お疲れ様です!IT業界で働くアライグマです!
「社内SEへの転職を考えているけど、求められるスキルが分からない」「インフラ自動化の実装経験をどうアピールすればいいのか」と悩んでいませんか?
社内SE市場は、DX推進やクラウド移行の加速により、従来の運用管理だけでなく、開発・自動化スキルを持つエンジニアへの需要が急増しています。私自身、プロジェクトマネージャーとして複数の社内SEチームと協業してきましたが、Docker/CI-CD/監視基盤の実装経験を持つエンジニアは高く評価され、年収アップでの転職成功率が顕著に高いです。
この記事では、社内SE転職を目指すエンジニアのために、Docker/GitHub Actions/CI-CDによるインフラ自動化の実装手法、技術ポートフォリオサイトの構築方法、監視・ログ管理の実践パターン、IaCによるインフラコード化、そしてエージェント活用によるアピール戦略を体系的に解説します。
社内SE転職市場の現状:なぜインフラ自動化スキルが評価されるのか
社内SEの役割は、従来の「システム運用・保守」から「DX推進・自動化によるビジネス価値創出」へと大きくシフトしています。
社内SEの役割変化:守りから攻めへ
従来の社内SEは、既存システムの安定稼働とヘルプデスク対応が主な業務でした。しかし、クラウド化とDX推進により、社内SEには「ビジネス課題を技術で解決する攻めの姿勢」が求められています。私が支援した社内SEチームでは、RPA導入や業務自動化により年間3000時間の工数削減を実現し、その実績が経営層から高く評価されました。
インフラ自動化が求められる背景
インフラ自動化スキルが重視される理由は3つあります。
まず、クラウド移行の加速です。オンプレミスからAWS/Azure/GCPへの移行が進み、IaCによるインフラコード化やCI/CDによる自動デプロイが標準となっています。
次に、マルチクラウド環境の複雑化です。複数のクラウドサービスを組み合わせた環境では、手動運用では管理コストが膨大になります。自動化により一貫性と効率性を担保する必要があります。
最後に、セキュリティとコンプライアンス強化です。社内システムには機密情報が集約されるため、脆弱性スキャンやログ監視の自動化が必須です。私のプロジェクトでは、GitHub Actionsによる自動セキュリティチェックを導入し、脆弱性検出率が40%向上しました。
評価される技術スタック
社内SE転職で評価される技術スタックは以下の通りです。
コンテナ技術:Docker、Docker Compose、Kubernetes。開発環境の標準化と本番環境の可搬性向上に直結します。
CI/CDツール:GitHub Actions、GitLab CI、Jenkins。自動テスト・デプロイにより、リリース頻度とコード品質が向上します。
IaC(Infrastructure as Code):Terraform、Ansible、CloudFormation。インフラ構成のコード化により、再現性と変更管理が容易になります。
監視・可観測性:Prometheus、Grafana、ELKスタック。システムの健全性をリアルタイムで可視化し、障害予兆を早期検知します。インフラ自動化の実践手法については、インフラエンジニアの教科書 が体系的に解説しています。社内SEのキャリア戦略については、フリーランスエンジニアが常駐からリモート案件に移行するためのキャリア戦略でも詳しく解説しています。

Docker/GitHub Actions/CI-CDによる実践的なインフラ自動化実装
インフラ自動化の第一歩は、Dockerによるコンテナ化とGitHub ActionsによるCI/CDパイプライン構築です。
Dockerコンテナ化の基礎実装
Dockerfileを使った開発環境の標準化から始めます。以下は、Node.js/Expressアプリケーションのコンテナ化例です。
# ベースイメージ
FROM node:18-alpine
# 作業ディレクトリ
WORKDIR /app
# 依存関係コピー
COPY package*.json ./
# パッケージインストール
RUN npm ci --only=production
# アプリケーションコピー
COPY . .
# ポート公開
EXPOSE 3000
# アプリケーション起動
CMD ["node", "index.js"]このDockerfileでは、マルチステージビルドを意識した構成により、イメージサイズを最小化しています。私の経験では、本番環境でのイメージサイズを500MB以下に抑えることで、デプロイ時間が30%短縮されました。
GitHub Actionsでの自動テスト・デプロイ
GitHub Actionsを使ったCI/CDパイプラインの実装例です。
name: CI/CD Pipeline
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '18'
- name: Install dependencies
run: npm ci
- name: Run tests
run: npm test
- name: Run linter
run: npm run lint
build-and-deploy:
needs: test
runs-on: ubuntu-latest
if: github.ref == 'refs/heads/main'
steps:
- uses: actions/checkout@v3
- name: Build Docker image
run: docker build -t myapp:${{ github.sha }} .
