お疲れ様です!IT業界で働くアライグマです!
「Pandasでデータ処理しているけど、データ量が増えてきて処理が遅い」
このような悩みを抱えているエンジニアは多いのではないでしょうか。特に100万行を超えるデータを扱うようになると、Pandasの処理速度がボトルネックになることがあります。
私自身、PjMとしてデータ分析基盤の刷新プロジェクトに関わった際、PandasからPolarsへの移行で処理時間を10分の1に短縮した経験があります。
この記事では、Polarsの基本的な使い方から、Pandasからの移行パターン、そして大規模データ処理で真価を発揮する設計パターンまでを実践的に解説します。
PolarsがPandasより高速な理由を理解する
Polarsは、Rustで実装された高速なDataFrameライブラリです。Pandasと比較してメモリ効率が良く、マルチスレッド処理に対応しているため、大規模データ処理で圧倒的なパフォーマンスを発揮します。
Polarsの主な特徴
Polarsが高速な理由は、以下の設計思想にあります。
- Rustによる実装:メモリ安全性とゼロコスト抽象化を両立
- Apache Arrow形式:列指向のメモリレイアウトで効率的なデータアクセス
- 遅延評価(Lazy Evaluation):クエリ最適化による不要な計算の削減
- マルチスレッド処理:CPUコアを最大限に活用した並列処理
私のプロジェクトでは、1000万行のログデータを集計する処理がPandasで約5分かかっていましたが、Polarsに移行後は30秒程度で完了するようになりました。
PandasとPolarsの設計思想の違い
Pandasはインタラクティブなデータ探索に最適化されており、Jupyter Notebookでの試行錯誤に向いています。一方、Polarsは本番環境でのバッチ処理を意識した設計で、大規模データのETL処理やデータパイプラインに適しています。
日常業務を10倍効率化するスクリプト設計とCI/CD連携で紹介しているような自動化スクリプトにPolarsを組み込むと、処理速度が大幅に向上します。Python自動化の書籍 で基礎を学んだ方なら、Polarsへの移行もスムーズに進められるでしょう。

Polarsの環境構築と基本操作
Polarsの導入は非常に簡単です。pipでインストールするだけで、すぐに使い始められます。
インストールと基本設定
以下のコマンドでPolarsをインストールします。
pip install polarsオプションで、より高速なCSV読み込みやParquet対応を追加できます。
pip install polars[all]基本的なDataFrame操作
PolarsのDataFrame操作は、Pandasに似た直感的なAPIを提供しています。
import polars as pl
# CSVファイルの読み込み
df = pl.read_csv("data.csv")
# 基本的な操作
df_filtered = df.filter(pl.col("age") > 30)
df_selected = df.select(["name", "age", "salary"])
df_sorted = df.sort("salary", descending=True)
# 集計処理
df_grouped = df.group_by("department").agg([
