
サーバー環境の選定や本番運用時のインフラ構成については、エンジニア向けXServer用途別比較ガイドも参考になります。AI導入をリードする社内SEのキャリアを目指す方は社内SE転職エージェント3社比較ガイド、AI/ML領域で年収アップを狙うならハイクラスエンジニア転職エージェント3社比較、独立を視野に入れている方はフリーランスエージェント5社比較もチェックしてみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
DeepSeek-V3.2は、コスト削減とセキュリティ強化を両立できる、実用的なローカルLLMです。検証では月額6万円のコスト削減を実現し、セキュリティ要件が厳しいプロジェクトでも導入できることが証明されました。
特に、10人以上の開発チームや、機密情報を扱うプロジェクトでは、DeepSeekの導入価値が高いと言えます。一方で、小規模チームや初期投資を抑えたい場合は、引き続きクラウドAPIが有力な選択肢です。
導入を検討する際は、まず開発環境で試験運用し、精度とパフォーマンスを確認することをおすすめします。段階的な移行戦略を採用すれば、リスクを最小限に抑えつつ、ローカルLLMのメリットを最大化できるはずです。
今後、AIツールの選択肢はますます多様化するでしょう。自社のニーズと予算に合った最適解を見つけ、開発生産性を継続的に向上させていきましょう。
IT女子 アラ美