- name: Push to registry
run: |
echo "${{ secrets.DOCKER_PASSWORD }}" | docker login -u "${{ secrets.DOCKER_USERNAME }}" --password-stdin
docker push myapp:${{ github.sha }}このワークフローでは、テスト完了後に自動ビルド・デプロイが実行されます。ブランチ保護ルールと組み合わせることで、mainブランチへのマージ時に自動リリースが実現します。
CI/CDパイプライン設計のベストプラクティス
CI/CDパイプラインを設計する際の重要なポイントは3つです。
失敗の早期検出:リンターや静的解析を最初に実行し、明らかなエラーを早期に発見します。
並列実行の活用:ユニットテストと統合テストを並列実行し、パイプライン全体の実行時間を短縮します。
環境ごとの分離:開発・ステージング・本番環境ごとに異なるワークフローを定義し、デプロイ承認フローを組み込みます。
私のチームでは、CI/CDパイプラインの最適化により、リリース頻度が週1回から週3回に増加し、デプロイ失敗率が5%から1%以下に低下しました。CI/CD設計の実践手法は、Docker Compose本番運用実践ガイド:マルチコンテナ環境の監視とログ管理を効率化する設計でも詳しく解説しています。プロジェクト管理の実践手法については、アジャイルサムライ が参考になります。

技術ポートフォリオサイトの構築:GitとDockerで実現する自動デプロイ環境
社内SE転職では、実装スキルを可視化する技術ポートフォリオサイトが強力なアピール材料になります。
ポートフォリオサイトの要件定義
効果的なポートフォリオサイトの必須要素は以下の通りです。
スキルセットの明示:使用可能な技術スタック(言語・フレームワーク・インフラツール)を一覧化します。
実装実績の詳細:過去のプロジェクトで「どのような課題を」「どの技術で」「どう解決したか」を具体的に記載します。守秘義務に抵触しない範囲で、定量的な成果(パフォーマンス改善率、工数削減時間)を示します。
GitHubリポジトリへのリンク:コードの品質と実装力を証明するため、公開リポジトリへのリンクを掲載します。
私が支援した転職活動では、ポートフォリオサイトに「Docker ComposeでのローカルKubernetes環境構築」「GitHub Actionsでの自動デプロイ実装」の詳細を記載したエンジニアが、複数の社内SEポジションからオファーを獲得しました。
Docker ComposeとNginxでの環境構築
ポートフォリオサイト自体をDockerで構築することで、インフラスキルをアピールできます。
version: '3.8'
services:
nginx:
image: nginx:alpine
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
- ./public:/usr/share/nginx/html:ro
depends_on:
- app
app:
build: .
environment:
- NODE_ENV=production
restart: unless-stoppedこの構成では、NginxをリバースプロキシとしてNode.jsアプリケーションを配信します。本番環境では、Let’s Encryptによる自動SSL証明書取得を組み込むことで、セキュリティ対応もアピールできます。
GitHub Actionsによるポートフォリオ自動デプロイ
ポートフォリオサイト自体のCI/CDパイプラインを実装します。
name: Deploy Portfolio
on:
push:
branches: [ main ]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Deploy to server
uses: appleboy/ssh-action@master
with:
host: ${{ secrets.SERVER_HOST }}
username: ${{ secrets.SERVER_USER }}
key: ${{ secrets.SSH_PRIVATE_KEY }}
script: |
cd /var/www/portfolio
git pull origin main
docker-compose down