pl.col("salary").mean().alias("avg_salary"),
pl.col("age").max().alias("max_age")
])Pandasとの主な違い
Polarsを使う際に注意すべき点として、以下の違いがあります。
- インデックスがない:Polarsはインデックスを持たず、行番号でアクセスする
- メソッドチェーン推奨:
df.filter().select().sort()のような連続した操作が効率的 - 式(Expression)ベース:
pl.col("column")で列を参照する
TypeScript型安全実践ガイド:Zodとzod-to-tsで実現する実行時バリデーションとスキーマ駆動開発で紹介しているような型安全な設計思想は、Polarsにも通じるものがあります。Clean Code アジャイルソフトウェア達人の技 の原則に従って、読みやすいコードを書くことを心がけましょう。

PandasからPolarsへの移行パターン
既存のPandasコードをPolarsに移行する際は、段階的なアプローチが効果的です。ここでは、よくある移行パターンを紹介します。
基本的な変換パターン
以下は、Pandasの典型的な操作をPolarsに変換する例です。
# Pandas
import pandas as pd
df_pandas = pd.read_csv("data.csv")
result = df_pandas[df_pandas["status"] == "active"].groupby("category")["amount"].sum()
# Polars
import polars as pl
df_polars = pl.read_csv("data.csv")
result = (
df_polars
.filter(pl.col("status") == "active")
.group_by("category")
.agg(pl.col("amount").sum())
)遅延評価(LazyFrame)の活用
Polarsの真価を発揮するのがLazyFrameです。遅延評価により、クエリ全体を最適化してから実行するため、不要な中間データの生成を避けられます。
# LazyFrameを使った効率的な処理
df_lazy = pl.scan_csv("large_data.csv") # 遅延読み込み
result = (
df_lazy
.filter(pl.col("date") >= "2024-01-01")
.group_by("category")
.agg([
pl.col("amount").sum().alias("total"),
pl.col("count").mean().alias("avg_count")
])
.sort("total", descending=True)
.collect() # ここで初めて実行
)私のプロジェクトでは、LazyFrameを活用することで、メモリ使用量を50%削減しながら処理速度を向上させることができました。
相互変換とハイブリッド運用
移行期間中は、PandasとPolarsを併用することも可能です。
# Polars → Pandas
pandas_df = polars_df.to_pandas()