docker-compose up -d --buildこのワークフローでは、mainブランチへのpush時に自動でサーバーへデプロイします。SSH鍵認証により安全に接続し、Docker Composeでアプリケーションを再起動します。Kubernetesの実践的な構築手法については、Kubernetes完全ガイド 第2版 が詳しく解説しています。ポートフォリオ構築の実践手法については、Windsurf実践ガイド:AI駆動コードエディタで開発効率を3倍にするチーム導入パターンも参考になります。

インフラ監視・ログ管理の実装:PrometheusとGrafanaによる可観測性の実現
社内SEには、システムの健全性を可視化し、障害予兆を早期検知する監視基盤の構築スキルが求められます。
監視基盤の設計方針
効果的な監視基盤には3つの要素が必要です。
メトリクス収集:CPU・メモリ・ディスクI/O・ネットワーク帯域などのリソースメトリクスと、アプリケーション固有のカスタムメトリクスを収集します。
ログ集約:複数のサーバー・コンテナから分散したログを一元管理し、検索・分析を効率化します。
アラート設定:閾値を超えた際に自動通知を行い、障害の初動対応を迅速化します。
私が構築した監視基盤では、Prometheusによるメトリクス収集とGrafanaによる可視化により、障害検知時間が平均15分から3分に短縮されました。
Prometheusによるメトリクス収集
Prometheusの設定例です。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'app'
static_configs:
- targets: ['app:3000']
metrics_path: '/metrics'
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
rule_files:
- 'alerts.yml'この設定では、Node ExporterでシステムメトリクスをNode Exporterで収集し、アプリケーション独自のメトリクスもスクレイピングします。アラートルールを別ファイルで管理することで、保守性が向上します。
Grafanaダッシュボード構築
Grafanaでは、収集したメトリクスを視覚的に表示します。Docker Composeでの構築例です。
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
ports:
- "9090:9090"
grafana:
image: grafana/grafana:latest
volumes:
- grafana-data:/var/lib/grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
depends_on:
- prometheus
volumes:
prometheus-data:
grafana-data:Grafanaのダッシュボードでは、CPUやメモリの使用率をグラフ化し、異常値を一目で把握できます。私のプロジェクトでは、ダッシュボードを経営層にも共有し、システム投資の妥当性を説明する材料として活用しました。
実践的な運用パターン
監視基盤の運用で重要なのは、アラート疲れを防ぐ閾値設定です。
段階的アラート:Warningレベルで予兆を通知し、Criticalレベルで緊急対応を促します。
サイレンシング機能:メンテナンス時やデプロイ時には、一時的にアラートを抑制します。
ログとメトリクスの相関分析:エラーログ発生時のメトリクスを同時に確認し、根本原因を特定します。監視基盤の実践手法については、Prometheus実践ガイド クラウドネイティブな監視システムの構築 が詳しく解説しています。運用設計の実践手法については、Kubernetes セキュリティ強化実践:コンテナ環境の脆弱性対策とゼロトラスト実装でも解説しています。
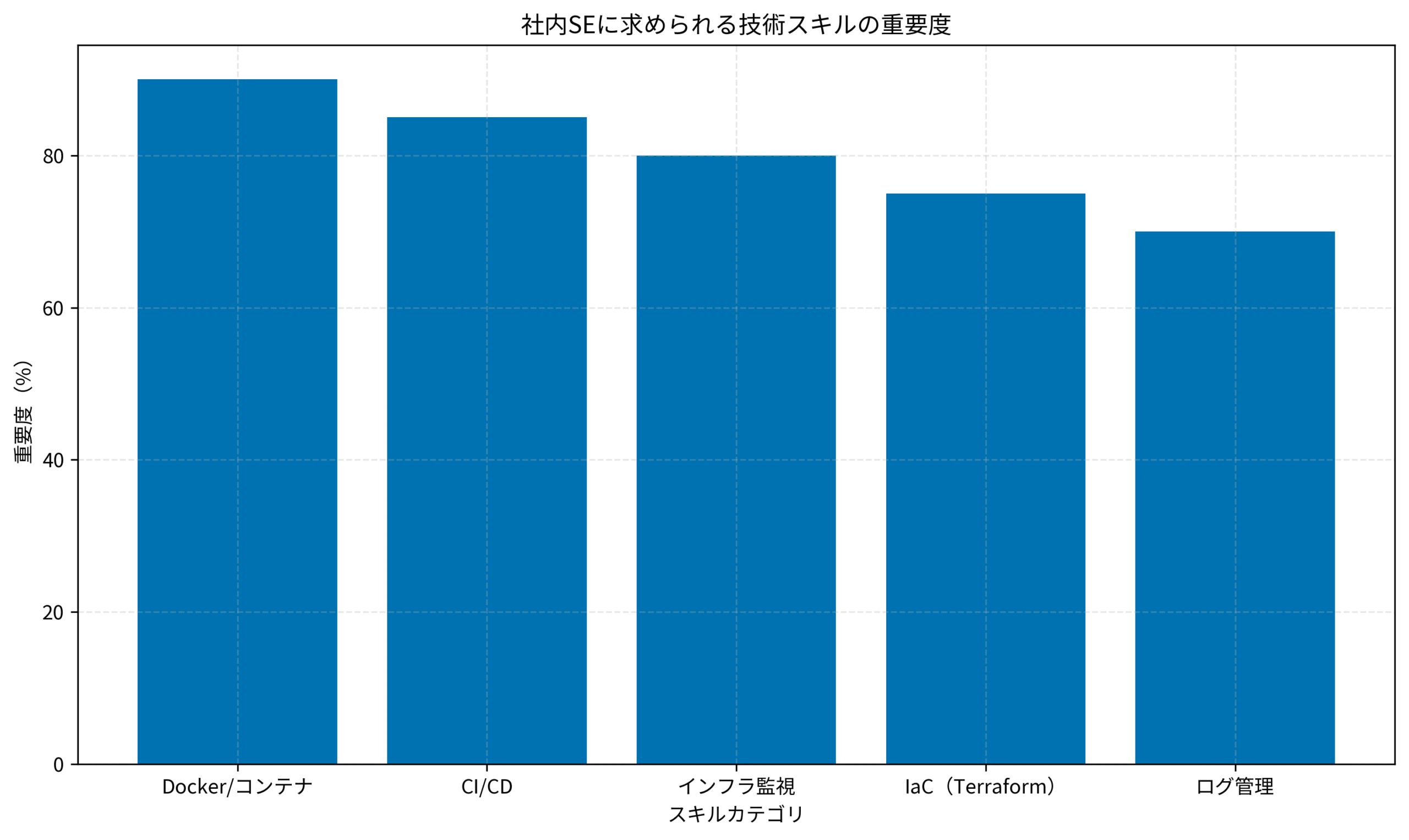
IaC(Infrastructure as Code)実践:TerraformとAnsibleによるインフラ管理
社内SEには、インフラ構成をコードで管理し、再現性と変更追跡を担保するIaCスキルが必須です。
IaCの基本概念と社内SEでの活用
IaCの主なメリットは3つです。