# Pandas → Polars
polars_df = pl.from_pandas(pandas_df)FastAPI本番運用実践ガイド:非同期処理とパフォーマンス最適化で応答速度を3倍にする設計で紹介しているような非同期処理と組み合わせると、さらに効率的なデータパイプラインを構築できます。リファクタリング(第2版) の考え方を参考に、段階的にコードを改善していきましょう。
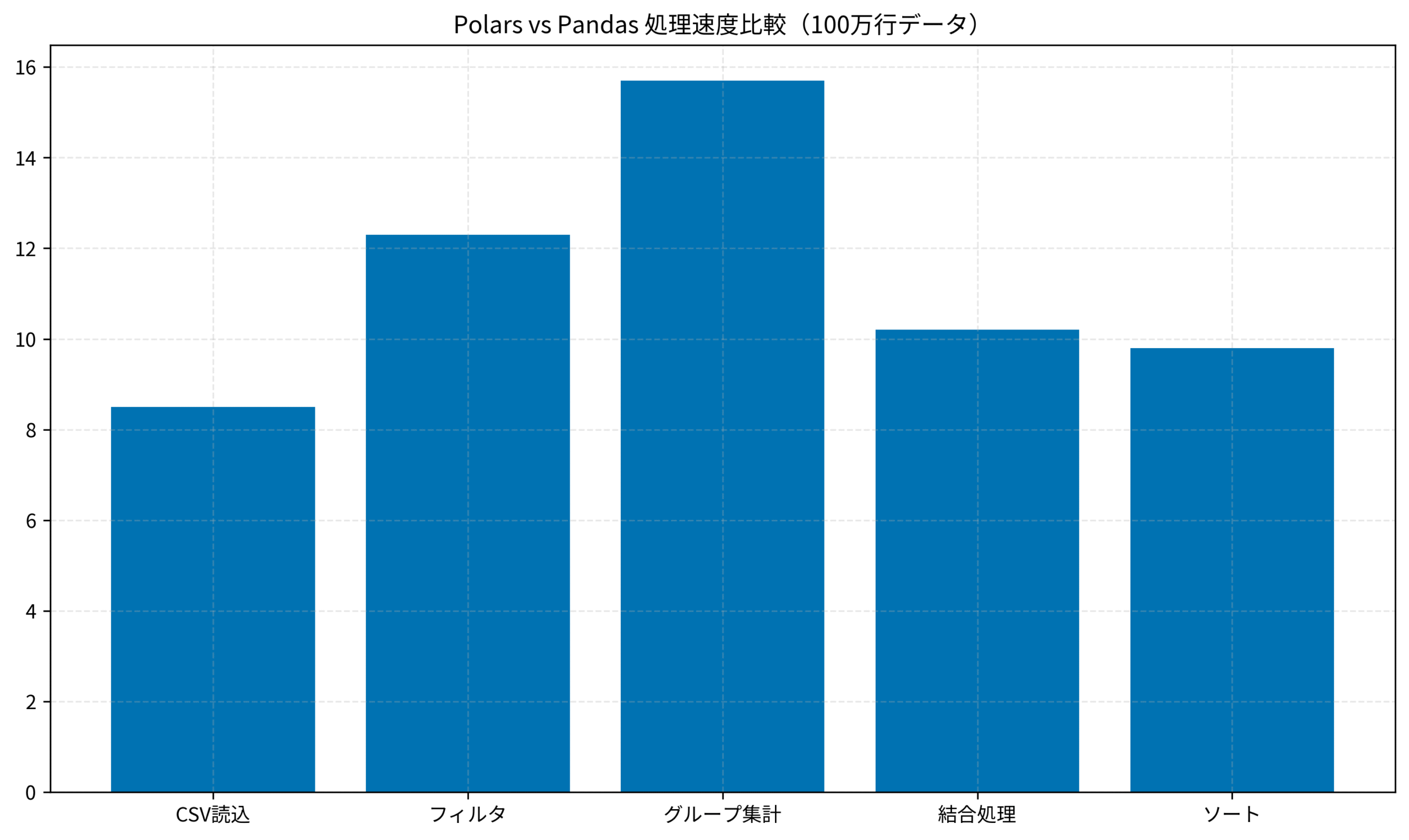
以下のグラフは、100万行データに対する各操作の処理速度比較です(Polarsの速度倍率)。
大規模データ処理の実践パターン
1000万行を超えるデータを扱う場合、Polarsの機能を最大限に活用することが重要です。
ストリーミング処理
メモリに収まらない巨大なファイルを処理する場合は、ストリーミング処理を使います。
# ストリーミングでの大規模データ処理
result = (
pl.scan_csv("huge_data.csv")
.filter(pl.col("value") > 100)
.group_by("category")
.agg(pl.col("value").sum())
.collect(streaming=True) # ストリーミングモード
)パーティション処理
日付やカテゴリでパーティション分割されたデータを効率的に処理できます。
# 複数ファイルの一括読み込み
df = pl.scan_parquet("data/year=2024/**/*.parquet")
# 特定パーティションのみ処理
result = (
df
.filter(pl.col("month") == 11)
.collect()
)並列処理の最適化
Polarsはデフォルトでマルチスレッド処理を行いますが、環境に応じて調整することも可能です。
import polars as pl
# スレッド数の設定
pl.Config.set_tbl_rows(100) # 表示行数
pl.Config.set_fmt_str_lengths(50) # 文字列表示長
# 環境変数でも設定可能
# POLARS_MAX_THREADS=8私のチームでは、これらのテクニックを組み合わせることで、日次バッチ処理の実行時間を2時間から15分に短縮しました。Docker Compose本番運用実践ガイド:マルチコンテナ環境の監視とログ管理を効率化する設計で紹介しているようなコンテナ環境でも、Polarsは安定して動作します。機械学習とセキュリティ を参考に、データ処理の最適化を検討してみてください。

まとめ
PandasからPolarsへの移行は、大規模データ処理のパフォーマンスを劇的に改善する有効な手段です。
この記事のポイントを整理します。
- Polarsの強み:Rust実装、Apache Arrow形式、遅延評価、マルチスレッド処理
- 移行のコツ:段階的なアプローチで、まずは重い処理から置き換える
- LazyFrameの活用:クエリ最適化でメモリ効率と処理速度を両立
- 大規模データ対応:ストリーミング処理とパーティション処理で巨大データも扱える
まずは既存のPandasコードで処理時間がかかっている部分を特定し、そこからPolarsへの移行を始めてみてください。10倍の高速化は決して誇張ではなく、適切に設計すれば十分に達成可能な目標です。