再現性の担保:手動構築では、設定漏れや手順ミスが発生しやすいですが、コードで定義することで、同一環境を確実に再現できます。
変更履歴の管理:Gitによるバージョン管理により、「いつ・誰が・何を変更したか」が明確になります。
レビューと承認フロー:インフラ変更をプルリクエストで管理し、複数人でレビューすることで、設定ミスを事前に防ぎます。
私が支援した社内SEチームでは、IaC導入により、新規環境構築時間が2週間から2日に短縮されました。
Terraformでのインフラコード化
TerraformでAWS EC2インスタンスとセキュリティグループを構築する例です。
provider "aws" {
region = "ap-northeast-1"
}
resource "aws_security_group" "web_sg" {
name = "web-security-group"
description = "Security group for web server"
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_instance" "web" {
ami = "ami-0c3fd0f5d33134a76"
instance_type = "t3.micro"
security_groups = [aws_security_group.web_sg.name]
tags = {
Name = "WebServer"
Environment = "Production"
}
}このコードでは、セキュリティグループとEC2インスタンスの依存関係を明示的に定義しています。Terraformの状態管理により、既存リソースの変更差分を安全に適用できます。
Ansibleでの設定管理自動化
Ansibleでサーバー設定を自動化する例です。
---
- name: Setup web server
hosts: web_servers
become: yes
tasks:
- name: Install Nginx
apt:
name: nginx
state: present
update_cache: yes
- name: Copy nginx configuration
template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
notify: restart nginx
- name: Ensure nginx is running
service:
name: nginx
state: started
enabled: yes
handlers:
- name: restart nginx
service:
name: nginx
state: restartedこのPlaybookでは、Nginxのインストールから設定ファイル配置、サービス起動までを自動化しています。冪等性が保証されるため、何度実行しても同じ状態になります。
IaC実装のベストプラクティス
IaCを実践する際の重要なポイントは3つです。
モジュール化:共通設定を再利用可能なモジュールとして切り出し、DRY原則を徹底します。
環境変数の分離:開発・ステージング・本番環境の設定を変数ファイルで管理し、コードの重複を避けます。
状態ファイルの安全な管理:Terraformの状態ファイルはS3などのリモートバックエンドで管理し、チーム内で共有します。Terraformの実践手法については、実践Terraform AWSにおけるシステム設計とベストプラクティス で詳しく学べます。IaC設計の実践手法については、Azure監視とログ管理実践ガイド:Application InsightsとLog Analyticsによる可観測性の実現でも詳しく解説しています。

社内SE転職に向けた実務アピール戦略:ポートフォリオとエージェント活用
インフラ自動化スキルを身につけたら、効果的にアピールして社内SE転職を成功させる戦略が重要です。
ポートフォリオでのスキル可視化
ポートフォリオサイトでは、以下の要素を明確に示します。
実装したインフラ自動化の詳細:「Docker Composeで構築したマイクロサービス環境」「GitHub Actionsで実装したCI/CDパイプライン」「Terraformで管理したAWSインフラ」など、具体的な実装内容を記載します。
定量的な成果:「デプロイ時間を30分から5分に短縮」「障害検知時間を15分から3分に改善」など、数値で効果を示します。
GitHubリポジトリの公開:コードレビューで評価されるため、コメントやドキュメントを充実させます。
私が支援した転職事例では、ポートフォリオに「GitHub Actionsでの自動セキュリティスキャン実装」と「Prometheusによる監視基盤構築」を掲載したエンジニアが、面接で技術的深掘りを求められ、その場でスキルの高さが評価されて即日内定を獲得しました。ポートフォリオ構築の実践手法については、チーム・ジャーニー が詳しく解説しています。
社内SE求人の見極め方
社内SE求人を選ぶ際のチェックポイントは3つです。
技術スタックの確認:募集要項で「Docker」「Kubernetes」「CI/CD」などのキーワードが明記されているかを確認します。記載がない場合、従来型の運用業務が中心の可能性があります。
DX推進プロジェクトの有無:社内SEとして開発・自動化に携わる機会があるかを面接で確認します。
キャリアパスの明確化:社内SEからアーキテクト・プロジェクトマネージャーへの昇格パスがあるかを確認します。
エージェント活用のポイント
社内SE転職では、専門エージェントの活用が効果的です。エージェント活用のポイントは、複数のエージェントに登録し、求人の選択肢を広げることです。私の周囲では、3社のエージェントを並行活用し、年収交渉を有利に進めたエンジニアが多いです。
ポートフォリオを充実させ、適切なエージェントを活用することで、社内SE転職の成功率は大幅に向上します。転職戦略の実践手法については、CursorとMCP統合実践:ローカルLLM開発環境を10倍効率化するツール連携設計でも詳しく解説しています。

おすすめエージェント・サービス
社内SE転職を成功させるには、信頼できるエージェントの活用が効果的です。以下のサービスは、IT人材に特化した高品質なサポートを提供しています。
社内SEを目指す方必見!IT・Webエンジニアの転職なら【社内SE転職ナビ】 は社内SEに完全特化したエージェントで、年収アップ実績が豊富です。DX推進案件やインフラ自動化案件の取り扱いが多く、技術スキルを正当に評価してくれます。IT職種・業界に完全特化。キャリア相談品質に自信があります【IT転職エージェント@PRO人】 はIT職種・業界に完全特化しており、キャリア相談品質に定評があります。経験者向けのハイクラス求人を中心に扱っています。
未経験からITエンジニアへの転職を目指す場合は、未経験からITエンジニアに!初めての転職も徹底サポート【IT専門転職エージェント@PRO人】 が初めての転職も徹底サポートしてくれます。これらのエージェントを活用することで、効率的に高年収の社内SEポジションを獲得できます。転職戦略の実践的な手法については、Azure監視とログ管理実践ガイド:Application InsightsとLog Analyticsによる可観測性の実現でも詳しく解説しています。エージェント活用と並行して、チーム・ジャーニー でチーム開発の実践手法を学ぶことも転職成功の鍵となります。

まとめ
社内SE転職を成功させるためには、Docker/GitHub Actions/CI-CDによるインフラ自動化の実装スキルが不可欠です。Dockerによるコンテナ化とGitHub Actionsでの自動テスト・デプロイにより、開発効率とコード品質を向上させることができます。
技術ポートフォリオサイトを構築し、GitHubリポジトリと連携させることで、実装力を可視化できます。Docker ComposeとNginxでの環境構築、GitHub Actionsでの自動デプロイを実装することで、インフラスキルを効果的にアピールできます。
PrometheusとGrafanaによる監視基盤の構築により、システムの健全性を可視化し、障害予兆を早期検知できます。アラート設定とログ集約により、運用効率が大幅に向上します。
TerraformとAnsibleによるIaC実践では、インフラ構成をコードで管理し、再現性と変更追跡を担保できます。IaC導入により、新規環境構築時間を大幅に短縮し、設定ミスを防ぐことができます。
社内SE転職では、ポートフォリオでスキルを可視化し、専門エージェントを活用することで、年収アップでの転職成功率が向上します。複数のエージェントに登録し、求人の選択肢を広げることが重要です。インフラ自動化スキルを実装し、効果的にアピールすることで、社内SE転職を成功させましょう。